YiraBot: Simplifying Web Scraping for All. A user-friendly tool for developers and enthusiasts, offering command-line ease and Python integration. Ideal for research, SEO, and data collection.

Project description

📰 Read the Latest Release Notes




YiraBot README
Introduction
YiraBot is a versatile Python package designed for crawling, scraping, and analyzing web pages. It provides a range of functionalities from basic webpage crawling to detailed SEO analysis, mobile responsiveness checks, and social media integration verification. This document serves as a comprehensive guide to using YiraBot, including installation, usage examples, and an explanation of its core features.
Installation
Before you can use YiraBot, you need to ensure Python is installed on your system. YiraBot is compatible with Python 3.6 and above. You can install YiraBot using pip:
pip install yirabot
Features
YiraBot offers a range of functionalities, including:
- Web Crawling and Scraping: Crawls web pages to extract metadata, links, images, and specific content.
- SEO Analysis: Performs SEO checks on web pages, including title, meta descriptions, headings, and keyword analysis.
- Mobile Responsiveness Check: Verifies if a web page is mobile responsive.
- Social Media Integration Check: Checks for the presence of social media platform integration on a web page.
- Protected Page Crawling: Supports crawling of pages that require authentication.
Usage
Command Line Interface
YiraBot can be invoked directly from the command line with various commands and options:
yirabot <command> [options]
Commands
crawl: Crawls a given URL to extract data.scrape: Specifically extracts main content from a URL.seo: Performs an SEO analysis of the specified web page.get-html: Downloads and saves the complete HTML content of a web page.
Options
-mobile: Uses a mobile user agent for requests.-file: Saves the extracted data in text format.-json: Saves the extracted data in JSON format.
Examples
Crawling a Web Page
To crawl a web page and display extracted data:
yirabot crawl example.com
Saving Crawled Data
To crawl a web page and save the extracted data in JSON format:
yirabot crawl example.com -json
Performing SEO Analysis
To perform an SEO analysis on a web page:
yirabot seo example.com
Checking Mobile Responsiveness
Mobile responsiveness is part of the SEO analysis. To check if a page is mobile responsive:
yirabot seo example.com
Look for the "Mobile Responsiveness" section in the output.
Crawling Protected Pages
YiraBot also supports crawling pages that require authentication. This process is more involved and requires setting up a session:
yirabot session
Follow the interactive prompts to enter login details and choose the crawling method.
Understanding Command Flags and Their Impact
When using YiraBot from the command line, you can modify its behavior with various flags. These flags allow you to tailor the crawling and analysis process to your specific needs. Here’s how the functionality changes with different flags:
- -mobile: Simulates a mobile user agent, which is essential for testing mobile responsiveness and seeing how a site presents itself on mobile devices.
- -file: Saves the extracted data in a text file. This is useful for documentation purposes or further analysis.
- -json: Saves the extracted data in a JSON file, offering a structured format that's easy to integrate with other tools and systems.
Each flag is designed to offer flexibility and control over the crawling and analysis process, ensuring that you can obtain the data you need in the format that best suits your project.
YiraBot is a powerful tool for developers, SEO specialists, and anyone interested in web page analysis. By following this guide, you should be able to install YiraBot, understand its capabilities, and start using it for your web crawling and analysis needs.
YiraBot Python Module
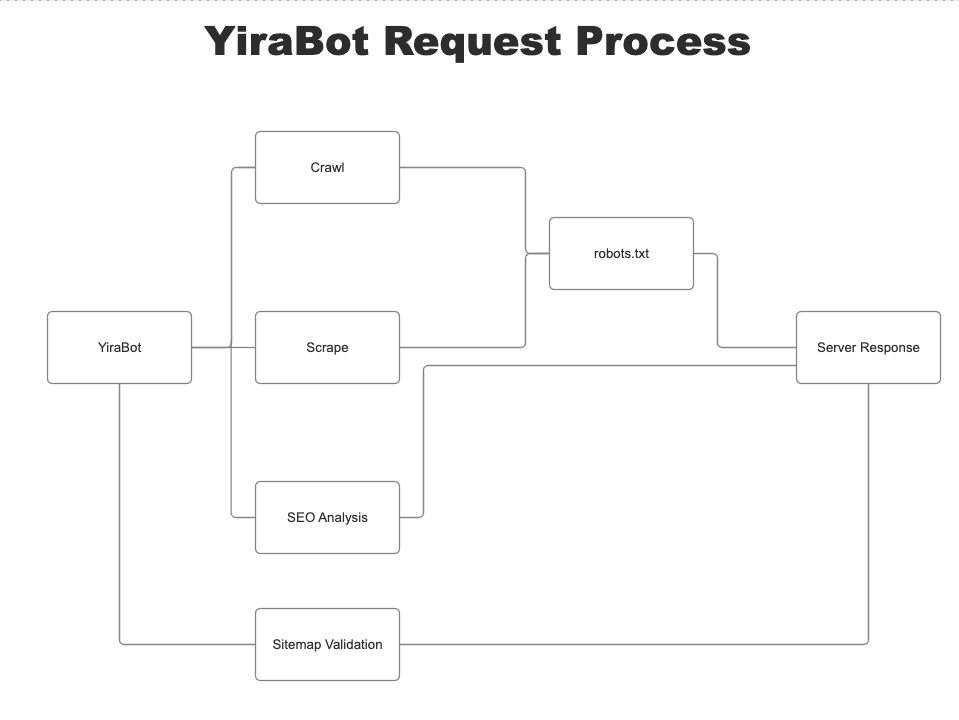
Core Functionalities
1. SEO Analysis (seo_analysis)
- Description: Performs an in-depth SEO analysis on a given URL.
- Key Features:
- Analyzes various SEO factors such as title length, meta description length, headings usage, images without alt text, keyword analysis, mobile responsiveness, social media integration, and website language.
- Utilizes a user-agent from
get_random_user_agent()for requests, simulating different browser types for more accurate SEO testing.
2. Crawling (crawl)
- Description: Crawls a given URL to collect comprehensive data about the page.
- Key Features:
- Extracts information such as favicon, meta description, title, Open Graph tags, Twitter card tags, canonical URL, internal and external links, and image URLs.
- Optionally bypasses robots.txt restrictions with the
forceparameter. - Includes a
dynamic_delaymechanism to adjust request timing based on the server's response, simulating more natural browsing behavior.
3. Scraping (scrape)
- Description: Targets the main content of a webpage, extracting paragraphs, headings, and lists.
- Key Features:
- Designed to scrape content while optionally ignoring robots.txt restrictions through the
forceparameter. - Focuses on extracting textual content critical for content analysis or SEO purposes.
- Designed to scrape content while optionally ignoring robots.txt restrictions through the
4. Sitemap Validation (validate)
- Description: Validates URLs found in a specified sitemap.
- Key Features:
- Parses the sitemap URL to extract all contained URLs, then checks each URL for accessibility, capturing their HTTP response status.
- Useful for ensuring that all URLs in a sitemap are accessible and do not lead to errors.
Advanced Features
- Session Management: Supports the use of sessions via the requests library for more efficient HTTP requests by reusing TCP connections.
- User-Agent Randomization: Mimics different browsers by setting a random user-agent for each request, improving the likelihood of obtaining accurate website content as seen by users.
- Dynamic Request Delay: Implements a
dynamic_delayfunction to adjust the frequency of requests dynamically, reducing the risk of being blocked by the target server. - Robots.txt Respect: By default, respects robots.txt policies for crawling and scraping, unless overridden, ensuring ethical web scraping practices.
- Recursive Error Handling: For methods like crawl and scrape, there's a mechanism to retry the operation in certain failure scenarios, aiming to improve data retrieval success rates.
Usage Scenarios
- SEO Audits: Yirabot can be used to conduct SEO audits on web pages, analyzing critical factors that influence search engine rankings.
- Content Extraction: Ideal for extracting specific content from web pages, such as text, images, and links, for analysis or repurposing.
- Website Health Checks: Validates sitemaps and checks the accessibility of URLs, which is crucial for website maintenance and SEO.
Implementation Notes
To use Yirabot, instantiate the class and call the desired method with appropriate parameters. For SEO analysis and content scraping, pass the target URL and, if available, a session object for authenticated requests.
When performing actions that might be restricted by robots.txt, consider the ethical implications and the legality of bypassing such restrictions with the force parameter.
This class serves as a versatile tool for developers, SEO specialists, and content managers looking to automate the process of web data extraction and analysis, enhancing SEO strategies and website maintenance practices.
Examples Using YiraBot Class
SEO Analysis
from yirabot import Yirabot
bot = Yirabot()
url = "https://example.com"
seo_data = bot.seo_analysis(url)
# Example of processing SEO data
print("Title Length:", seo_data['title_length'])
print("Meta Description Length:", seo_data['meta_desc_length'])
print("Responsive:", "Yes" if seo_data['is_responsive'] else "No")
Crawling
url = "https://example.com"
crawl_data = bot.crawl(url, force=True) #Only use force in ethical situations
# Displaying some extracted data
print("Page Title:", crawl_data['title'])
print("Number of Internal Links:", len(crawl_data['internal_links']))
print("Number of External Links:", len(crawl_data['external_links']))
Scraping
url = "https://example.com/blog"
content_data = bot.scrape(url)
# Displaying the first paragraph and heading
print("First Paragraph:", content_data['paragraphs'][0])
print("First Heading:", content_data['headings'][0])
Sitemap Validation
sitemap_url = "https://example.com/sitemap.xml"
validation_results = bot.validate(sitemap_url)
# Checking and printing inaccessible URLs
inaccessible_urls = {url: status for url, status in validation_results.items() if status != 200}
print("Inaccessible URLs:", inaccessible_urls)
Contributions
Contributions to the YiraBot project are welcomed. Feel free to fork the repository, make your changes, and submit pull requests.
All contributors must follow the Contribution Policy to ensure a smooth and collaborative development process.
License
YiraBot is open-sourced software licensed under the GNU General Public License (Version 3)
Developers:
 Owen Orcan |
 Yigit Ocak |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file YiraBot-1.0.9.2.tar.gz.
File metadata
- Download URL: YiraBot-1.0.9.2.tar.gz
- Upload date:
- Size: 29.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.12.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b87ebdf7762cb3efc24e3cee1ee81b596a2b3dd363863e1d159556e2420d2b49
|
|
| MD5 |
cba34e5419e5a3e76e1c23e60b74add5
|
|
| BLAKE2b-256 |
40d5bb77ec7f48630e6e153bdd1baf4a9194ebc43232597a916e9c5b5828c3b3
|
File details
Details for the file YiraBot-1.0.9.2-py3-none-any.whl.
File metadata
- Download URL: YiraBot-1.0.9.2-py3-none-any.whl
- Upload date:
- Size: 33.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.12.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5b4e0a8f7a8a579475e8cb22d74eac00862e68cafacb79eff1baa1bee66905b7
|
|
| MD5 |
1ee1e0b03b875eade44d127e166302fa
|
|
| BLAKE2b-256 |
54ccf0c651c9808b1589c0cf3b00caff6ba276b3ceed0edcac842542f88640fc
|







