Mastering Diverse Domains through World Models

Project description
Mastering Diverse Domains through World Models
A reimplementation of DreamerV3, a scalable and general reinforcement learning algorithm that masters a wide range of applications with fixed hyperparameters.

If you find this code useful, please reference in your paper:
@article{hafner2023dreamerv3,
title={Mastering Diverse Domains through World Models},
author={Hafner, Danijar and Pasukonis, Jurgis and Ba, Jimmy and Lillicrap, Timothy},
journal={arXiv preprint arXiv:2301.04104},
year={2023}
}
To learn more:
DreamerV3
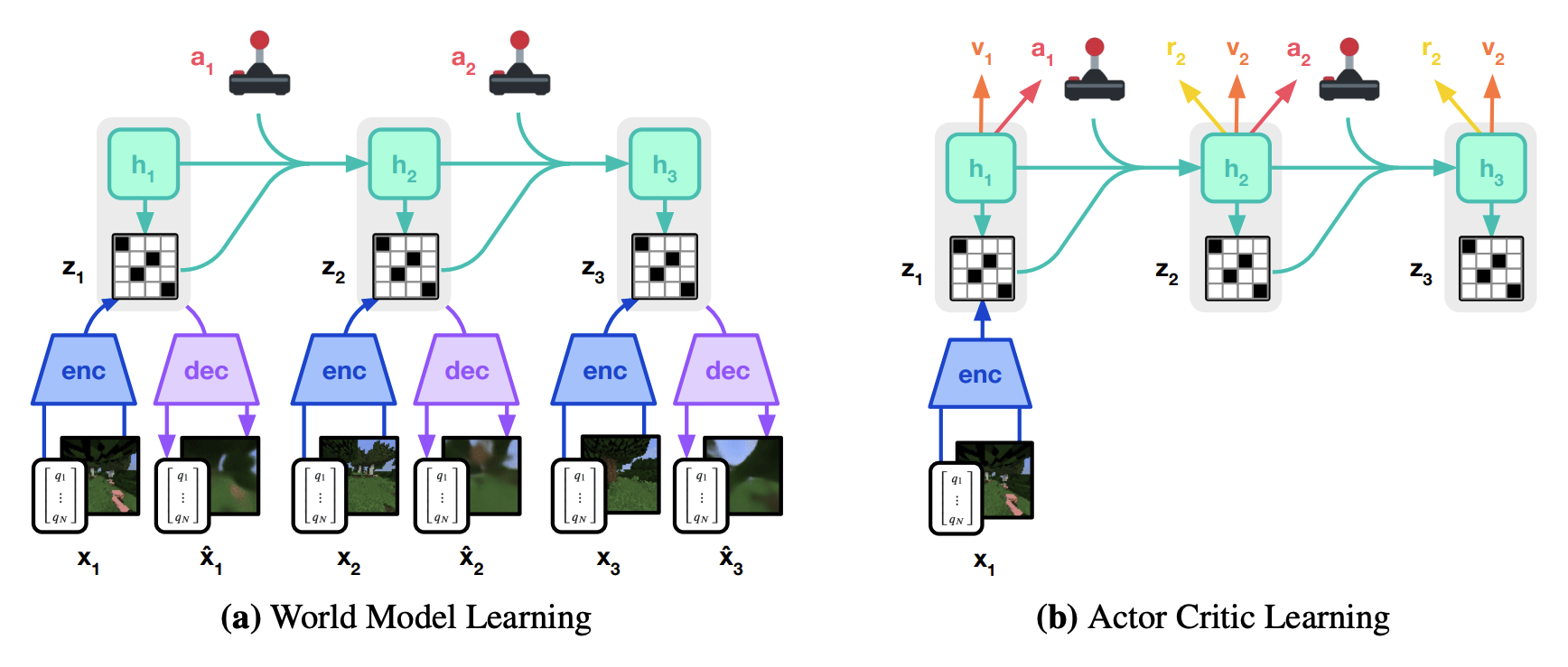
DreamerV3 learns a world model from experiences and uses it to train an actor critic policy from imagined trajectories. The world model encodes sensory inputs into categorical representations and predicts future representations and rewards given actions.
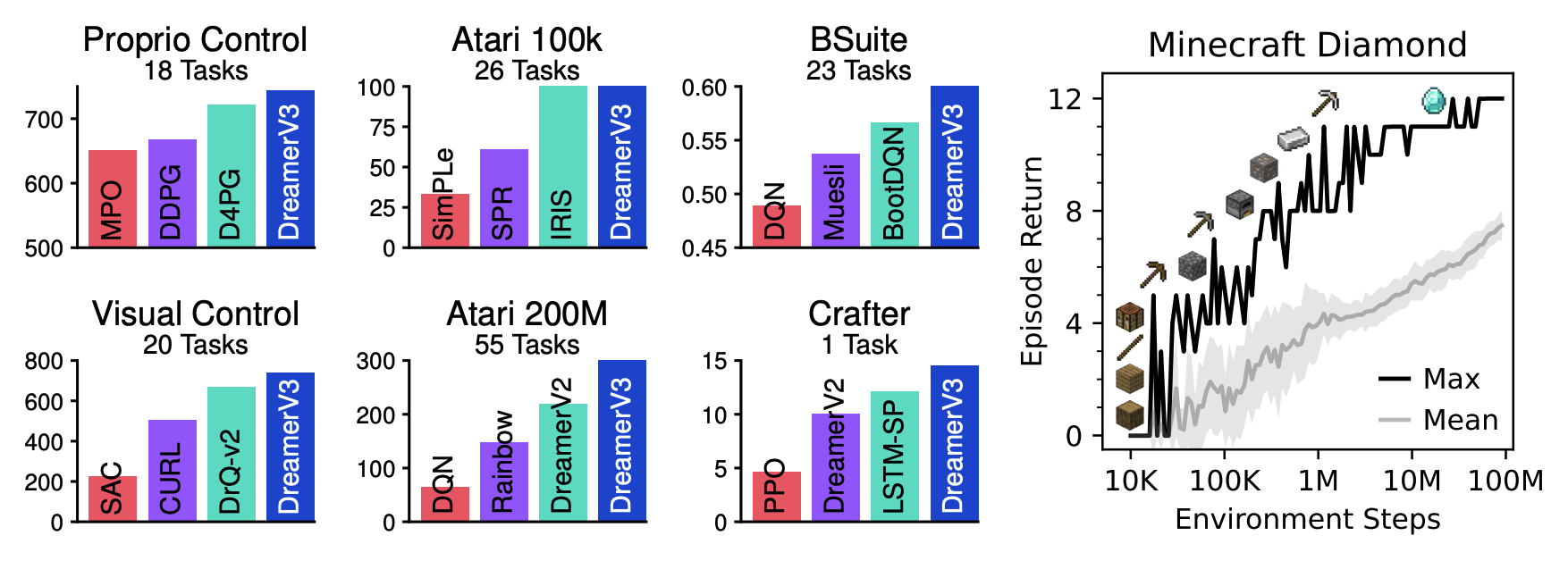
DreamerV3 masters a wide range of domains with a fixed set of hyperparameters, outperforming specialized methods. Removing the need for tuning reduces the amount of expert knowledge and computational resources needed to apply reinforcement learning.
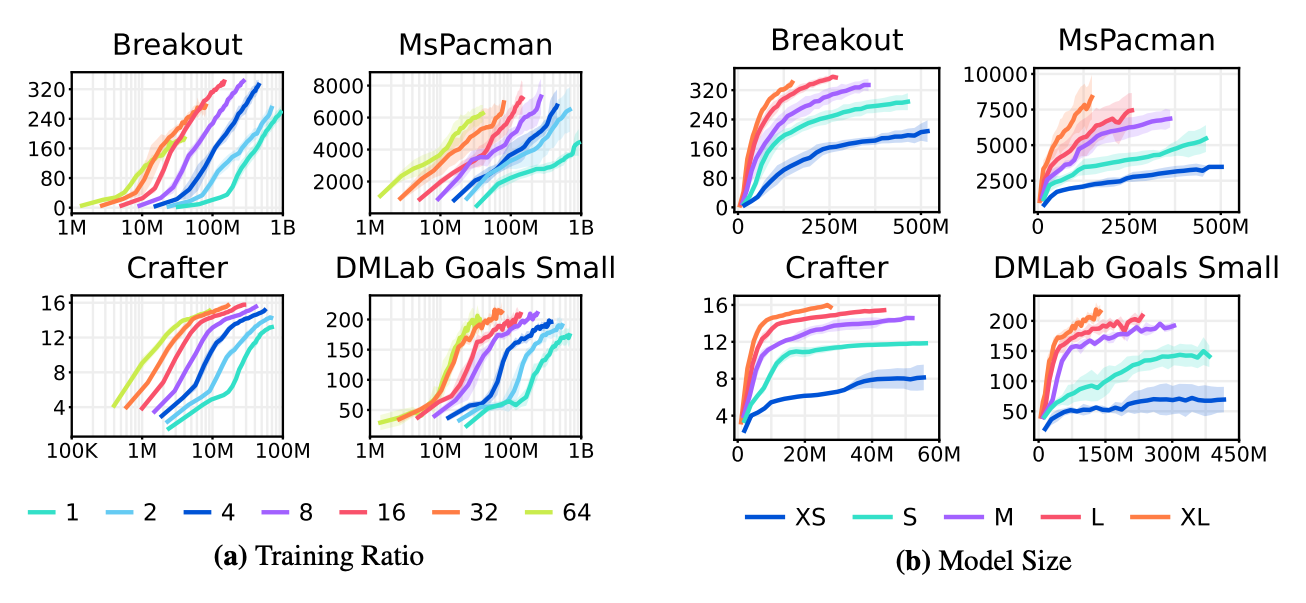
Due to its robustness, DreamerV3 shows favorable scaling properties. Notably, using larger models consistently increases not only its final performance but also its data-efficiency. Increasing the number of gradient steps further increases data efficiency.
Instructions
Package
If you just want to run DreamerV3 on a custom environment, you can pip install dreamerv3 and copy example.py from this repository as a starting
point.
Docker
If you want to make modifications to the code, you can either use the provided
Dockerfile that contains instructions or follow the manual instructions
below.
Manual
Install JAX and then the other dependencies:
pip install -r requirements.txt
Simple training script:
python example.py
Flexible training script:
python dreamerv3/train.py \
--logdir ~/logdir/$(date "+%Y%m%d-%H%M%S") \
--configs crafter --batch_size 16 --run.train_ratio 32
Tips
- All config options are listed in
configs.yamland you can override them from the command line. - The
debugconfig block reduces the network size, batch size, duration between logs, and so on for fast debugging (but does not learn a good model). - By default, the code tries to run on GPU. You can switch to CPU or TPU using
the
--jax.platform cpuflag. Note that multi-GPU support is untested. - You can run with multiple config blocks that will override defaults in the
order they are specified, for example
--configs crafter large. - By default, metrics are printed to the terminal, appended to a JSON lines file, and written as TensorBoard summaries. Other outputs like WandB can be enabled in the training script.
- If you get a
Too many leaves for PyTreeDeferror, it means you're reloading a checkpoint that is not compatible with the current config. This often happens when reusing an old logdir by accident. - If you are getting CUDA errors, scroll up because the cause is often just an error that happened earlier, such as out of memory or incompatible JAX and CUDA versions.
- You can use the
small,medium,largeconfig blocks to reduce memory requirements. The default isxlarge. See the scaling graph above to see how this affects performance. - Many environments are included, some of which require installating additional
packages. See the installation scripts in
scriptsand theDockerfilefor reference. - When running on custom environments, make sure to specify the observation
keys the agent should be using via
encoder.mlp_keys,encode.cnn_keys,decoder.mlp_keysanddecoder.cnn_keys. - To log metrics from environments without showing them to the agent or storing
them in the replay buffer, return them as observation keys with
log_prefix and enable logging via therun.log_keys_...options. - To continue stopped training runs, simply run the same command line again and
make sure that the
--logdirpoints to the same directory.
Disclaimer
This repository contains a reimplementation of DreamerV3 based on the open source DreamerV2 code base. It is unrelated to Google or DeepMind. The implementation has been tested to reproduce the official results on a range of environments.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file dreamerv3-1.5.0.tar.gz.
File metadata
- Download URL: dreamerv3-1.5.0.tar.gz
- Upload date:
- Size: 83.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
593a5d14473e481377133225d493ae991a6b62aa70cbbac84e3d055ab72d1f55
|
|
| MD5 |
7188be090341fb04dbc4e79d64b1235b
|
|
| BLAKE2b-256 |
5d12dc1dad62858ad2f0ab369289d6b919caa691b021922cf6e1881825e016a1
|







