An optimizing inference proxy for LLMs.

Project description
OptiLLM

🚀 2-10x accuracy improvements on reasoning tasks with zero training




🤗 HuggingFace Space • 📓 Colab Demo • 💬 Discussions
OptiLLM is an OpenAI API-compatible optimizing inference proxy that implements 20+ state-of-the-art techniques to dramatically improve LLM accuracy and performance on reasoning tasks - without requiring any model training or fine-tuning.
It is possible to beat the frontier models using these techniques across diverse tasks by doing additional compute at inference time. A good example of how to combine such techniques together is the CePO approach from Cerebras.
✨ Key Features
- 🎯 Instant Improvements: 2-10x better accuracy on math, coding, and logical reasoning
- 🔌 Drop-in Replacement: Works with any OpenAI-compatible API endpoint
- 🧠 20+ Optimization Techniques: From simple best-of-N to advanced MCTS and planning
- 📦 Zero Training Required: Just proxy your existing API calls through OptiLLM
- ⚡ Production Ready: Used in production by companies and researchers worldwide
- 🌍 Multi-Provider: Supports OpenAI, Anthropic, Google, Cerebras, and 100+ models via LiteLLM
🚀 Quick Start
Get powerful reasoning improvements in 3 simple steps:
# 1. Install OptiLLM
pip install optillm
# 2. Start the server
export OPENAI_API_KEY="your-key-here"
optillm
# 3. Use with any OpenAI client - just change the model name!
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1")
# Add 'moa-' prefix for Mixture of Agents optimization
response = client.chat.completions.create(
model="moa-gpt-4o-mini", # This gives you GPT-4o performance from GPT-4o-mini!
messages=[{"role": "user", "content": "Solve: If 2x + 3 = 7, what is x?"}]
)
Before OptiLLM: "x = 1" ❌
After OptiLLM: "Let me work through this step by step: 2x + 3 = 7, so 2x = 4, therefore x = 2" ✅
📊 Proven Results
OptiLLM delivers measurable improvements across diverse benchmarks:
| Technique | Base Model | Improvement | Benchmark |
|---|---|---|---|
| MARS | Gemini 2.5 Flash Lite | +30.0 points | AIME 2025 (43.3→73.3) |
| CePO | Llama 3.3 70B | +18.6 points | Math-L5 (51.0→69.6) |
| AutoThink | DeepSeek-R1-1.5B | +9.34 points | GPQA-Diamond (21.72→31.06) |
| LongCePO | Llama 3.3 70B | +13.6 points | InfiniteBench (58.0→71.6) |
| MOA | GPT-4o-mini | Matches GPT-4 | Arena-Hard-Auto |
| PlanSearch | GPT-4o-mini | +20% pass@5 | LiveCodeBench |
Full benchmark results below ⬇️
🏗️ Installation
Using pip
pip install optillm
optillm
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
2024-10-22 07:45:06,293 - INFO - Starting server with approach: auto
Using docker
docker pull ghcr.io/algorithmicsuperintelligence/optillm:latest
docker run -p 8000:8000 ghcr.io/algorithmicsuperintelligence/optillm:latest
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
2024-10-22 07:45:06,293 - INFO - Starting server with approach: auto
Available Docker image variants:
- Full image (
latest): Includes all dependencies for local inference and plugins - Proxy-only (
latest-proxy): Lightweight image without local inference capabilities - Offline (
latest-offline): Self-contained image with pre-downloaded models (spaCy) for fully offline operation
# Proxy-only (smallest)
docker pull ghcr.io/algorithmicsuperintelligence/optillm:latest-proxy
# Offline (largest, includes pre-downloaded models)
docker pull ghcr.io/algorithmicsuperintelligence/optillm:latest-offline
Install from source
Clone the repository with git and use pip install to setup the dependencies.
git clone https://github.com/algorithmicsuperintelligence/optillm.git
cd optillm
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
🔒 SSL Configuration
OptILLM supports SSL certificate verification configuration for working with self-signed certificates or corporate proxies.
Disable SSL verification (development only):
# Command line
optillm --no-ssl-verify
# Environment variable
export OPTILLM_SSL_VERIFY=false
optillm
Use custom CA certificate:
# Command line
optillm --ssl-cert-path /path/to/ca-bundle.crt
# Environment variable
export OPTILLM_SSL_CERT_PATH=/path/to/ca-bundle.crt
optillm
⚠️ Security Note: Disabling SSL verification is insecure and should only be used in development. For production environments with custom CAs, use --ssl-cert-path instead. See SSL_CONFIGURATION.md for details.
