Streamlines the process of preparing documents for LLM's.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

Easily chunk complex documents the same way a human would.
Chunking documents is a challenging task that underpins any RAG system. High quality results are critical to a sucessful AI application, yet most open-source libraries are limited in their ability to handle complex documents.
Open Parse is designed to fill this gap by providing a flexible, easy-to-use library capable of visually discerning document layouts and chunking them effectively.
How is this different from other layout parsers?
✂️ Text Splitting
Text splitting converts a file to raw text and slices it up.
- You lose the ability to easily overlay the chunk on the original pdf
- You ignore the underlying semantic structure of the file - headings, sections, bullets represent valuable information.
- No support for tables, images or markdown.
🤖 ML Layout Parsers
There's some of fantastic libraries like layout-parser.
- While they can identify various elements like text blocks, images, and tables, but they are not built to group related content effectively.
- They strictly focus on layout parsing - you will need to add another model to extract markdown from the images, parse tables, group nodes, etc.
- We've found performance to be sub-optimal on many documents while also being computationally heavy.
💼 Commercial Solutions
Highlights
-
🔍 Visually-Driven: Open-Parse visually analyzes documents for superior LLM input, going beyond naive text splitting.
-
✍️ Markdown Support: Basic markdown support for parsing headings, bold and italics.
-
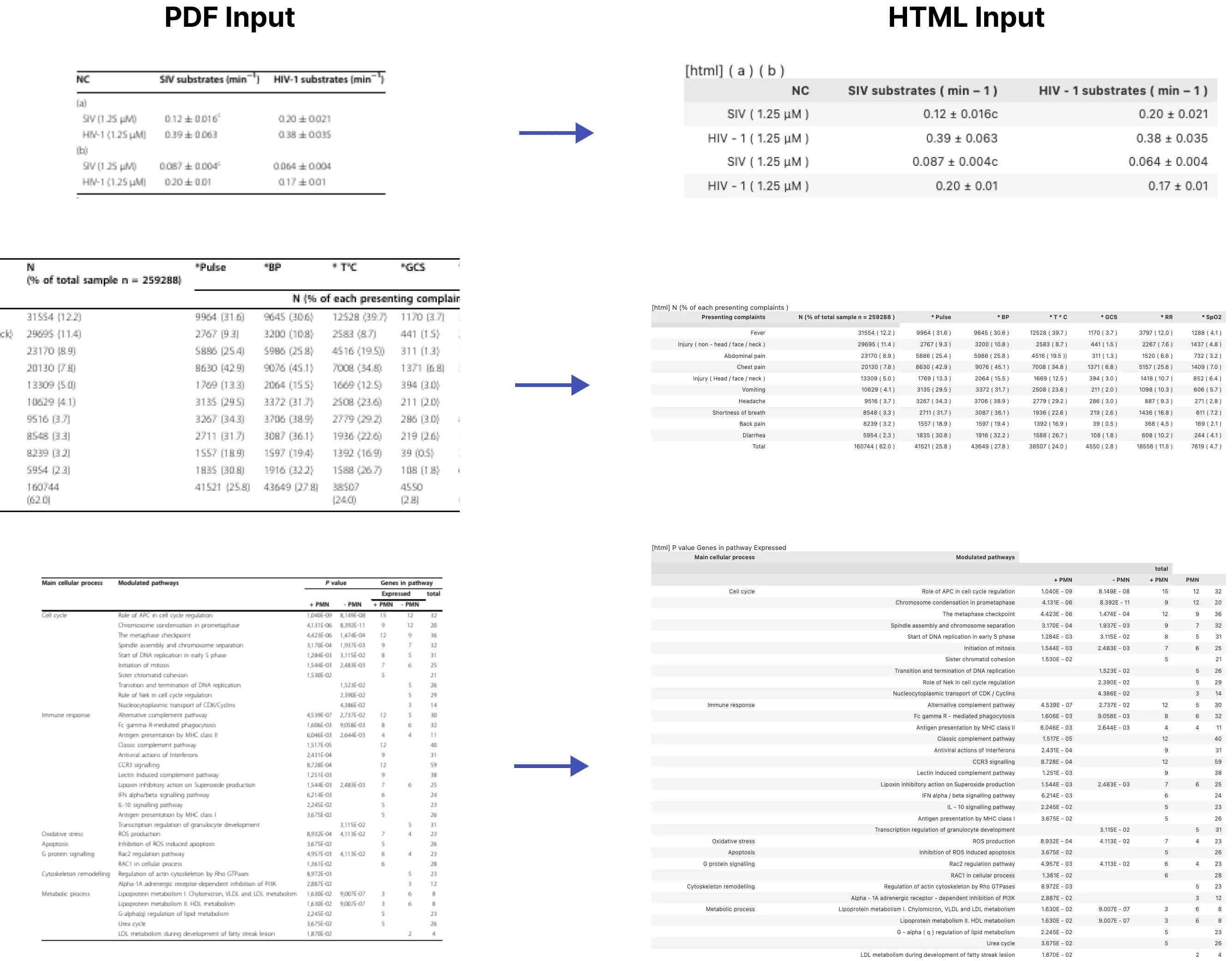
📊 High-Precision Table Support: Extract tables into clean Markdown formats with accuracy that surpasses traditional tools.
Examples
The following examples were parsed with unitable.
-
🛠️ Extensible: Easily implement your own post-processing steps.
-
