No project description provided

Project description
Causal Tracer



Causal trace plots for transformer language models.
Demo:

About
This library generates causal trace plots for transformer language models like Llama and GPT2, and should work with any decoder-only model on Huggingface. This library is based on causal tracing code from ROME, and broadly packages and improves on their excellent work. Thank you to these authors! There are some notable differences between the original ROME causal tracing code and this library, such as support for batch processing, automatic noise calculation, more processing options, and a slightly different API.
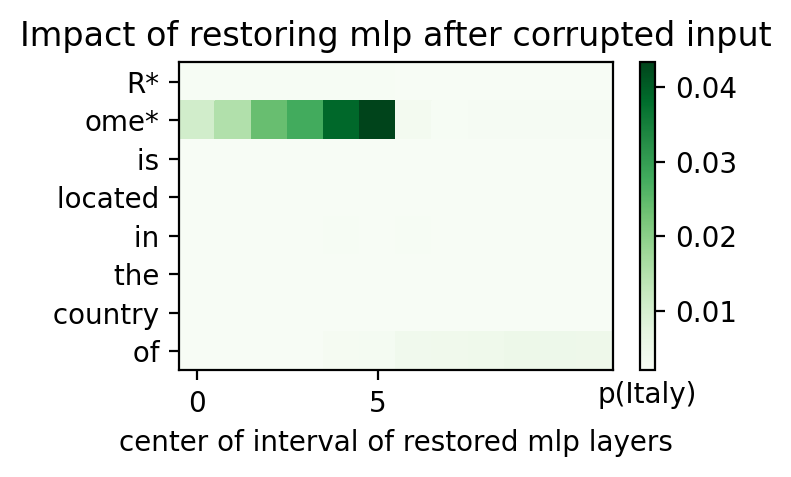
Causal tracing is a technique to find which activations at which layers are causally important for the model to generate any given output. The way this works is by scrambing subject tokens, then slowly replacing activations in the scrambled computation graph and observe if replacing an activation gets the model closer to its original answer.
For instance, if we prompt a languge model with "Rome is located in the country of", it will output "Italy". If we want to understand how the model generated that answer, we can scramble the tokens for "Rome" by adding gaussian noise so the model now sees gibberish instead, like "@#(* is located in the country of". Of course, after this scrambling, there's no way for the model to output "Italy" since the subject is just noise. However, we can take this corrupted computation graph and start replacing activations in it with the original uncorrupted activations, and see if the model starts outputting "Italy" again. If it does, we know that activation is important to the computation!
For more info on causal tracing, check out the original ROME paper, Locating and Editing Factual Associations in GPT.
Installation
pip install causal-tracer
Basic usage
If you're generating causal traces for a Llama-based model or GPT2, you don't need any further configuration.
from transformers import AutoModelForCausalLM, AutoTokenizer
from causal_tracer import CausalTracer, plot_hidden_flow_heatmap
model = AutoModelForCausalLM.from_pretrained("gpt2-medium")
tokenizer = AutoTokenizer.from_pretrained("gpt2-medium")
tracer = CausalTracer(model, tokenizer)
# perform causal tracing across hidden layers (residual stream) of the model
hidden_layer_flow = tracer.calculate_hidden_flow(
"The Space Needle is located in the city of",
subject="The Space Needle",
)
# plot the result
plot_hidden_flow_heatmap(hidden_layer_flow)
You can also generate causal traces of MLP layers or attention layers in the transformer.
from transformers import AutoModelForCausalLM, AutoTokenizer
from causal_tracer import CausalTracer, plot_hidden_flow_heatmap
model = AutoModelForCausalLM.from_pretrained("gpt2-medium")
tokenizer = AutoTokenizer.from_pretrained("gpt2-medium")
tracer = CausalTracer(model, tokenizer)
# perform causal tracing across MLP layers of the model
mlp_layer_flow = tracer.calculate_hidden_flow(
"The Space Needle is located in the city of",
subject="The Space Needle",
kind="mlp",
window=10,
)
plot_hidden_flow_heatmap(mlp_layer_flow)
# perform causal tracing across MLP layers of the model
attn_layer_flow = tracer.calculate_hidden_flow(
"The Space Needle is located in the city of",
subject="The Space Needle",
kind="attention",
window=10,
)
plot_hidden_flow_heatmap(attn_layer_flow)
When generating MLP or attention causal traces, it's you should typically set a window size. In the ROME paper, this is set to 10, which means the MLP or attention traces are replaced as a group and their impact is averaged to make it easier to see the impact of smaller changes.
Batching and sampling
