Analyze Youtube videos for general sentiment analysis

Project description
Youtube Sentiment Helper





Determine sentiment of Youtube video per comment based analysis using Sci-kit by analyzing video comments based on positive/negative sentiment. Helper tool to make requests to a machine learning model in order to determine sentiment using the Youtube API.
Install Instructions
pip install .
or PyPI (https://pypi.org/project/youtube-sentiment/)
pip install youtube-sentiment
How to Use
Current usage:
import youtube_sentiment as yt
yt.video_summary(<Youtube API Key>, <Youtube Video ID>, <Max Pages of Comments>, <Sentiment Model>)
or
python main.py <Youtube API Key> <Youtube Video ID> <Max Pages of Comments> <Sentiment Model>
Choices for model selection are found under the included models for setup also under project path ./models
Tests
python setup.py test
To-Do
- Create API to use Youtube API V3 via REST to get comments for videos
- Create initial Python package
- Analyze existing sentiment analysis models to select and use
- Improve/enhance existing sentiment learning model
- Create deep model for sentiment
- Utilize sentiment analysis to analyze Youtube video and provide analytics
- Finalize Python package for project
- Fix any new bugs
- Create web based portal
Models Available
- lr_sentiment_basic (Basic Vectorizer/Logistic Regression model, 2 MB)
- lr_sentiment_cv (Hypertuned TFIDF/Logistic Regression model with clean dataset, 60 MB)
- To-be-added cnn_sentiment (Convolutional Neural Net model)
- To-be-added cnn_sentiment (LTSM Neural Net model)
Traditional ML Model Creation
Why use Twitter sentiment as training?
Twitter comments/replies/tweets are the closest existing training set to Youtube comments that are the simplest to setup. A deep autoencoder could be used to generate comments for a larger dataset (over 100k) with Youtube-esque comments but then the reliability of classifying the data would be very tricky.
TLDR: It is the simplest and most effective to bootstrap for a traditional model
# Develop sentiment analysis classifier using traditional ML models
# Pipeline modeling using the following guide:
# https://ryan-cranfill.github.io/sentiment-pipeline-sklearn-1/
# Data processing and cleaning guide:
# https://towardsdatascience.com/another-twitter-sentiment-analysis-bb5b01ebad90
# Imports
import numpy as np
import time
import pandas as pd
import matplotlib.pyplot as plt
import re
from bs4 import BeautifulSoup
import nltk
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, log_loss, confusion_matrix, auc, roc_curve
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import FeatureUnion, Pipeline
from sklearn.externals import joblib
from sklearn.model_selection import train_test_split
# Dataset of 1.6m Twitter tweets
columns = ['sentiment', 'id', 'date', 'query_string', 'user', 'text']
train = pd.read_csv('stanford_twitter_train.csv', encoding='latin-1', header=None, names=columns)
test = pd.read_csv('stanford_twitter_test.csv', encoding='latin-1', header=None, names=columns)
## Local helpers
# AUC visualization
def show_roc(model, test, test_labels):
# Predict
probs = model.predict_proba(test)
preds = probs[:,1]
fpr, tpr, threshold = roc_curve(test_labels, preds)
roc_auc = auc(fpr, tpr)
# Chart
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
# Tweet cleanser
tok = nltk.tokenize.WordPunctTokenizer()
pat1 = r'@[A-Za-z0-9_]+'
pat2 = r'https?://[^ ]+'
combined_pat = r'|'.join((pat1, pat2))
www_pat = r'www.[^ ]+'
negations_dic = {"isn't":"is not", "aren't":"are not", "wasn't":"was not", "weren't":"were not",
"haven't":"have not","hasn't":"has not","hadn't":"had not","won't":"will not",
"wouldn't":"would not", "don't":"do not", "doesn't":"does not","didn't":"did not",
"can't":"can not","couldn't":"could not","shouldn't":"should not","mightn't":"might not",
"mustn't":"must not"}
neg_pattern = re.compile(r'\b(' + '|'.join(negations_dic.keys()) + r')\b')
def clean_tweet(text):
soup = BeautifulSoup(text, 'lxml')
souped = soup.get_text()
try:
bom_removed = souped.decode("utf-8-sig").replace(u"\ufffd", "?")