💡Intuitive: Great editor support. Completion everywhere. Less time debugging.
-
🎯 Easy: Designed to be easy to use and learn. Less time reading docs.

Example
Basic Example
import openparse
basic_doc_path = "./sample-docs/mobile-home-manual.pdf"
parser = openparse.DocumentParser()
parsed_basic_doc = parser.parse(basic_doc_path)
for node in parsed_basic_doc.nodes:
print(node)
📓 Try the sample notebook here
Semantic Processing Example
Chunking documents is fundamentally about grouping similar semantic nodes together. By embedding the text of each node, we can then cluster them together based on their similarity.
from openparse import processing, DocumentParser
semantic_pipeline = processing.SemanticIngestionPipeline(
openai_api_key=OPEN_AI_KEY,
model="text-embedding-3-large",
min_tokens=64,
max_tokens=1024,
)
parser = DocumentParser(
processing_pipeline=semantic_pipeline,
)
parsed_content = parser.parse(basic_doc_path)
📓 Sample notebook here
Serializing Results
Uses pydantic under the hood so you can serialize results with
parsed_content.dict()
# or to convert to a valid json dict
parsed_content.json()
Requirements
Python 3.8+
Dealing with PDF's:
- pdfminer.six Fully open source.
Extracting Tables:
- PyMuPDF has some table detection functionality. Please see their license.
- Table Transformer is a deep learning approach.
- unitable is another transformers based approach with state-of-the-art performance.
Installation
1. Core Library
pip install openparse
Enabling OCR Support:
PyMuPDF will already contain all the logic to support OCR functions. But it additionally does need Tesseract’s language support data, so installation of Tesseract-OCR is still required.
The language support folder location must be communicated either via storing it in the environment variable "TESSDATA_PREFIX", or as a parameter in the applicable functions.
So for a working OCR functionality, make sure to complete this checklist:
-
Install Tesseract.