Implemented techniques
| Approach | Slug | Description |
|---|---|---|
| MARS (Multi-Agent Reasoning System) | mars |
Multi-agent reasoning with diverse temperature exploration, cross-verification, and iterative improvement |
| Cerebras Planning and Optimization | cepo |
Combines Best of N, Chain-of-Thought, Self-Reflection, Self-Improvement, and various prompting techniques |
| CoT with Reflection | cot_reflection |
Implements chain-of-thought reasoning with <thinking>, <reflection> and <output> sections |
| PlanSearch | plansearch |
Implements a search algorithm over candidate plans for solving a problem in natural language |
| ReRead | re2 |
Implements rereading to improve reasoning by processing queries twice |
| Self-Consistency | self_consistency |
Implements an advanced self-consistency method |
| Z3 Solver | z3 |
Utilizes the Z3 theorem prover for logical reasoning |
| R* Algorithm | rstar |
Implements the R* algorithm for problem-solving |
| LEAP | leap |
Learns task-specific principles from few shot examples |
| Round Trip Optimization | rto |
Optimizes responses through a round-trip process |
| Best of N Sampling | bon |
Generates multiple responses and selects the best one |
| Mixture of Agents | moa |
Combines responses from multiple critiques |
| Monte Carlo Tree Search | mcts |
Uses MCTS for decision-making in chat responses |
| PV Game | pvg |
Applies a prover-verifier game approach at inference time |
| Deep Confidence | N/A for proxy | Implements confidence-guided reasoning with multiple intensity levels for enhanced accuracy |
| CoT Decoding | N/A for proxy | Implements chain-of-thought decoding to elicit reasoning without explicit prompting |
| Entropy Decoding | N/A for proxy | Implements adaptive sampling based on the uncertainty of tokens during generation |
| Thinkdeeper | N/A for proxy | Implements the reasoning_effort param from OpenAI for reasoning models like DeepSeek R1 |
| AutoThink | N/A for proxy | Combines query complexity classification with steering vectors to enhance reasoning |
Implemented plugins
| Plugin | Slug | Description |
|---|---|---|
| System Prompt Learning | spl |
Implements what Andrej Karpathy called the third paradigm for LLM learning, this enables the model to acquire program solving knowledge and strategies |
| Deep Think | deepthink |
Implements a Gemini-like Deep Think approach using inference time scaling for reasoning LLMs |
| Long-Context Cerebras Planning and Optimization | longcepo |
Combines planning and divide-and-conquer processing of long documents to enable infinite context |
| Majority Voting | majority_voting |
Generates k candidate solutions and selects the most frequent answer through majority voting (default k=6) |
| MCP Client | mcp |
Implements the model context protocol (MCP) client, enabling you to use any LLM with any MCP Server |
| Router | router |
Uses the optillm-modernbert-large model to route requests to different approaches based on the user prompt |
| Chain-of-Code | coc |
Implements a chain of code approach that combines CoT with code execution and LLM based code simulation |
| Memory | memory |
Implements a short term memory layer, enables you to use unbounded context length with any LLM |
| Privacy | privacy |
Anonymize PII data in request and deanonymize it back to original value in response |
| Read URLs | readurls |
Reads all URLs found in the request, fetches the content at the URL and adds it to the context |
| Execute Code | executecode |
Enables use of code interpreter to execute python code in requests and LLM generated responses |
| JSON | json |
Enables structured outputs using the outlines library, supports pydantic types and JSON schema |
| GenSelect | genselect |
Generative Solution Selection - generates multiple candidates and selects the best based on quality criteria |
| Web Search | web_search |
Performs Google searches using Chrome automation (Selenium) to gather search results and URLs |
| Deep Research | deep_research |
Implements Test-Time Diffusion Deep Researcher (TTD-DR) for comprehensive research reports using iterative refinement |
| Proxy | proxy |
Load balancing and failover across multiple LLM providers with health monitoring and round-robin routing |
We support all major LLM providers and models for inference. You need to set the correct environment variable and the proxy will pick the corresponding client.
| Provider | Required Environment Variables | Additional Notes |
|---|---|---|
| OptiLLM | OPTILLM_API_KEY |
Uses the inbuilt local server for inference, supports logprobs and decoding techniques like cot_decoding & entropy_decoding |
| OpenAI | OPENAI_API_KEY |
You can use this with any OpenAI compatible endpoint (e.g. OpenRouter) by setting the base_url |
| Cerebras | CEREBRAS_API_KEY |
You can use this for fast inference with supported models, see docs for details |
| Azure OpenAI | AZURE_OPENAI_API_KEYAZURE_API_VERSIONAZURE_API_BASE |
- |
| Azure OpenAI (Managed Identity) | AZURE_API_VERSIONAZURE_API_BASE |
Login required using az login, see docs for details |
| LiteLLM | depends on the model | See docs for details |
You can then run the optillm proxy as follows.
python optillm.py
2024-09-06 07:57:14,191 - INFO - Starting server with approach: auto
2024-09-06 07:57:14,191 - INFO - Server configuration: {'approach': 'auto', 'mcts_simulations': 2, 'mcts_exploration': 0.2, 'mcts_depth': 1, 'best_of_n': 3, 'model': 'gpt-4o-mini', 'rstar_max_depth': 3, 'rstar_num_rollouts': 5, 'rstar_c': 1.4, 'base_url': '', 'host': '127.0.0.1'}
* Serving Flask app 'optillm'
* Debug mode: off
2024-09-06 07:57:14,212 - INFO - WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:8000
2024-09-06 07:57:14,212 - INFO - Press CTRL+C to quit
Security Note: By default, optillm binds to
127.0.0.1(localhost only) for security. To allow external connections (e.g., for Docker or remote access), use--host 0.0.0.0. Only do this on trusted networks or with proper authentication configured via--optillm-api-key.
Usage
Once the proxy is running, you can use it as a drop in replacement for an OpenAI client by setting the base_url as http://localhost:8000/v1.
import os
from openai import OpenAI
OPENAI_KEY = os.environ.get("OPENAI_API_KEY")
OPENAI_BASE_URL = "http://localhost:8000/v1"
client = OpenAI(api_key=OPENAI_KEY, base_url=OPENAI_BASE_URL)
response = client.chat.completions.create(
model="moa-gpt-4o",
messages=[
{
"role": "user",
"content": "Write a Python program to build an RL model to recite text from any position that the user provides, using only numpy."
}
],
temperature=0.2
)
print(response)
The code above applies to both OpenAI and Azure OpenAI, just remember to populate the OPENAI_API_KEY env variable with the proper key.
There are multiple ways to control the optimization techniques, they are applied in the follow order of preference:
- You can control the technique you use for optimization by prepending the slug to the model name
{slug}-model-name. E.g. in the above code we are usingmoaor mixture of agents as the optimization approach. In the proxy logs you will see the following showing themoais been used with the base model asgpt-4o-mini.
2024-09-06 08:35:32,597 - INFO - Using approach moa, with gpt-4o-mini
2024-09-06 08:35:35,358 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:39,553 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,795 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,797 - INFO - 127.0.0.1 - - [06/Sep/2024 08:35:44] "POST /v1/chat/completions HTTP/1.1" 200 -
- Or, you can pass the slug in the
optillm_approachfield in theextra_body.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "" }],
temperature=0.2,
extra_body={"optillm_approach": "bon|moa|mcts"}
)
- Or, you can just mention the approach in either your
systemoruserprompt, within<optillm_approach> </optillm_approach>tags.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "<optillm_approach>re2</optillm_approach> How many r's are there in strawberry?" }],
temperature=0.2
)
[!TIP] You can also combine different techniques either by using symbols
&and|. When you use&the techniques are processed in the order from left to right in a pipeline with response from previous stage used as request to the next. While, with|we run all the requests in parallel and generate multiple responses that are returned as a list.
Please note that the convention described above works only when the optillm server has been started with inference approach set to auto. Otherwise, the model attribute in the client request must be set with the model name only.
We now support all LLM providers (by wrapping around the LiteLLM sdk). E.g. you can use the Gemini Flash model with moa by setting passing the api key in the environment variable os.environ['GEMINI_API_KEY'] and then calling the model moa-gemini/gemini-1.5-flash-002. In the output you will then see that LiteLLM is being used to call the base model.
9:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,011 - INFO -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,481 - INFO - HTTP Request: POST https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-002:generateContent?key=[redacted] "HTTP/1.1 200 OK"
19:43:21 - LiteLLM:INFO: utils.py:988 - Wrapper: Completed Call, calling success_handler
2024-09-29 19:43:21,483 - INFO - Wrapper: Completed Call, calling success_handler
19:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
[!TIP] optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes the same OpenAI API compatible chat completions endpoint. This should allow you to integrate it into any existing tools or frameworks easily. If the LLM you want to use doesn't have an OpenAI API compatible endpoint (like Google or Anthropic) you can use LiteLLM proxy server that supports most LLMs.
The following sequence diagram illustrates how the request and responses go through optillm.
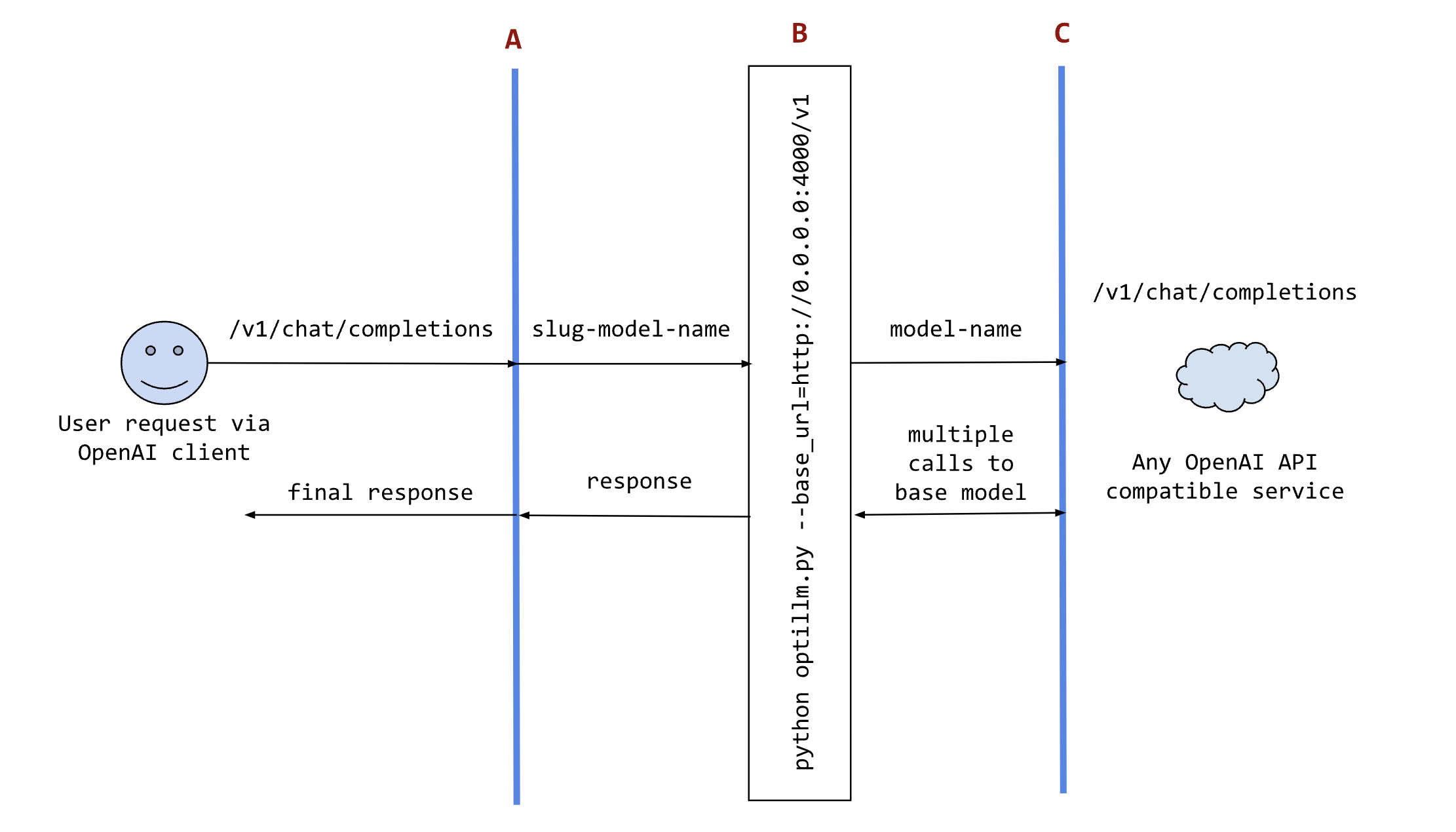
In the diagram:
Ais an existing tool (like oobabooga), framework (like patchwork) or your own code where you want to use the results from optillm. You can use it directly using any OpenAI client sdk.Bis the optillm service (running directly or in a docker container) that will send requests to thebase_url.Cis any service providing an OpenAI API compatible chat completions endpoint.
Local inference server
We support loading any HuggingFace model or LoRA directly in optillm. To use the built-in inference server set the OPTILLM_API_KEY to any value (e.g. export OPTILLM_API_KEY="optillm")
and then use the same in your OpenAI client. You can pass any HuggingFace model in model field. If it is a private model make sure you set the HF_TOKEN environment variable
with your HuggingFace key. We also support adding any number of LoRAs on top of the model by using the + separator.
E.g. The following code loads the base model meta-llama/Llama-3.2-1B-Instruct and then adds two LoRAs on top - patched-codes/Llama-3.2-1B-FixVulns and patched-codes/Llama-3.2-1B-FastApply.
You can specify which LoRA to use using the active_adapter param in extra_body field of OpenAI SDK client. By default we will load the last specified adapter.
OPENAI_BASE_URL = "http://localhost:8000/v1"
OPENAI_KEY = "optillm"
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct+patched-codes/Llama-3.2-1B-FastApply+patched-codes/Llama-3.2-1B-FixVulns",
messages=messages,
temperature=0.2,
logprobs = True,
top_logprobs = 3,
extra_body={"active_adapter": "patched-codes/Llama-3.2-1B-FastApply"},
)
You can also use the alternate decoding techniques like cot_decoding and entropy_decoding directly with the local inference server.
