Yet another LaTeX filter


Project description
This Python package extracts plain text from LaTeX documents. The software may be integrated with a proofreading tool and an editor. It provides
- mapping of character positions between LaTeX and plain text,
- simple inclusion of own LaTeX macros and environments with tailored treatment,
- careful conservation of text flows,
- some parsing of displayed equations for detection of included “normal” text and of interpunction problems,
- support of multi-language documents (experimental).
A complete description is available at the GitHub page.
The sample Python application script yalafi/shell/shell.py integrates the LaTeX filter with the proofreading software LanguageTool. It sends the extracted plain text to the proofreader, maps position information in returned messages back to the LaTeX text, and generates results in different formats. You may easily
- create a proofreading report in text or HTML format for a complete document tree,
- check LaTeX texts in the editors Emacs and Vim via several plug-ins,
- run the script as emulation of a LanguageTool server with integrated LaTeX filtering.
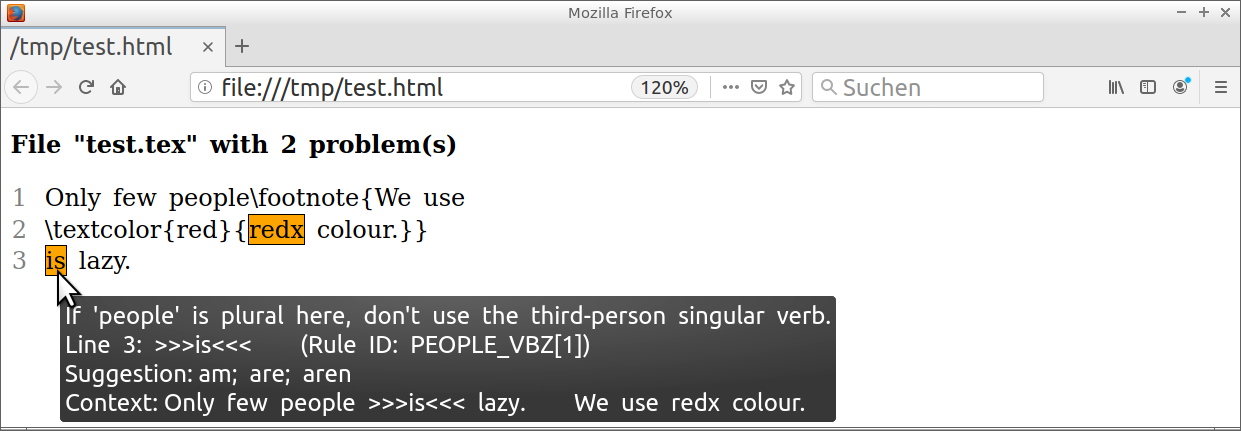
For instance, the LaTeX input
Only few people\footnote{We use
\textcolor{red}{redx colour.}}
is lazy.
will lead to the text report
1.) Line 2, column 17, Rule ID: MORFOLOGIK_RULE_EN_GB
Message: Possible spelling mistake found
Suggestion: red; Rex; reds; redo; Red; Rede; redox; red x
Only few people is lazy. We use redx colour.
^^^^
2.) Line 3, column 1, Rule ID: PEOPLE_VBZ[1]
Message: If 'people' is plural here, don't use the third-person singular verb.
Suggestion: am; are; aren
Only few people is lazy. We use redx colour.
^^
This is the corresponding HTML report:
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file yalafi-1.5.0.tar.gz.
File metadata
- Download URL: yalafi-1.5.0.tar.gz
- Upload date:
- Size: 103.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fee4c836460609861adc141b47898e359ecebd0b7e90e7c331733f3b1b139773
|
|
| MD5 |
a72c3271a183565bb72c08e1b86e50f8
|
|
| BLAKE2b-256 |
9570887ec1956c08b8627bec158ce17f7b9b1c9f0d1b1fa8407d263b235a5e71
|
File details
Details for the file yalafi-1.5.0-py3-none-any.whl.
File metadata
- Download URL: yalafi-1.5.0-py3-none-any.whl
- Upload date:
- Size: 94.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1aaf46a29942238aa8bca21ac5928c76d48831b8be14198bd9bc7059f7026904
|
|
| MD5 |
a888c809bbd0302bfcaf9690923140fe
|
|
| BLAKE2b-256 |
1ccb6d9fbcc76202f60ee59ffc50c6d71a6809642208945bb26359671729f729
|







