A system for creating reversible data transformations

Project description
wtrwrks
TLDR
Install:
pip install wtrwrks
Build waterwork:
from wtrwrks import Waterwork, add, mul
import pprint
with Waterwork() as ww:
add_tubes, add_slots = add([1., 2., 3.], [3., 4., 5.])
mul_tubes, mul_slots = mul(add_tubes['target'], [2., 2., 2.])
taps = ww.pour(key_type='str')
pprint.pprint(taps)
Build dataset transform:
from wtrwrks import DatasetTransform, CatTransform, NumTransform
import numpy as np
import pprint
import tensorflow as tf
# Define the raw input array
array = np.array([
['a', 1, 0],
['b', 4, np.nan],
['c', 8, np.nan],
['a', 11, np.nan],
], dtype=np.object)
# Define the full dataset transform
dataset_transform = DatasetTransform(name='DT')
# Add the categorical transform. Have it taken in column 0 from 'array'.
# Normalize by (val - mean)/std.
dataset_transform.add_transform(
cols=[0],
transform=CatTransform(
name='CAT',
norm_mode='mean_std',
index_to_cat_val=['a', 'b', 'c', 'd'],
input_dtype=np.dtype('U')
)
)
# Add the numerical transform. Have it take columsn, 1 and 2 from 'array'.
# Normalize by (val - min)/(max - min). Replace nans with zeros.
dataset_transform.add_transform(
cols=[1, 2],
transform=NumTransform(
name='NUM',
norm_mode='min_max',
input_dtype=np.float64,
fill_nan_func=lambda a: np.array(0),
)
)
# Calculate means, stds, mins, maxes, etc.
dataset_transform.calc_global_values(array)
outputs = dataset_transform.pour(array)
# Either reconstruct the original array from this
dataset_transform.pump(outputs)
# Or write directly to tfrecords
dataset_transform.write_examples(array, file_name='examples.tfrecord')
# Then read them and use them in an ML pipeline
dataset_iter = dataset_transform.get_dataset_iter(
'examples_*.tfrecord', batch_size=2
)
dataset_init = dataset_transform.get_dataset_iter_init(
dataset_iter,
'examples_*.tfrecord',
num_epochs=1,
shuffle_buffer_size=1, # i.e. don't shuffle
batch_size=2,
)
features = dataset_iter.get_next()
with tf.Session() as sess:
sess.run(dataset_init)
example_dicts = []
for _ in xrange(2):
evaled_features = sess.run(features)
# Do whatever you need to do with the outputs
# ...
# Reconstruct the orignal array
example_dict = {}
for key in evaled_features:
example_dict[key] = evaled_features[key].flatten()
example_dicts.append(example_dict)
tap_dict = dataset_transform.examples_to_tap_dict(example_dicts)
remade_array = dataset_transform.pump(tap_dict)
print remade_array
Waterworks and Transforms
When starting a new project, a data scientist or machine learning engineer spends a large portion, if not a majority of their time preparing the data for input into some ML algorithm. This involves cleaning, transforming and normalizing a variety of different data types so that they can all be represented as some set of well behaved vectors (or more generally some higher dimensional tensor). These transformations are usually quite lossy since much of the information contained in the raw data is unhelpful for prediction. This, however, has the unfortunate side effect that it makes it impossible to reconstruct the original raw data from its transformed counterpart, which is a helpful if not necessary ability in many situations.
Being able to look at the data in it's original form rather than a large block of numbers makes debugging process smoother and the model diagnosing more intuitive. That was the original motivation for creating this package but this system can be used in a wide variety of situations outsie of ML pipelines and was set up in as general purpose of a way as possible. That being said, there is submodule called 'Transforms' which is build on top of the waterworks system that is specifically for ML pipelines. These transforms convert categorical, numerical, datetime and string datatype into vectorized inputs for ML pipelines. This is discussed further below
Waterworks
'Theory' of Waterworks
Creating a 'waterwork' amounts to creating a reversible function, i.e. a function f such that for any a ∈ dom(f) you have an f-1 such that f-1(f(a)) = a. Note that this does not imply that this same function f will satisfy f(f-1(b)) = b, for any b since f need only be injective not isomorphic. Waterworks are built from smaller reversible operations (called tanks) and are attached together to get more complex operations. Anyone who has built anything using tensorflow will quickly see where the idea for this method of defining waterworks came from. A waterwork is a directed acyclic graph describing a series of operations to perform. The nodes of this graph are the tanks (i.e. operations) and the edges are the tubes/slots. The tanks are themselves reversible, and thus the entire waterwork is reversible.
As the reader is quickly finding out, there is a fair amount of made up jargon that the author found difficult to avoid. But hopefully the metaphor makes it a little bit easier to digest. Reference this diagram for a more intuitive picture of what is going on.