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
messages=messages,
temperature=0.2,
extra_body={
"decoding": "cot_decoding", # or "entropy_decoding"
# CoT specific params
"k": 10,
"aggregate_paths": True,
# OR Entropy specific params
"top_k": 27,
"min_p": 0.03,
}
)
Starting the optillm proxy with an external server (e.g. llama.cpp or ollama)
- Set the
OPENAI_API_KEYenv variable to a placeholder value- e.g.
export OPENAI_API_KEY="sk-no-key"
- e.g.
- Run
./llama-server -c 4096 -m path_to_modelto start the server with the specified model and a context length of 4096 tokens - Run
python3 optillm.py --base_url base_urlto start the proxy- e.g. for llama.cpp, run
python3 optillm.py --base_url http://localhost:8080/v1
- e.g. for llama.cpp, run
[!WARNING] The Anthropic API, llama.cpp-server, and ollama currently do not support sampling multiple responses from a model, which limits the available approaches to the following:
cot_reflection,leap,plansearch,rstar,rto,self_consistency,re2, andz3. For models on HuggingFace, you can use the built-in local inference server as it supports multiple responses.
MCP Plugin
The Model Context Protocol (MCP) plugin enables OptiLLM to connect with MCP servers, bringing external tools, resources, and prompts into the context of language models. This allows for powerful integrations with filesystem access, database queries, API connections, and more.
OptiLLM supports both local and remote MCP servers through multiple transport methods:
- stdio: Local servers (traditional)
- SSE: Remote servers via Server-Sent Events
- WebSocket: Remote servers via WebSocket connections
What is MCP?
The Model Context Protocol (MCP) is an open protocol standard that allows LLMs to securely access tools and data sources through a standardized interface. MCP servers can provide:
- Tools: Callable functions that perform actions (like writing files, querying databases, etc.)
- Resources: Data sources for providing context (like file contents)
- Prompts: Reusable prompt templates for specific use cases
Configuration
Setting up MCP Config
Note on Backwards Compatibility: Existing MCP configurations will continue to work unchanged. The
transportfield defaults to "stdio" when not specified, maintaining full backwards compatibility with existing setups.
- Create a configuration file at
~/.optillm/mcp_config.jsonwith the following structure:
Local Server (stdio) - Traditional Method:
{
"mcpServers": {
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/path/to/allowed/directory1",
"/path/to/allowed/directory2"
],
"env": {},
"description": "Local filesystem access"
}
},
"log_level": "INFO"
}
Legacy Format (still works):
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/directory"],
"env": {}
}
}
}
Remote Server (SSE) - New Feature:
{
"mcpServers": {
"github": {
"transport": "sse",
"url": "https://api.githubcopilot.com/mcp",
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}",
"Accept": "text/event-stream"
},
"timeout": 30.0,
"sse_read_timeout": 300.0,
"description": "GitHub MCP server for repository access"
}
},
"log_level": "INFO"
}
Remote Server (WebSocket) - New Feature:
{
"mcpServers": {
"remote-ws": {
"transport": "websocket",
"url": "wss://api.example.com/mcp",
"description": "Remote WebSocket MCP server"
}
},
"log_level": "INFO"
}
Mixed Configuration (Local + Remote):
{
"mcpServers": {
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/home/user/docs"],
"description": "Local filesystem access"
},
"github": {
"transport": "sse",
"url": "https://api.githubcopilot.com/mcp",
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}"
},
"description": "GitHub MCP server"
},
"remote-api": {
"transport": "websocket",
"url": "wss://api.company.com/mcp",
"description": "Company internal MCP server"
}
},
"log_level": "INFO"
}
Configuration Parameters
Common Parameters:
- Server name: A unique identifier for the server (e.g., "filesystem", "github")
- transport: Transport method - "stdio" (default), "sse", or "websocket"
- description (optional): Description of the server's functionality
- timeout (optional): Connection timeout in seconds (default: 5.0)
stdio Transport (Local Servers):
- command: The executable to run the server
- args: Command-line arguments for the server
- env: Environment variables for the server process
sse Transport (Server-Sent Events):
- url: The SSE endpoint URL
- headers (optional): HTTP headers for authentication
- sse_read_timeout (optional): SSE read timeout in seconds (default: 300.0)
websocket Transport (WebSocket):
- url: The WebSocket endpoint URL
Environment Variable Expansion:
Headers and other string values support environment variable expansion using ${VARIABLE_NAME} syntax. This is especially useful for API keys:
{
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}",
"X-API-Key": "${MY_API_KEY}"
}
}
Available MCP Servers
OptiLLM supports both local and remote MCP servers:
Local MCP Servers (stdio transport)
You can use any of the official MCP servers or third-party servers that run as local processes:
- Filesystem:
@modelcontextprotocol/server-filesystem- File operations - Git:
mcp-server-git- Git repository operations - SQLite:
@modelcontextprotocol/server-sqlite- SQLite database access - Brave Search:
@modelcontextprotocol/server-brave-search- Web search capabilities
Remote MCP Servers (SSE/WebSocket transport)
Remote servers provide centralized access without requiring local installation:
- GitHub MCP Server:
https://api.githubcopilot.com/mcp- Repository management, issue tracking, and code analysis - Third-party servers: Any MCP server that supports SSE or WebSocket protocols
Example: Comprehensive Configuration
{
"mcpServers": {
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/home/user/documents"],
"description": "Local file system access"
},
"search": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-brave-search"],
"env": {
"BRAVE_API_KEY": "your-api-key-here"
},
"description": "Web search capabilities"
},
"github": {
"transport": "sse",
"url": "https://api.githubcopilot.com/mcp",
"headers": {
"Authorization": "Bearer ${GITHUB_TOKEN}",
"Accept": "text/event-stream"
},
"description": "GitHub repository and issue management"
}
},
"log_level": "INFO"
}
Using the MCP Plugin
Once configured, the MCP plugin will automatically:
- Connect to all configured MCP servers
- Discover available tools, resources, and prompts
- Make these capabilities available to the language model
- Handle tool calls and resource requests
The plugin enhances the system prompt with MCP capabilities so the model knows which tools are available. When the model decides to use a tool, the plugin:
- Executes the tool with the provided arguments
- Returns the results to the model
- Allows the model to incorporate the results into its response
Example Queries
Here are some examples of queries that will engage MCP tools:
Local Server Examples:
- "List all the Python files in my documents directory" (Filesystem)
- "What are the recent commits in my Git repository?" (Git)
- "Search for the latest information about renewable energy" (Search)
- "Query my database for all users who registered this month" (Database)
Remote Server Examples:
- "Show me the open issues in my GitHub repository" (GitHub MCP)
- "Create a new branch for the feature I'm working on" (GitHub MCP)
- "What are the most recent pull requests that need review?" (GitHub MCP)
- "Get the file contents from my remote repository" (GitHub MCP)
Troubleshooting
Logs
The MCP plugin logs detailed information to:
~/.optillm/logs/mcp_plugin.log
Check this log file for connection issues, tool execution errors, and other diagnostic information.