By default, causal traces will be calculated by scrambling the subject tokens with 10 different noise samples, and will run in batches of size 32. You can improve the quality of the causal trace by increasing the number of samples higher. Also, if you run out of RAM during processing, you can try decreasing the batch size.
hidden_layer_flow = tracer.calculate_hidden_flow(
"The Space Needle is located in the city of",
subject="The Space Needle",
samples=50,
batch_size=8,
)
Limiting patching for performance
Running causal tracing can be slow as it requires a lot of passes through the model to generate a trace. You can get a speed-up by only calculating causal traces of certain layers, or only performing patching on subject tokens themselves. The results won't be complete if you do this, but depending on the use-case, that might be fine.
hidden_layer_flow = tracer.calculate_hidden_flow(
"The Space Needle is located in the city of",
subject="The Space Needle",
start_layer=10,
end_layer=15,
patch_subject_tokens_only=True,
)
Custom layer configs
If you're using a model that isn't automatically detected by the library, you'll need to add a LayerConfig to tell CausalTracer where to findthe embeddings, attention, MLP, and hidden layers within the model. You can do this by creating a LayerConfig object and passing it in when creating a CausalTracer object.
from causal_tracer import CausalTracer, LayerConfig
custom_layer_config = LayerConfig(
hidden_layers_matcher="h.{num}",
attention_layers_matcher="h.{num}.attn",
mlp_layers_matcher="h.{num}.mlp",
embedding_layer="wte",
)
tracer = CausalTracer(model, tokenizer, layer_config=custom_layer_config)
Note that hidden_layers_matcher, attention_layers_matcher, and mlp_layers_matcher are template strings, containg {num} in the middle. During processing, {num} will get replaced with the layer number. These strings correspond to the named modules of the transformer. You find all the named modules of a Pytorch model by running model.named_modules().
Using hidden flow results directly
If you want to use the results of the tracer.calculate_hidden_flow() method in downstream tasks instead of just making a plot, the returned HiddenFlow object contains a number of fields which can be further analyzed. The full HiddenFlow dataclass types are below:
class HiddenFlow:
scores: torch.Tensor
low_score: float
high_score: float
input_ids: torch.Tensor
input_tokens: list[str]
subject_range: tuple[int, int]
answer: str
kind: LayerKind # one of "hidden", "attention", or "mlp"
layer_outputs: OrderedDict[str, torch.Tensor]
Of particular interest, the score attribute contains the full matrix of causal tracing scores. The layer_outputs attribute contains the uncorrupted layer activations for each layer of the type being analyzed.
Contributing
Contributions are welcome! If you submit code, please make sure to add or update tests coverage along with your change. This repo uses Black for code formatting, MyPy for type checking, and Flake8 for linting.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file causal_tracer-1.1.0.tar.gz.
File metadata
- Download URL: causal_tracer-1.1.0.tar.gz
- Upload date:
- Size: 20.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.0.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 6ba553500c99481a86ce252e2fc4f7ce39b5e11d77a452785c200f15ffe6ae57 |
|
| MD5 | 15bfe66c4318ca116587b1c0e1e68542 |
|
| BLAKE2b-256 | 827e2e41ce511628eb5a6b6ef7365422ca37f345da186c176ecf6e2d4a39dbda |
File details
Details for the file causal_tracer-1.1.0-py3-none-any.whl.
File metadata
- Download URL: causal_tracer-1.1.0-py3-none-any.whl
- Upload date:
- Size: 24.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.0.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | d1e1d12744a0ad9c1edf28636541ba2140f56eaaf7e00632f2e73d4ec3d519d8 |
|
| MD5 | 35e3a68a582346c65c4964029c894e5d |
|
| BLAKE2b-256 | c017aa5d58f74185beaa3764b14bba75b61e9755f67e52486bd45988205e282b |