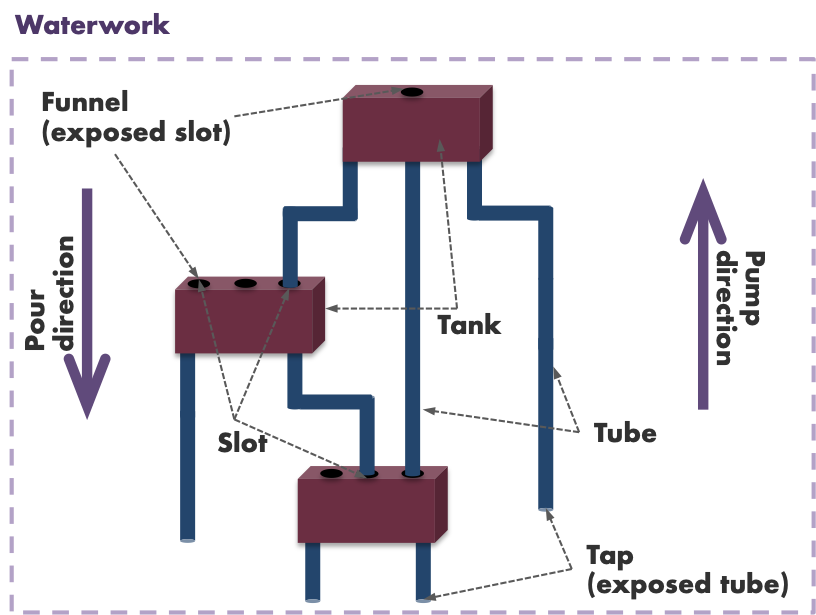
Basically, you build a waterwork by connecting tanks together by fitting tubes into slots. The end result it a collection of connected tanks with some slots and tubes left unconnected. These are the inputs and outputs of the function (waterwork) and are known as funnels and taps respectively.
Examples
Example 1
As a concrete example, take the function f(a, b, c) = (a + b) * c. Let's imagine we wanted to build a waterwork that simulates this function. Because addition and multiplication are both actually quite lossy, there is a fair amount of additional information that you need to carry around in order to reconstruct a, b, and c later on. Both addition and multiplication store either the first (slot 'a') or second (slot 'b') input, depending on whichever has a fewer number of elemements. One can see this full process in action by running the code:
from wtrwrks import Waterwork, add, mul
import pprint
with Waterwork() as ww:
add_tubes, add_slots = add([1., 2., 3.], [3., 4., 5.])
mul_tubes, mul_slots = mul(add_tubes['target'], [2., 2., 2.])
taps = ww.pour(key_type='str')
pprint.pprint(taps)
{'Add_0/tubes/a_is_smaller': False,
'Add_0/tubes/smaller_size_array': array([3., 4., 5.]),
'Mul_0/tubes/a_is_smaller': False,
'Mul_0/tubes/missing_vals': array([], dtype=float64),
'Mul_0/tubes/smaller_size_array': array([2., 2., 2.]),
'Mul_0/tubes/target': array([ 8., 12., 16.])}
Normally, when one wants to do to run (a + b) * c, you get a single output. However, in order to make this reversible, a 6 different outputs are returned. However, with these outputs one is able to completely undo the (a + b) * c operation, even in the presence of zeros, to get back the original a, b and c.
The taps, are all the tubes from all the tanks that were not connected to some other slot. Hence, 'add_tubes["target"]', does not appear as a tap since it was connected to the mul_slots['a'].
Example 2
In the previous example, all funnels were given values at the start, so there were no additional values needed to supply to the pour method. In fact, when all the values are filled at the start, the waterwork is actually eagerly executed:
from wtrwrks import Waterwork, add, mul
import pprint
with Waterwork() as ww:
add_tubes, add_slots = add([1.0, 2.0, 3.0], [3.0, 4.0, 5.0])
print add_tubes['target'].get_val()
[4. 6. 8.]