Common Issues
Local Server Issues (stdio transport):
-
Command not found: Make sure the server executable is available in your PATH, or use an absolute path in the configuration.
-
Access denied: For filesystem operations, ensure the paths specified in the configuration are accessible to the process.
Remote Server Issues (SSE/WebSocket transport):
-
Connection timeout: Remote servers may take longer to connect. Increase the
timeoutvalue in your configuration. -
Authentication failed: Verify your API keys and tokens are correct. For GitHub MCP server, ensure your
GITHUB_TOKENenvironment variable is set with appropriate permissions. -
Network errors: Check your internet connection and verify the server URL is accessible.
-
Environment variable not found: If using
${VARIABLE_NAME}syntax, ensure the environment variables are set before starting OptILLM.
General Issues:
-
Method not found: Some servers don't implement all MCP capabilities (tools, resources, prompts). Verify which capabilities the server supports.
-
Transport not supported: Ensure you're using a supported transport: "stdio", "sse", or "websocket".
Example: Testing GitHub MCP Connection
To test if your GitHub MCP server configuration is working:
- Set your GitHub token:
export GITHUB_TOKEN="your-github-token" - Start OptILLM and check the logs at
~/.optillm/logs/mcp_plugin.log - Look for connection success messages and discovered capabilities
Available parameters
optillm supports various command-line arguments for configuration. When using Docker, these can also be set as environment variables prefixed with OPTILLM_.
| Parameter | Description | Default Value |
|---|---|---|
--approach |
Inference approach to use | "auto" |
--simulations |
Number of MCTS simulations | 2 |
--exploration |
Exploration weight for MCTS | 0.2 |
--depth |
Simulation depth for MCTS | 1 |
--best-of-n |
Number of samples for best_of_n approach | 3 |
--model |
OpenAI model to use | "gpt-4o-mini" |
--base-url |
Base URL for OpenAI compatible endpoint | "" |
--rstar-max-depth |
Maximum depth for rStar algorithm | 3 |
--rstar-num-rollouts |
Number of rollouts for rStar algorithm | 5 |
--rstar-c |
Exploration constant for rStar algorithm | 1.4 |
--n |
Number of final responses to be returned | 1 |
--return-full-response |
Return the full response including the CoT with tags | False |
--port |
Specify the port to run the proxy | 8000 |
--optillm-api-key |
Optional API key for client authentication to optillm | "" |
--cepo_* |
See CePO Parameters section below for detailed config options | Various |
CePO Parameters
| Parameter | Description | Default Value |
|---|---|---|
--cepo_bestofn_n |
Number of responses to be generated in best of n stage | 3 |
--cepo_bestofn_temperature |
Temperature for verifier in best of n stage | 0.1 |
--cepo_bestofn_max_tokens |
Maximum number of tokens for verifier in best of n stage | 4096 |
--cepo_bestofn_rating_type |
Type of rating in best of n stage ("absolute" or "pairwise") | "absolute" |
--cepo_planning_n |
Number of plans generated in planning stage | 3 |
--cepo_planning_m |
Number of attempts to generate n plans in planning stage | 6 |
--cepo_planning_temperature_step1 |
Temperature for generator in step 1 of planning stage | 0.55 |
--cepo_planning_temperature_step2 |
Temperature for generator in step 2 of planning stage | 0.25 |
--cepo_planning_temperature_direct_resp |
Temperature for generator after step 2 if planning fails and answer directly | 0.1 |
--cepo_planning_temperature_step3 |
Temperature for generator in step 3 of planning stage | 0.1 |
--cepo_planning_temperature_step4 |
Temperature for generator in step 4 of planning stage | 0 |
--cepo_planning_max_tokens_step1 |
Maximum number of tokens in step 1 of planning stage | 4096 |
--cepo_planning_max_tokens_step2 |
Maximum number of tokens in step 2 of planning stage | 4096 |
--cepo_planning_max_tokens_direct_resp |
Maximum number of tokens after step 2 if planning fails and answer directly | 4096 |
--cepo_planning_max_tokens_step3 |
Maximum number of tokens in step 3 of planning stage | 4096 |
--cepo_planning_max_tokens_step4 |
Maximum number of tokens in step 4 of planning stage | 4096 |
--cepo_use_reasoning_fallback |
Whether to fallback to lower levels of reasoning when higher level fails | False |
--cepo_num_of_retries |
Number of retries if llm call fails, 0 for no retries | 0 |
--cepo_print_output |
Whether to print the output of each stage | False |
--cepo_config_file |
Path to CePO configuration file | None |
--cepo_use_plan_diversity |
Use additional plan diversity step | False |
--cepo_rating_model |
Specify a model for rating step if different than for completion | None |
Running with Docker
optillm can optionally be built and run using Docker and the provided Dockerfile.
Using Docker Compose
-
Make sure you have Docker and Docker Compose installed on your system.
-
Either update the environment variables in the docker-compose.yaml file or create a
.envfile in the project root directory and add any environment variables you want to set. For example, to set the OpenAI API key, add the following line to the.envfile:OPENAI_API_KEY=your_openai_api_key_here
-
Run the following command to start optillm:
docker compose up -d
This will build the Docker image if it doesn't exist and start the optillm service.
-
optillm will be available at
http://localhost:8000.