except:
bom_removed = souped
stripped = re.sub(combined_pat, '', bom_removed)
stripped = re.sub(www_pat, '', stripped)
lower_case = stripped.lower()
neg_handled = neg_pattern.sub(lambda x: negations_dic[x.group()], lower_case)
letters_only = re.sub("[^a-zA-Z]", " ", neg_handled)
# During the letters_only process two lines above, it has created unnecessay white spaces,
# I will tokenize and join together to remove unneccessary white spaces
words = [x for x in tok.tokenize(letters_only) if len(x) > 1]
return (" ".join(words)).strip()
# Data cleaning
cleaned_tweets = []
for tweet in train['text']:
cleaned_tweets.append(clean_tweet(tweet))
cleaned_df = pd.DataFrame(cleaned_tweets, columns=['text'])
cleaned_df['target'] = train.sentiment
cleaned_df.target[cleaned_df.target == 4] = 1 # rename 4 to 1 as positive label
cleaned_df = cleaned_df[cleaned_df.target != 2] # remove neutral labels
cleaned_df = cleaned_df.dropna() # drop null records
cleaned_df.to_csv('stanford_clean_twitter_train.csv',encoding='utf-8')
# Starting point from import
csv = 'stanford_clean_twitter_train.csv'
df = pd.read_csv(csv,index_col=0)
# Random shuffle and ensure no null records
df = df.sample(frac=1).reset_index(drop=True)
df = df.dropna() # drop null records
X, y = df.text[0:200000], df.target[0:200000] # Max data size 200k for memory purposes
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.10)
# Dataset shapes post-split
print(np.shape(X_train))
print(np.shape(X_test))
print(np.unique(y_train))
(180000,)
(20000,)
[0 1]
# NLTK Twitter tokenizer best used for short comment-type text sets
import nltk
tokenizer = nltk.casual.TweetTokenizer(preserve_case=False)
# Hyperparameter tuning (Simple model)
#cvect = CountVectorizer(tokenizer=tokenizer.tokenize)
tfidf = TfidfVectorizer()
clf = LogisticRegression()
pipeline = Pipeline([
('tfidf', tfidf),
('clf', clf)
])
parameters = {
'tfidf__ngram_range': [(1,1), (1,2), (1,3)], # ngram range of tokenizer
'tfidf__norm': ['l1', 'l2', None], # term vector normalization
'tfidf__max_df': [0.25, 0.5, 1.0], # maximum document frequency for the CountVectorizer
'clf__C': np.logspace(-2, 0, 3) # C value for the LogisticRegression
}
grid = GridSearchCV(pipeline, parameters, cv=3, verbose=1)
print("Performing grid search...")
print("pipeline:", [name for name, _ in pipeline.steps])
t0 = time.time()
grid.fit(X_train, y_train)
print("done in %0.3fs" % (time.time() - t0))
print()
print("Best score: %0.3f" % grid.best_score_)
print("Best parameters set:")
best_parameters = grid.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print("\t%s: %r" % (param_name, best_parameters[param_name]))
Performing grid search...
pipeline: ['tfidf', 'clf']
Fitting 3 folds for each of 81 candidates, totalling 243 fits
[Parallel(n_jobs=1)]: Done 243 out of 243 | elapsed: 52.7min finished
done in 3186.295s
Best score: 0.803
Best parameters set:
clf__C: 0.01
tfidf__max_df: 0.25
tfidf__ngram_range: (1, 3)
tfidf__norm: None
# Dump model from grid search cv
joblib.dump(grid.best_estimator_, 'lr_sentiment_cv.pkl', compress=1)
['lr_sentiment_cv.pkl']
# Starting point 2: Post-model load comparison
lra = joblib.load('./Models/Stanford_Twitter_Models/lr_sentiment_cv.pkl')
lrb = joblib.load('./Models/Twitter_Simple_Models/lr_sentiment_basic.pkl')
# Model performance indicators for basic model
y_pred_basic = lrb.predict(X_test)
print(confusion_matrix(y_test, y_pred_basic))
show_roc(lrb, X_test, y_test) # AUC
[[7562 2347]
[2181 7910]]
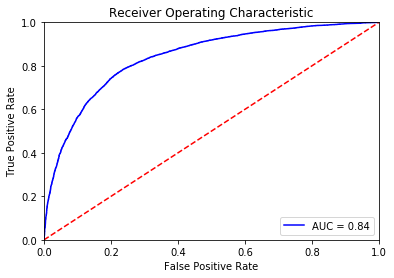
# Model performance indicators for hypertuned model
y_pred_hyper = lra.predict(X_test)
print(confusion_matrix(y_test, y_pred_hyper))
show_roc(lra, X_test, y_test) # AUC
[[7861 2048]
[1863 8228]]
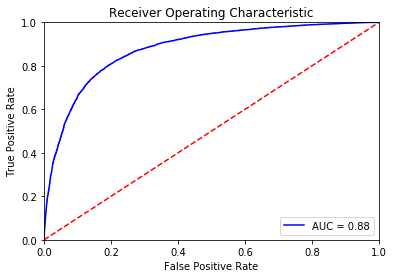
print(lrb.predict(["terrible idea why was this even made"]))
print(lrb.predict(["that was the best movie ever"]))
[0]
[1]
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file youtube_sentiment-0.3.0.tar.gz.
File metadata
- Download URL: youtube_sentiment-0.3.0.tar.gz
- Upload date:
- Size: 58.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.4.2 requests/2.20.0 setuptools/40.5.0 requests-toolbelt/0.8.0 tqdm/4.28.1 CPython/3.4.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
428475343dcfb115ba9d1417bb1955f37fd5f3ca6c22cfd06eec25fe2f298ba0
|
|
| MD5 |
356986d8de0f3fb95666fecfaffa1536
|
|
| BLAKE2b-256 |
bf0152bfd759ae90a800ad538f6f8b0d43da4b1d8d6dc70de04fabbcfe69e68d
|