However, similar to tensorflow, this system was not really principally designed to run eargerly, but instead to run the same set of computations over and over again with different inputs. So, when defining the waterwork it's not really necessary to supply all values for all the slots at definition. The 'empty' object can be passed to the tank instead, then the values of the funnels can be passed when the actual pour method is run:
from wtrwrks import Waterwork, add, mul, empty
import pprint
with Waterwork() as ww:
add_tubes, add_slots = add([1.0, 2.0, 3.0], b=empty)
div_tubes, div_slots = mul(add_tubes['target'], [2.0, 2.0, 2.0])
taps = ww.pour({'Add_0/slots/b': [3., 4., 5.]}, key_type='str')
pprint.pprint(taps)
taps = ww.pour({'Add_0/slots/b': [5., 6., 7.]}, key_type='str')
pprint.pprint(taps)
{'Add_0/tubes/a_is_smaller': False,
'Add_0/tubes/smaller_size_array': array([3., 4., 5.]),
'Mul_0/tubes/a_is_smaller': False,
'Mul_0/tubes/missing_vals': array([], dtype=float64),
'Mul_0/tubes/smaller_size_array': array([2., 2., 2.]),
'Mul_0/tubes/target': array([ 8., 12., 16.])}
{'Add_0/tubes/a_is_smaller': False,
'Add_0/tubes/smaller_size_array': array([5., 6., 7.]),
'Mul_0/tubes/a_is_smaller': False,
'Mul_0/tubes/missing_vals': array([], dtype=float64),
'Mul_0/tubes/smaller_size_array': array([2., 2., 2.]),
'Mul_0/tubes/target': array([12., 16., 20.])}
Putting this into the pump function one can get back the funnel value 'b' from the 'add' tank:
funnels = ww.pump(
{'Add_0/tubes/a_is_smaller': False,
'Add_0/tubes/smaller_size_array': np.array([3., 4., 5.]),
'Mul_0/tubes/a_is_smaller': False,
'Mul_0/tubes/missing_vals': np.array([], dtype=np.float64),
'Mul_0/tubes/smaller_size_array': np.array([2., 2., 2.]),
'Mul_0/tubes/target': np.array([8., 12., 16.])},
key_type='str'
)
pprint.pprint(funnels)
funnels = ww.pump(
{'Add_0/tubes/a_is_smaller': False,
'Add_0/tubes/smaller_size_array': np.array([5., 6., 7.]),
'Mul_0/tubes/a_is_smaller': False,
'Mul_0/tubes/missing_vals': np.array([], dtype=np.float64),
'Mul_0/tubes/smaller_size_array': np.array([2., 2., 2.]),
'Mul_0/tubes/target': np.array([12., 16., 20.])},
key_type='str'
)
pprint.pprint(funnels)
{'Add_0/slots/b': array([3., 4., 5.])}
{'Add_0/slots/b': array([5., 6., 7.])}
Other Examples
Other more non-trivial examples can be found in the definitions of the transforms, namely in the 'define_waterwork' methods. The transforms are located in wtrkwrks/transforms/.
ML Reversible Transforms
Building transforms to prepare data to be feed into an ML pipeline was the original impetus for creating a system such as waterworks. Generally, nearly identical steps are taken every time one sets up a pipeline that transforms raw data into some vector or tensor representation. The main factor that controls what tranformations need to be done to the data to prepare it, has less to do with the ML algorithm is being used for and more to do with what the data type of the input. Currently there are four primitive transformations:
| Transform | Example Input | Description |
|---|---|---|
| NumTransform | [1.0, 2.0] | Converts one or more numberical inputs into a normalized vector |
| CatTransform | ['a', 1, None] | Converts some categorical variable into normalized one-hot vectors |
| DatetimeTransform | [datetime(2000, 1, 1), datetime(1900, 5, 6, 12, 30, 5)] | Converts datetime inputs into normalized vectors |
| StringTransform | ['They ended up sleeping in a doorway.'] | Converts string into a set of indices which represent some set of tokens |
The description only mentions the principal output of the transform. There are others that are required in order to make the Transform reversible.
Basic Transforms
These transforms are called 'Basic' because they do not require the definition of any sub tranforms. The user interacts with all of them in a very similar manner. The general flow is:
- Define the transform - set any attributes: normalization modes, normalization axes, any functions which handle nans, etc.
- Calculate any global values - find the values that depend on the entire dataset: e.g. means, stds, mins, max, complete list of categories, etc.
- Pour the raw data into a dictionary of normalized, vectorized data.
- Write them to tfrecords.
- Do any training, interference, what have you.
- Pump back any filtered, analyzed data to raw format for human interpretation.
NumTransform
Numerical transforms are the simplest transforms since they usually only require scaling/shifting of the raw values. However it does handle things like nans in a reversible way:
from wtrwrks import NumTransform
import numpy as np
array = np.array(
[
[1, 2],
[4, np.nan],
[7, 0],
[10, 11]
])
trans = NumTransform(
name='NUM',
norm_mode='mean_std', # Either None, 'mean_std', or 'min_max'
norm_axis=0, # The axis (or axes) along which to take the mean, std, max, etc.