When using Docker, you can set these parameters as environment variables. For example, to set the approach and model, you would use:
OPTILLM_APPROACH=mcts
OPTILLM_MODEL=gpt-4
To secure the optillm proxy with an API key, set the OPTILLM_API_KEY environment variable:
OPTILLM_API_KEY=your_secret_api_key
When the API key is set, clients must include it in their requests using the Authorization header:
Authorization: Bearer your_secret_api_key
SOTA results on benchmarks with optillm
MARS on AIME 2025, IMO 2025, and LiveCodeBench (Oct 2025)
| Benchmark | Approach | Problems | Correct | Accuracy | Improvement |
|---|---|---|---|---|---|
| AIME 2025 | Baseline | 30 | 13 | 43.3% | - |
| AIME 2025 | MARS | 30 | 22 | 73.3% | +30.0pp (+69.2%) |
| IMO 2025 | Baseline | 6 | 1 | 16.7% | - |
| IMO 2025 | MARS | 6 | 2 | 33.3% | +16.7pp (+100%) |
| LiveCodeBench v5/v6 | Baseline | 105 | 41 | 39.05% | - |
| LiveCodeBench v5/v6 | MARS | 105 | 53 | 50.48% | +11.43pp (+29.3%) |
Model: google/gemini-2.5-flash-lite-preview-09-2025 via OpenRouter Configuration: 3 agents, 2-pass verification, thinking tags disabled for proofs
AutoThink on GPQA-Diamond & MMLU-Pro (May 2025)
| Model | GPQA-Diamond | MMLU-Pro | ||
|---|---|---|---|---|
| Accuracy (%) | Avg. Tokens | Accuracy (%) | Avg. Tokens | |
| DeepSeek-R1-Distill-Qwen-1.5B | 21.72 | 7868.26 | 25.58 | 2842.75 |
| with Fixed Budget | 28.47 | 3570.00 | 26.18 | 1815.67 |
| with AutoThink | 31.06 | 3520.52 | 26.38 | 1792.50 |
LongCePO on LongBench v2 (Apr 2025)
| Model¹ | Context window | Short samples (up to 32K words) | Medium samples (32–128K words) |
|---|---|---|---|
| Llama 3.3 70B Instruct | 128K | 36.7 (45.0) | 27.0 (33.0) |
| LongCePO + Llama 3.3 70B Instruct | 8K | 36.8 ± 1.38 | 38.7 ± 2.574 (39.735)² |
| Mistral-Large-Instruct-2411 | 128K | 41.7 (46.1) | 30.7 (34.9) |
| o1-mini-2024-09-12 | 128K | 48.6 (48.9) | 33.3 (32.9) |
| Claude-3.5-Sonnet-20241022 | 200K | 46.1 (53.9) | 38.6 (41.9) |
| Llama-4-Maverick-17B-128E-Instruct | 524K | 32.22 (50.56) | 28.84 (41.86) |
¹ Performance numbers reported by LongBench v2 authors, except for LongCePO and Llama-4-Maverick results.
² Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
LongCePO on HELMET - InfiniteBench En.MC, 128K length (Apr 2025)
| Model | Accuracy (%) |
|---|---|
| Llama 3.3 70B Instruct (full context) | 58.0 |
| LongCePO + Llama 3.3 70B Instruct (8K context) | 71.6 ± 1.855 (73.0)¹ |
| o1-mini-2024-09-12 (full context) | 58.0 |
| gpt-4o-2024-08-06 (full context) | 74.0 |
¹ Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
CePO on math and code benchmarks (Sep 2025)
| Method | AIME 2024 | AIME 2025 | GPQA | LiveCodeBench |
|---|---|---|---|---|
| Qwen3 8B | 74.0 | 68.3 | 59.3 | 55.7 |
| CePO (using Qwen3 8B) | 86.7 | 80.0 | 62.5 | 60.5 |
| Qwen3 32B | 81.4 | 72.9 | 66.8 | 65.7 |
| CePO (using Qwen3 32B) | 90.7 | 83.3 | 70.0 | 71.9 |
| Qwen3 235B | 85.7 | 81.5 | 71.1 | 70.7 |
| DeepSeek R1 | 79.8 | 70.0 | 71.5 | 64.3 |
| OpenAI o3-mini | 79.6 | 74.8 | 76.8 | 66.3 |
| Grok3 Think | 83.9 | 77.3 | 80.2 | 70.6 |
CePO on math and code benchmarks (Mar 2025)
| Method | Math-L5 | MMLU-Pro (Math) | CRUX | LiveCodeBench (pass@1) | Simple QA |
|---|---|---|---|---|---|
| Llama 3.3 70B | 51.0 | 78.6 | 72.6 | 27.1 | 20.9 |
| Llama 3.1 405B | 49.8 | 79.2 | 73.0 | 31.8 | 13.5 |
| CePO (using Llama 3.3 70B) | 69.6 | 84.8 | 80.1 | 31.9 | 22.6 |
| QwQ 32B | 61.4 | 90.8 | 82.5 | 44.3 | 7.8 |
| CePO (using QwQ 32B) | 88.1 | 92.0 | 86.3 | 51.5 | 8.2 |
| DeepSeek R1 Llama | 83.1 | 82.0 | 84.0 | 47.3 | 14.6 |
| CePO (using DeepSeek R1 Llama) | 90.2 | 84.0 | 89.4 | 47.2 | 15.5 |
coc-claude-3-5-sonnet-20241022 on AIME 2024 pass@1 (Nov 2024)
| Model | Score |
|---|---|
| o1-mini | 56.67 |
| coc-claude-3-5-sonnet-20241022 | 46.67 |
| coc-gemini/gemini-exp-1121 | 46.67 |
| o1-preview | 40.00 |
| gemini-exp-1114 | 36.67 |
| claude-3-5-sonnet-20241022 | 20.00 |
| gemini-1.5-pro-002 | 20.00 |
| gemini-1.5-flash-002 | 16.67 |
readurls&memory-gpt-4o-mini on Google FRAMES Benchmark (Oct 2024)
| Model | Accuracy |
|---|---|
| readurls&memory-gpt-4o-mini | 61.29 |
| gpt-4o-mini | 50.61 |
| readurls&memory-Gemma2-9b | 30.1 |
| Gemma2-9b | 5.1 |
| Gemma2-27b | 30.8 |
| Gemini Flash 1.5 | 66.5 |
| Gemini Pro 1.5 | 72.9 |
plansearch-gpt-4o-mini on LiveCodeBench (Sep 2024)
| Model | pass@1 | pass@5 | pass@10 |
|---|---|---|---|
| plansearch-gpt-4o-mini | 44.03 | 59.31 | 63.5 |
| gpt-4o-mini | 43.9 | 50.61 | 53.25 |
| claude-3.5-sonnet | 51.3 | ||
| gpt-4o-2024-05-13 | 45.2 | ||
| gpt-4-turbo-2024-04-09 | 44.2 |
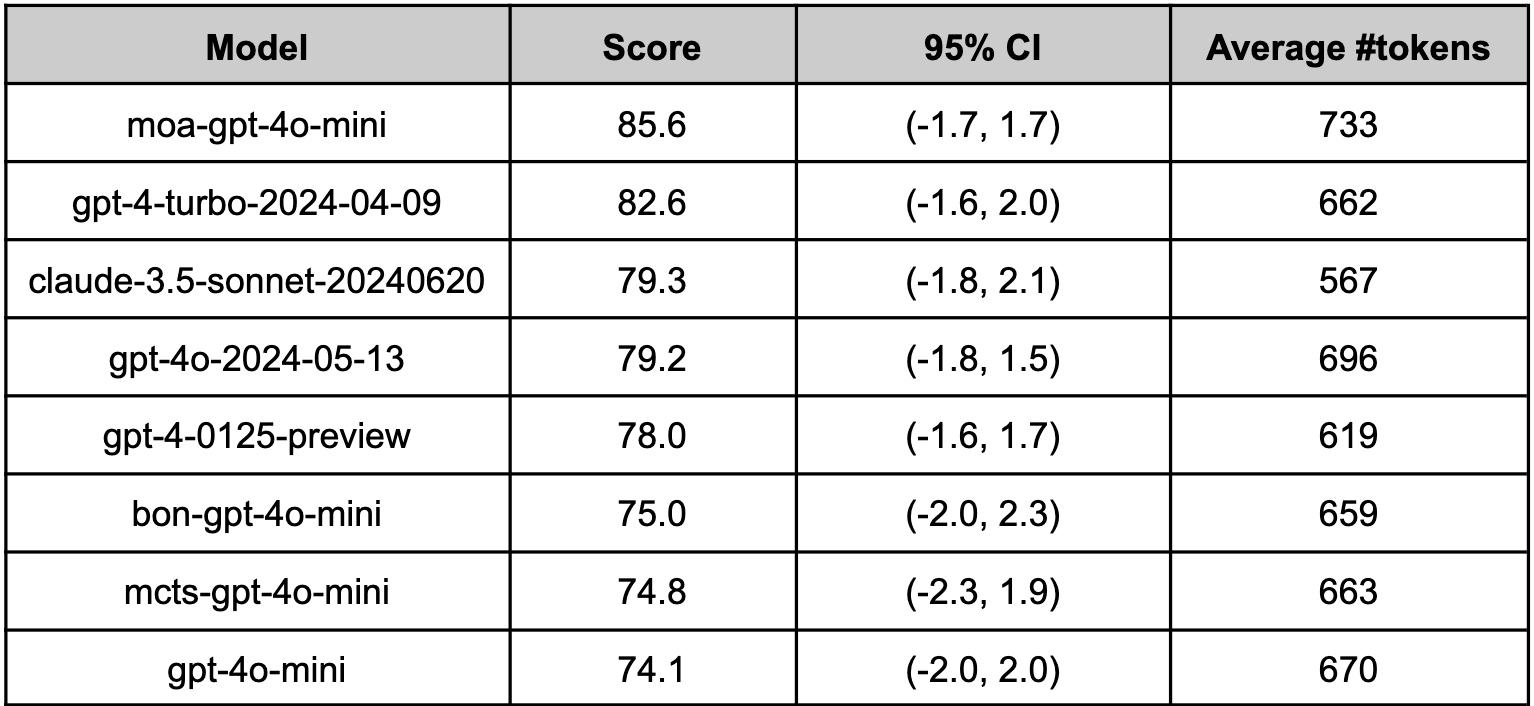
moa-gpt-4o-mini on Arena-Hard-Auto (Aug 2024)
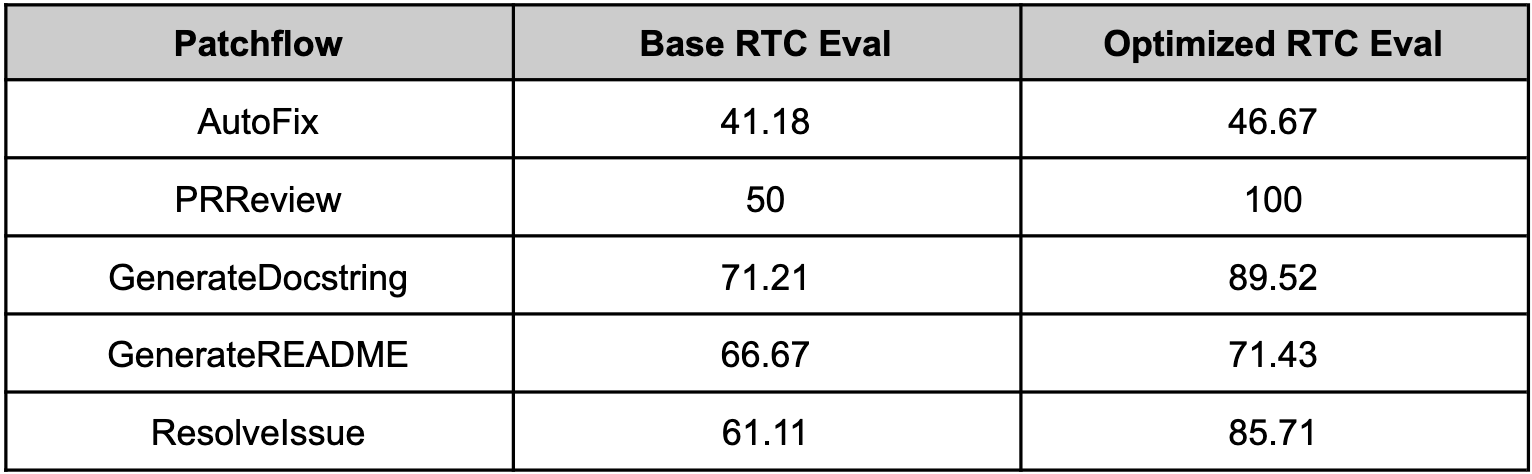
optillm with Patchwork (July 2024)
Since optillm is a drop-in replacement for OpenAI API you can easily integrate it with existing tools and frameworks using the OpenAI client. We used optillm with patchwork which is an open-source framework that automates development gruntwork like PR reviews, bug fixing, security patching using workflows called patchflows. We saw huge performance gains across all the supported patchflows as shown below when using the mixture of agents approach (moa).
