Analyze and compare voices with deep learning

Project description
Resemblyzer allows you to derive a high-level representation of a voice through a deep learning model (referred to as the voice encoder). Given an audio file of speech, it creates a summary vector of 256 values (an embedding, often shortened to "embed" in this repo) that summarizes the characteristics of the voice spoken.
N.B.: this repo holds 100mb of audio data for demonstration purpose. To get the package alone, run pip install resemblyzer (python 3.5+ is required).
Demos
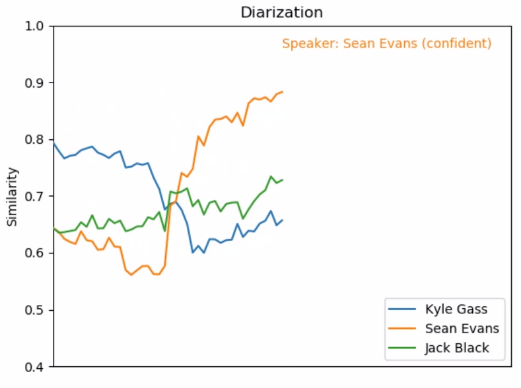
Speaker diarization: [Demo 02] recognize who is talking when with only a few seconds of reference audio per speaker:
(click the image for a video)
Fake speech detection: [Demo 05] modest detection of fake speech by comparing the similarity of 12 unknown utterances (6 real ones, 6 fakes) against ground truth reference audio. Scores above the dashed line are predicted as real, so the model makes one error here.

For reference, this is the fake video that achieved a high score.
Visualizing the manifold:
[Demo 03 - left] projecting the embeddings of 100 utterances (10 each from 10 speakers) in 2D space. The utterances from the same speakers form a tight cluster. With a trivial clustering algorithm, the speaker verification error rate for this example (with data unseen in training) would be 0%.
[Demo 04 - right] same as demo 03 but with 251 embeddings all from distinct speakers, highlighting that the model has learned on its own to identify the sex of the speaker.

Cross-similarity: [Demo 01] comparing 10 utterances from 10 speakers against 10 other utterances from the same speakers.

What can I do with this package?
Resemblyzer has many uses:
- Voice similarity metric: compare different voices and get a value on how similar they sound. This leads to other applications:
- Speaker verification: create a voice profile for a person from a few seconds of speech (5s - 30s) and compare it to that of new audio. Reject similarity scores below a threshold.
- Speaker diarization: figure out who is talking when by comparing voice profiles with the continuous embedding of a multispeaker speech segment.
- Fake speech detection: verify if some speech is legitimate or fake by comparing the similarity of possible fake speech to real speech.
- High-level feature extraction: you can use the embeddings generated as feature vectors for machine learning or data analysis. This also leads to other applications:
- Voice cloning: see this other project.
- Component analysis: figure out accents, tones, prosody, gender, ... through a component analysis of the embeddings.
- Virtual voices: create entirely new voice embeddings by sampling from a prior distribution.
- Loss function: you can backpropagate through the voice encoder model and use it as a perceptual loss for your deep learning model! The voice encoder is written in PyTorch.
Resemblyzer is fast to execute (around 1000x real-time on a GTX 1080, with a minimum of 10ms for I/O operations), and can run both on CPU or GPU. It is robust to noise. It currently works best on English language only, but should still be able to perform somewhat decently on other languages.
Code example
This is a short example showing how to use Resemblyzer:
from resemblyzer import VoiceEncoder, preprocess_wav
from pathlib import Path
import numpy as np
fpath = Path("path_to_an_audio_file")
wav = preprocess_wav(fpath)
encoder = VoiceEncoder()
embed = encoder.embed_utterance(wav)
np.set_printoptions(precision=3, suppress=True)
print(embed)
I highly suggest giving a peek to the demos to understand how similarity is computed and to see practical usages of the voice encoder.
Additional info
Resemblyzer emerged as a side project of the Real-Time Voice Cloning repository. The pretrained model that comes with Resemblyzer is interchangeable with models trained in that repository, so feel free to finetune a model on new data and possibly new languages! The paper from which the voice encoder was implemented is Generalized End-To-End Loss for Speaker Verification (in which it is called the speaker encoder).
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file Resemblyzer-0.1.4.tar.gz.
File metadata
- Download URL: Resemblyzer-0.1.4.tar.gz
- Upload date:
- Size: 15.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ae98d6eaf1def4b91d353347f7d31f10c29e8e109b5196ab29b390293036ad19
|
|
| MD5 |
a312bf116f16087f58edbbcc97f45988
|
|
| BLAKE2b-256 |
fb69b71d45dca34c51467d0df29154f6eb8c19d4effb95dbbaeef6fc160b29de
|
File details
Details for the file Resemblyzer-0.1.4-py3-none-any.whl.
File metadata
- Download URL: Resemblyzer-0.1.4-py3-none-any.whl
- Upload date:
- Size: 15.7 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8f12eb2f1a9982d32e8db7856de754709b59c93a77bcf0ff536584b619a9dd1f
|
|
| MD5 |
48ba5ecfea339f34b46ecdc461f8f063
|
|
| BLAKE2b-256 |
d9b5d897d5de5b2123a1ad5d32e8e007d83f76582f5c32c60992577263bd7c7e
|