)
trans.calc_global_values(array)
# Get the outputs
outputs = trans.pour(array)
print outputs['NUM/nums']
# Or just write them to disk.
trans.write_examples(array, file_name='examples.tfrecord')
# Do whatever with the outputs
# .
# .
# .
# Pump them back to 'array'
remade_array = trans.pump(outputs)
print remade_array
CatTransform
Categorical transformations always one hot their inputs. This means that passes an array of rank k with result in a one hot tensor of rank k+1. The categories can either be explicitly set using valid_cats or infered from the whole dataset when calc global values is called.
from wtrwrks import CatTransform
import numpy as np
array = np.array([
['a', 'b'],
['b', 'None'],
['c', 'b'],
['a', 'c'],
])
trans = CatTransform(
name='CAT',
valid_cats=['a', 'b'], # Explicitly set valid categories or find them when calc_global_values.
norm_mode=None # Either none or 'mean_std'
)
trans.calc_global_values(array)
# Get the outputs
outputs = trans.pour(array)
print outputs['CAT/one_hots']
# Or just write them to disk.
trans.write_examples(array, 'examples.tfrecord')
# Do whatever with the outputs
# .
# .
# .
# Pump them back to 'array'
remade_array = trans.pump(outputs)
print remade_array
DateTimeTransform
DatetimeTransfom's are very similar to NumTransforms except that the datetimes are first changed into some unit of time. The zero datetime, i.e. the datetime that corresponds to the value of zero defaults to datetime(1970, 1, 1). The unit of time can be set when defining the transform by choosing 'time_unit' and 'num_units'. E.g. by choosing time_unit='D' and num_units=2 the datetime would be shown in increments of 2 days. Note that by doing this you are essentially setting the resolution, so you won't be able to get the hours of the day if you use 'time_unit' = 2.
from wtrwrks import DateTimeTransform
import numpy as np
import datetime
array = np.array([
['2019-01-01', '2019-01-01', np.datetime64('NaT')],
['2019-01-02', np.datetime64('NaT'), np.datetime64('NaT')],
['2019-01-03', '2019-02-01', np.datetime64('NaT')],
['2019-01-01', '2019-03-01', np.datetime64('NaT')]
], dtype=np.datetime64)
trans = DateTimeTransform(
name='DATE',
norm_mode=None, # Either none or 'mean_std',
time_unit='W',
num_units=2,
fill_nat_func=lambda a: np.max(a[~np.isnat(a)]),
zero_datetime=datetime.datetime(2000, 1, 1)
)
trans.calc_global_values(array)
# Get the outputs
outputs = trans.pour(array)
print outputs['DATE/nums']
# Or just write them to disk.
trans.write_examples(array, file_name='examples.tfrecord')
# Do whatever with the outputs
# .
# .
# .
# Pump them back to 'array'
remade_array = trans.pump(outputs)
print remade_array
StringTransform
The string transform breaks up an array of raw strings into tokens and converts them to indices according to some index_to_word map. Various string normalization transformations can also be optionally selected like: lowercase, half width (for chinese characters) or lemmatize. The user must supply a tokenizer, and optionally supply a detokenizer. The detokenzer does not have to be exact, but the closer the detokenizer is to the inverse of the tokenizer the less of a diff_string (a string which stores the difference between the raw input and the normalized input) has to be carried around.
from wtrwrks import StringTransform
import numpy as np
array = np.array([
["It is what it is."],
["Here lies one whose name was writ in water."],
["The sun is not yellow, it's chicken. OK."]
])
index_to_word = ['[UNK]', 'chicken.', 'here', 'in', 'is', 'is.', 'it', "it's", 'lies', 'name', 'not', 'ok.', 'one', 'sun', 'the', 'was', 'water.', 'what', 'whose', 'writ', 'yellow,']
trans = StringTransform(
name='STRING',
word_tokenizer=lambda string: string.split(' '), # function which returns a list from string,
word_detokenizer=lambda l: ' '.join(l), # function which returns a string from a list.
index_to_word=index_to_word,
max_sent_len=8,
lower_case=True,
half_width=False,
)
trans.calc_global_values(array)
# Get the outputs
outputs = trans.pour(array)
print outputs['STRING/indices']
# Or just write them to disk.
trans.write_examples(array, file_name='examples.tfrecord')
# Do whatever with the outputs
# .
# .
# .
# Pump them back to 'array'
remade_array = trans.pump(outputs)
print remade_array
Dataset Transform
Typically, a ML model uses several inputs which are of varying type. A dataset transform can be defined to handle this case. It can be thought of as a container transform that holds other sub transforms. Then, when defining the examples for the ML, the entire dataset can be fed through the the dataset transform to get the training examples. An example on how a dataset transform is defined and used can be seen in the TLDR section.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file wtrwrks-2.1.2.tar.gz.
File metadata
- Download URL: wtrwrks-2.1.2.tar.gz
- Upload date:
- Size: 116.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.15.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/2.7.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
28c3a470084ab4fcde8c1e72eaad4870992e213f61a2ae3ae6f128d3bfaedb12
|
|
| MD5 |
3bcb3df115a054defce2b48e3972137a
|
|
| BLAKE2b-256 |
1e55c229b1373aed80200a86206cb768c18a055fc7382ce1aa98e0e102fe593b
|