Testing
OptiLLM includes a comprehensive test suite to ensure reliability and compatibility.
Running Tests
The main test suite can be run from the project root:
# Test all approaches with default test cases
python tests/test.py
# Test specific approaches
python tests/test.py --approaches moa bon mcts
# Run a single test
python tests/test.py --single-test "Simple Math Problem"
Unit and Integration Tests
Additional tests are available in the tests/ directory:
# Run all tests (requires pytest)
./tests/run_tests.sh
# Run specific test modules
pytest tests/test_plugins.py -v
pytest tests/test_api_compatibility.py -v
CI/CD
All tests are automatically run on pull requests via GitHub Actions. The workflow tests:
- Multiple Python versions (3.10, 3.11, 3.12)
- Unit tests for plugins and core functionality
- API compatibility tests
- Integration tests with various approaches
See tests/README.md for more details on the test structure and how to write new tests.
🤝 Contributing
We ❤️ contributions! OptiLLM is built by the community, for the community.
- 🐛 Found a bug? Open an issue
- 💡 Have an idea? Start a discussion
- 🔧 Want to code? Check out good first issues
Development Setup
git clone https://github.com/algorithmicsuperintelligence/optillm.git
cd optillm
python -m venv .venv
source .venv/bin/activate # or `.venv\Scripts\activate` on Windows
pip install -r requirements.txt
pip install -r tests/requirements.txt
# Run tests
python -m pytest tests/
References
- Eliciting Fine-Tuned Transformer Capabilities via Inference-Time Techniques
- AutoThink: efficient inference for reasoning LLMs - Implementation
- Deep Think with Confidence: Confidence-guided reasoning and inference-time scaling - Implementation
- Self-Discover: Large Language Models Self-Compose Reasoning Structures - Implementation
- CePO: Empowering Llama with Reasoning using Test-Time Compute - Implementation
- LongCePO: Empowering LLMs to efficiently leverage infinite context - Implementation
- Chain of Code: Reasoning with a Language Model-Augmented Code Emulator - Inspired the implementation of coc plugin
- Entropy Based Sampling and Parallel CoT Decoding - Implementation
- Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation - Evaluation script
- Writing in the Margins: Better Inference Pattern for Long Context Retrieval - Inspired the implementation of the memory plugin
- Chain-of-Thought Reasoning Without Prompting - Implementation
- Re-Reading Improves Reasoning in Large Language Models - Implementation
- In-Context Principle Learning from Mistakes - Implementation
- Planning In Natural Language Improves LLM Search For Code Generation - Implementation
- Self-Consistency Improves Chain of Thought Reasoning in Language Models - Implementation
- Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers - Implementation
- Mixture-of-Agents Enhances Large Language Model Capabilities - Inspired the implementation of moa
- Prover-Verifier Games improve legibility of LLM outputs - Implementation
- Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning - Inspired the implementation of mcts
- Unsupervised Evaluation of Code LLMs with Round-Trip Correctness - Inspired the implementation of rto
- Patched MOA: optimizing inference for diverse software development tasks - Implementation
- Patched RTC: evaluating LLMs for diverse software development tasks - Implementation
- AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset - Implementation
- Test-Time Diffusion Deep Researcher (TTD-DR): Think More, Research More, Answer Better! - Implementation
Citation
If you use this library in your research, please cite:
@software{optillm,
title = {OptiLLM: Optimizing inference proxy for LLMs},
author = {Asankhaya Sharma},
year = {2024},
publisher = {GitHub},
url = {https://github.com/algorithmicsuperintelligence/optillm}
}
Ready to optimize your LLMs? Install OptiLLM and see the difference! 🚀
⭐ Star us on GitHub if you find OptiLLM useful!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file optillm-0.3.15.tar.gz.
File metadata
- Download URL: optillm-0.3.15.tar.gz
- Upload date:
- Size: 343.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
445edc16afa045664dbe8f39ec5dc810ff8130aa0fee3f0332b9f297e6453c82
|
|
| MD5 |
ea34d663f41ef6f6002d119b0dd0d720
|
|
| BLAKE2b-256 |
e04ad567b8e770df8bb9b89f2bdacde1e3ad864e3f832af8344ad940fd1642dd
|
Provenance
The following attestation bundles were made for optillm-0.3.15.tar.gz:
Publisher:
publish.yml on algorithmicsuperintelligence/optillm
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
optillm-0.3.15.tar.gz -
Subject digest:
445edc16afa045664dbe8f39ec5dc810ff8130aa0fee3f0332b9f297e6453c82 - Sigstore transparency entry: 1459453388
- Sigstore integration time:
-
Permalink:
algorithmicsuperintelligence/optillm@df018d64db96d07fdd338d71a35fc567f9d50c7b -
Branch / Tag:
refs/tags/v0.3.15 - Owner: https://github.com/algorithmicsuperintelligence
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@df018d64db96d07fdd338d71a35fc567f9d50c7b -
Trigger Event:
release
-
Statement type:
File details
Details for the file optillm-0.3.15-py3-none-any.whl.
File metadata
- Download URL: optillm-0.3.15-py3-none-any.whl
- Upload date:
- Size: 306.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1885cd19a17f01a9bbacb5aad90ea51aaf0a7efa0ff64a33ad004ce7630619c1
|
|
| MD5 |
73e818beea5644fdb44245d366d1fb59
|
|
| BLAKE2b-256 |
efb600008e3406e7ecc34b1b76d543275830e83617287af07e7f7516f884c678
|
Provenance
The following attestation bundles were made for optillm-0.3.15-py3-none-any.whl:
Publisher:
publish.yml on algorithmicsuperintelligence/optillm
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
optillm-0.3.15-py3-none-any.whl -
Subject digest:
1885cd19a17f01a9bbacb5aad90ea51aaf0a7efa0ff64a33ad004ce7630619c1 - Sigstore transparency entry: 1459453508
- Sigstore integration time:
-
Permalink:
algorithmicsuperintelligence/optillm@df018d64db96d07fdd338d71a35fc567f9d50c7b -
Branch / Tag:
refs/tags/v0.3.15 - Owner: https://github.com/algorithmicsuperintelligence
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@df018d64db96d07fdd338d71a35fc567f9d50c7b -
Trigger Event:
release
-
Statement type:







