A package designed to allow scoring of gene expression patterns using the Gene Expression Similarity Score system

Project description
GESS - the Gene Expression Similarity Score
Defining GESS
Gene expression patterns can be highly informative of a gene's biology - after all, temporal and spatial regulation is a key part of controlling gene function. However, comparing expression patterns is not trivial, and requires the user to define how "similar" two expression patterns are.
The Gene Expression Similarity Score (lovingly referred to as GESS) is a broadly-applicable solution to this problem. For any given dataset with multiple contexts (ie tissues, timepoints, cell typess...) available, each gene can be ranked by context from highest expression to lowest, thus defining that gene’s expression pattern. We considered the major defining features of this expression pattern to be the ordering of these contexts across the totality of the annotation, and the difference in gene enrichment within like contexts across datasets.
Thus, given two datasets Q (Query) and T (Target) with at least some comparable contexts, the similarity in expression between any two genes can be defined across datasets as:

For a given gene in a set of like contexts, the expression difference between Q and T can be defined as:
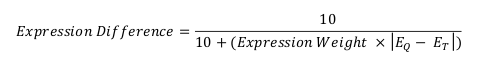
Where EQ and ET represent log2 expression of the gene in Q and T datasets respectively. Expression weight is applied as a modifier designed to emphasise expression differences where datasets differ in fold-change directionality within a context relative to baseline.
Expression weight is defined as:
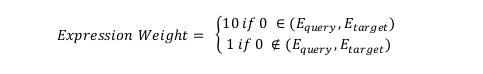
For a given context, the position difference between Q and T can be defined as:
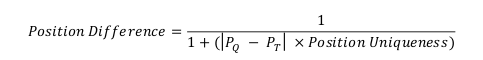
Where PQ and PT represent the position of a given context within a ranked list of all contexts in datasets Q and T respectively.
Position Uniqueness is applied as a modifier to alter the relative scale of position differences based on how unique the expression noted in a specific context is across both datasets within the whole annotation level. Position Uniqueness is defined as:

Where UQ and UT represent Context Uniqueness (U) of a given context in datasets Q and T respectively.
Context Uniqueness is defined as:
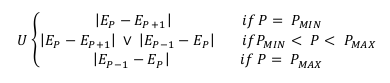
Using GESS
GESS, as you'll appreciate, is somewhat complicated to manually calculate. To facilitate general usage of GESS, we provide the programs in the current repository
Installation
-> For command line version - Simply download this repository -> For python module Downloadable from PyPI (https://pypi.org/project/GESS/) using the command pip install GESS
Requirements
Python3 >= 3.10 numpy pandas seaborn fastcluster matplotlib scanpy
Running GESS
The following examples are for running GESS from the command line. For a python walkthrough, check "GESS_Tutorial.ipynb" for a Jupyter notebook tutorial
With a single-cell dataset of interest "Sample1.h5ad", which contains information of interest across "cell type" and "tissue" levels, GESS can be calculated using Expression data between two genes with the following command:
python GESSfinder.py -qg -tg -qd <Sample1.h5ad> -anno <"cell type" "tissue"> -mode <"expression">
A second dataset can be defined using the -td argument.
Single cell data can be analysed using either "expression" (average expression in each defined annotation level) or "prevalence" (number of cells of each annotation expressing a gene) modes.
Bulk RNA sequencing data can also be analysed based on an Enrichment matrix (Expression of gene in each sample is normalised against a calibrator sample). This also requires manual definition of each annotation level in a seperate annotation.csv (see example in Example Data folder). Bulk RNA seq GESS can then be run with the command:
python GESSfinder.py -qg -tg -qd -a <Annotation.csv> -qs -ts -mode <"bulk"> -anno <"Tissue" "Function">
This repository also contains code for automatically calculating GESS across multiple genes of interest, and hierarchically clustering results based on their GESS value. This function can be called using GESSmatricise.py, defining datasets as above. Gene lists can be defined in line-separated .txt files (see example in Example Data folder). For example, for single-cell data:
python GESSmatricise.py -iq <GeneList1.txt> -qd <Sample1.h5ad> -anno <"cell type" "tissue"> -mode <"expression">
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file gess-0.1.1.tar.gz.
File metadata
- Download URL: gess-0.1.1.tar.gz
- Upload date:
- Size: 26.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
69d45fcf7a7291f045f70100ac775c06dff1711ba76551b16a26550c355dbf37
|
|
| MD5 |
0d2d468457b63c75028059dbadc4f93a
|
|
| BLAKE2b-256 |
1cb2e2efd4a44052dda2848fbd97b93caef6b6334be48939f5a5067d8e74bdb8
|
File details
Details for the file gess-0.1.1-py3-none-any.whl.
File metadata
- Download URL: gess-0.1.1-py3-none-any.whl
- Upload date:
- Size: 31.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2e9ab3f2f378aaeac2f33b67231986e97f28ae868d63a65ff5e4f17b5b6d0fef
|
|
| MD5 |
bf1510197c0fc5a07be8e90679d69595
|
|
| BLAKE2b-256 |
5db5014f8804c6043400ad7f9d137eb767bae6ab1e5c2efea184071dae438529
|