-
Locate Tesseract’s language support folder. Typically you will find it here:
-
Windows:
C:/Program Files/Tesseract-OCR/tessdata -
Unix systems:
/usr/share/tesseract-ocr/5/tessdata -
macOS (installed via Homebrew):
- Standard installation:
/opt/homebrew/share/tessdata - Version-specific installation:
/opt/homebrew/Cellar/tesseract/<version>/share/tessdata/
- Standard installation:
-
-
Set the environment variable TESSDATA_PREFIX
-
Windows:
setx TESSDATA_PREFIX "C:/Program Files/Tesseract-OCR/tessdata" -
Unix systems:
declare -x TESSDATA_PREFIX=/usr/share/tesseract-ocr/5/tessdata -
macOS (installed via Homebrew):
export TESSDATA_PREFIX=$(brew --prefix tesseract)/share/tessdata
-
Note: On Windows systems, this must happen outside Python – before starting your script. Just manipulating os.environ will not work!
2. ML Table Detection (Optional)
This repository provides an optional feature to parse content from tables using a variety of deep learning models.
pip install "openparse[ml]"
Then download the model weights with
openparse-download
You can run the parsing with the following.
parser = openparse.DocumentParser(
table_args={
"parsing_algorithm": "unitable",
"min_table_confidence": 0.8,
},
)
parsed_nodes = parser.parse(pdf_path)
Note we currently use table-transformers for all table detection and we find its performance to be subpar. This negatively affects the downstream results of unitable. If you're aware of a better model please open an Issue - the unitable team mentioned they might add this soon too.
Cookbooks
https://github.com/Filimoa/open-parse/tree/main/src/cookbooks
Documentation
https://filimoa.github.io/open-parse/
Sponsors

Does your use case need something special? Reach out.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file openparse-0.7.0.tar.gz.
File metadata
- Download URL: openparse-0.7.0.tar.gz
- Upload date:
- Size: 83.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.1 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
965a84ebed051063516c7e0e6e3bc7352c216d6bb54bf2786c369481689554fa
|
|
| MD5 |
1ef245e357faca830d033a2fef29317e
|
|
| BLAKE2b-256 |
d3d7e38a0a8fa1762a0196e0d7828d7a2269a058019c5ef455cbfc0dd4e86035
|
Provenance
The following attestation bundles were made for openparse-0.7.0.tar.gz:
Publisher:
publish.yml on Filimoa/open-parse
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
openparse-0.7.0.tar.gz -
Subject digest:
965a84ebed051063516c7e0e6e3bc7352c216d6bb54bf2786c369481689554fa - Sigstore transparency entry: 148538785
- Sigstore integration time:
-
Permalink:
Filimoa/open-parse@8125c35dd5acc0c1e161e101b96b0f5ad048ac2b -
Branch / Tag:
refs/tags/v0.7.0 - Owner: https://github.com/Filimoa
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@8125c35dd5acc0c1e161e101b96b0f5ad048ac2b -
Trigger Event:
release
-
Statement type:
File details
Details for the file openparse-0.7.0-py3-none-any.whl.
File metadata
- Download URL: openparse-0.7.0-py3-none-any.whl
- Upload date:
- Size: 94.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.1 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
70a07d944a5a99aa628367ede81fe7cc3b16a38fd18314e6a410c4991ba23fb6
|
|
| MD5 |
9c6affd424b3547ff881eaa0f4e0c3e8
|
|
| BLAKE2b-256 |
c7411c2cf979a3b2f5ac6300dc27bbcbe8ae213692c0750ac9177e74b6083305
|
Provenance
The following attestation bundles were made for openparse-0.7.0-py3-none-any.whl:
Publisher:
publish.yml on Filimoa/open-parse
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
openparse-0.7.0-py3-none-any.whl -
Subject digest:
70a07d944a5a99aa628367ede81fe7cc3b16a38fd18314e6a410c4991ba23fb6 - Sigstore transparency entry: 148538786
- Sigstore integration time:
-
Permalink:
Filimoa/open-parse@8125c35dd5acc0c1e161e101b96b0f5ad048ac2b -
Branch / Tag:
refs/tags/v0.7.0 - Owner: https://github.com/Filimoa
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@8125c35dd5acc0c1e161e101b96b0f5ad048ac2b -
Trigger Event:
release
-
Statement type:







