Catalan Text to Speech

Project description
This Repo Contains Implementation of Catalan Text To Speech With Some Samples

Based on Microsoft's FastSpeech
Catalan Version of FastSpeech Repo
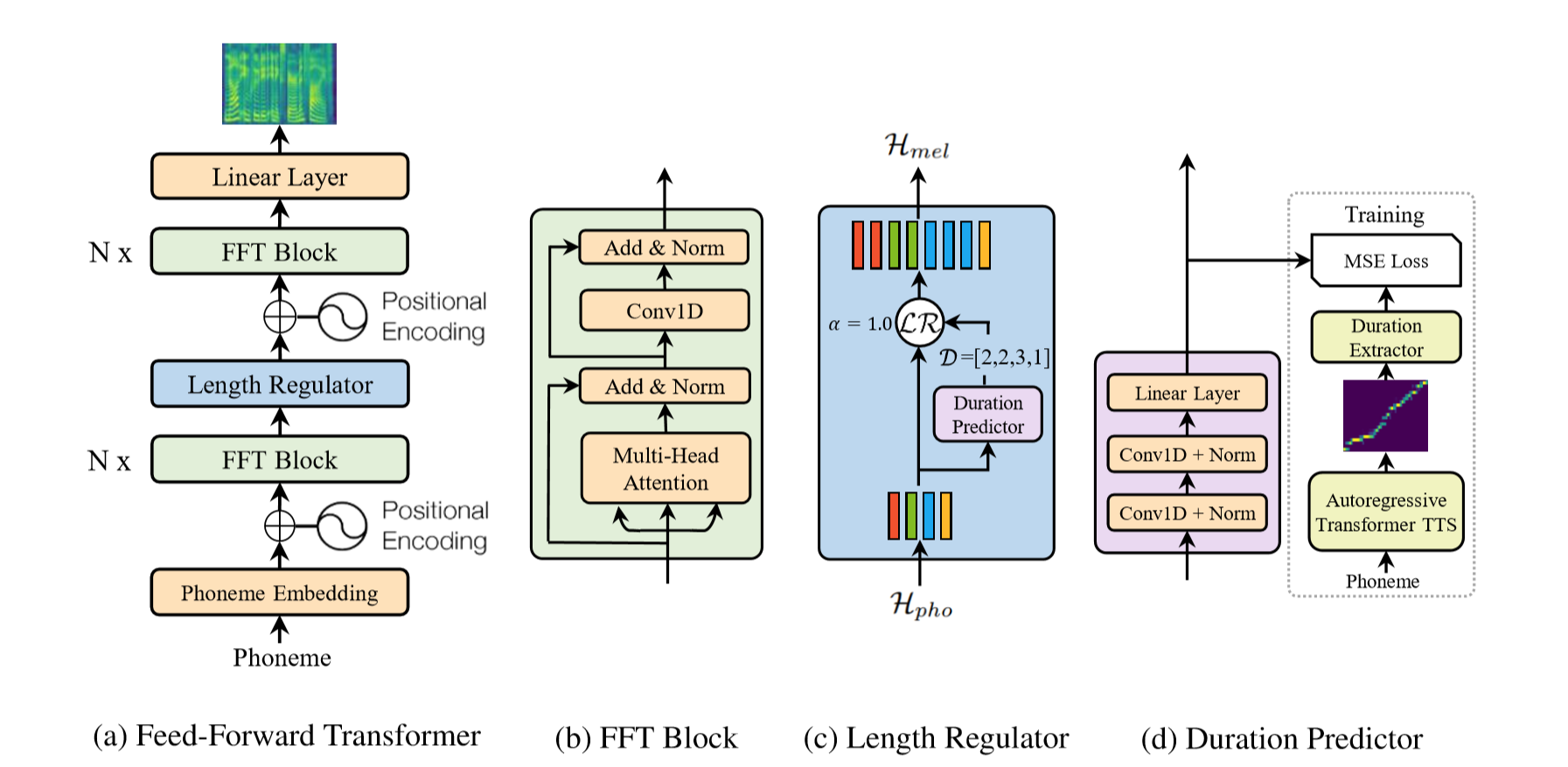
The model has following advantages:
- Robustness: No repeats and failed attention modes for challenging sentences.
- Speed: The generation of a mel spectogram takes about 0.04s on a GeForce RTX 2080.
- Controllability: It is possible to control the speed of the generated utterance.
- Efficiency: In contrast to FastSpeech and Tacotron, the model of ForwardTacotron does not use any attention. Hence, the required memory grows linearly with text size, which makes it possible to synthesize large articles at once.
Check out the latest audio samples (ForwardTacotron + WaveRNN)! The samples are generated with a model trained on 2 hoours of data from Catalan Common Voice and vocoded with WaveRNN, MelGAN, or HiFiGAN. You can try out the latest pretrained model with the following notebook:

References
- FastSpeech: Fast, Robust and Controllable Text to Speech
- FastPitch: Parallel Text-to-speech with Pitch Prediction
- HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
- MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Acknowlegements
- https://github.com/keithito/tacotron
- https://github.com/fatchord/WaveRNN
- https://github.com/seungwonpark/melgan
- https://github.com/jik876/hifi-gan
- https://github.com/xcmyz/LightSpeech
- https://github.com/resemble-ai/Resemblyzer
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/FastPitch
Maintainers
- Mehdi Hosseini Moghadam, github: mehdihosseinimoghadam
Copyright
See LICENSE for details.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file CatalanTTSo-0.0.1.tar.gz.
File metadata
- Download URL: CatalanTTSo-0.0.1.tar.gz
- Upload date:
- Size: 42.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3725bff60f4dc45deb734d062511adaa4d27bcba89207ffa12b132487a43ee8a
|
|
| MD5 |
9996b7949f7f4a7f0b34a909ee42d375
|
|
| BLAKE2b-256 |
9d4e610701ec11c78da9cf97ef0c115a2c647c788b7f0001601629ecbba345a8
|
File details
Details for the file CatalanTTSo-0.0.1-py3-none-any.whl.
File metadata
- Download URL: CatalanTTSo-0.0.1-py3-none-any.whl
- Upload date:
- Size: 62.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9cb6e2f017cf2d779a74a8accc43d18127763f6d8800957dcda652dc010c0fa8
|
|
| MD5 |
92548b1c706a20719d6e6542830281d4
|
|
| BLAKE2b-256 |
659ec73b7cab3418122888c8878c1c9ed8c4fad31447d3fa927c650db898d2da
|







