A fast, powerful, and simple hierarchical vision transformer

Project description
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles






This is the official implementation for our ICML 2023 Oral paper:
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Chaitanya Ryali*,
Yuan-Ting Hu*,
Daniel Bolya*,
Chen Wei,
Haoqi Fan,
Po-Yao Huang,
Vaibhav Aggarwal,
Arkabandhu Chowdhury,
Omid Poursaeed,
Judy Hoffman,
Jitendra Malik,
Yanghao Li*,
Christoph Feichtenhofer*
ICML '23 Oral | GitHub | arXiv | BibTeX
*: Equal contribution.
What is Hiera?
Hiera is a hierarchical vision transformer that is fast, powerful, and, above all, simple. It outperforms the state-of-the-art across a wide array of image and video tasks while being much faster.
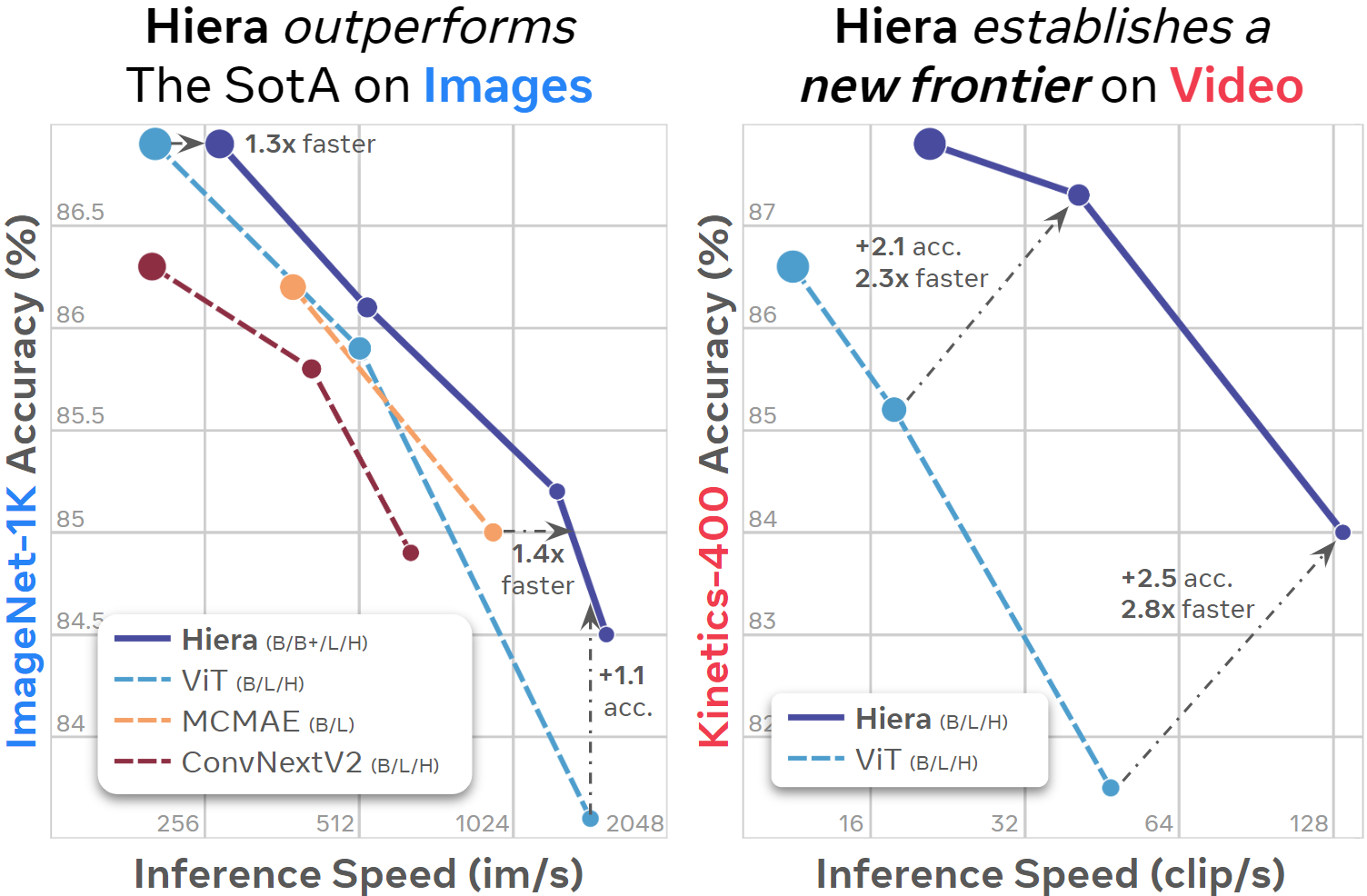
How does it work?
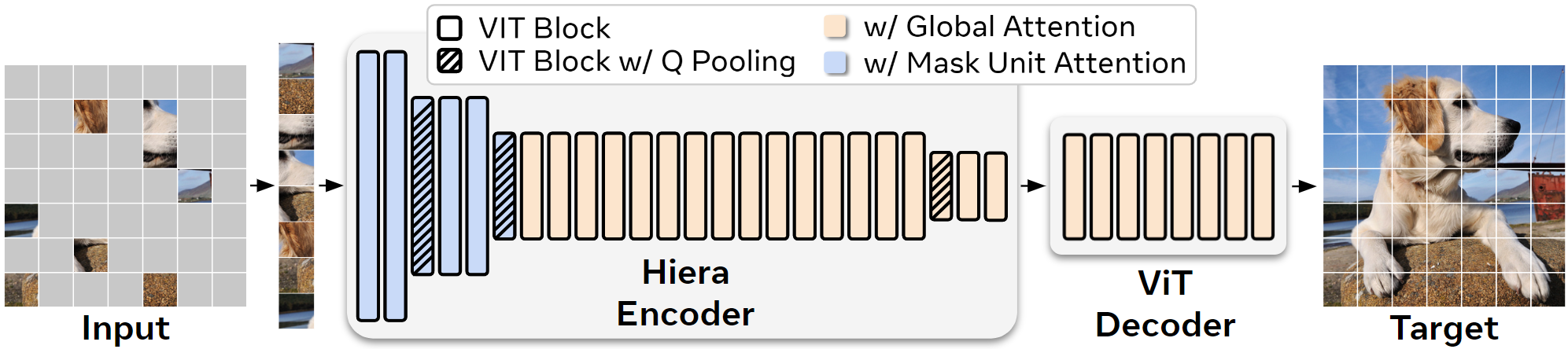
Vision transformers like ViT use the same spatial resolution and number of features throughout the whole network. But this is inefficient: the early layers don't need that many features, and the later layers don't need that much spatial resolution. Prior hierarchical models like ResNet accounted for this by using fewer features at the start and less spatial resolution at the end.
Several domain specific vision transformers have been introduced that employ this hierarchical design, such as Swin or MViT. But in the pursuit of state-of-the-art results using fully supervised training on ImageNet-1K, these models have become more and more complicated as they add specialized modules to make up for spatial biases that ViTs lack. While these changes produce effective models with attractive FLOP counts, under the hood the added complexity makes these models slower overall.
We show that a lot of this bulk is actually unnecessary. Instead of manually adding spatial bases through architectural changes, we opt to teach the model these biases instead. By training with MAE, we can simplify or remove all of these bulky modules in existing transformers and increase accuracy in the process. The result is Hiera, an extremely efficient and simple architecture that outperforms the state-of-the-art in several image and video recognition tasks.
News
- [2024.03.02] License for the code has been made more permissive (Apache 2.0)! Model license remains unchanged.
- [2023.06.12] Added more in1k models and some video examples, see inference.ipynb (v0.1.1).
- [2023.06.01] Initial release.
See the changelog for more details.
Installation
Hiera requires a reasonably recent version of torch. After that, you can install hiera through pip:
pip install hiera-transformer
This repo should support the latest timm version, but timm is a constantly updating package. Create an issue if you have problems with a newer version of timm.
Installing from Source
If using torch hub, you don't need to install the hiera package. But, if you'd like to develop using hiera, it could be a good idea to install it from source:
git clone https://github.com/facebookresearch/hiera.git
cd hiera
python setup.py build develop
Model Zoo
Note that model weights are released under a separate license than the code. See the model license for more details.
Torch Hub
Here we provide model checkpoints for Hiera. Each model listed is accessible on torch hub even without the hiera-transformer package installed, e.g. the following initializes a base model pretrained and finetuned on ImageNet-1k:
model = torch.hub.load("facebookresearch/hiera", model="hiera_base_224", pretrained=True, checkpoint="mae_in1k_ft_in1k")
If you want a model with MAE pretraining only, you can replace the checkpoint with "mae_in1k". Additionally, if you'd like to load the MAE decoder as well (e.g., to continue pretraining), add mae_ the the start of the model name, e.g.:
model = torch.hub.load("facebookresearch/hiera", model="mae_hiera_base_224", pretrained=True, checkpoint="mae_in1k")
Note: Our MAE models were trained with a normalized pixel loss. That means that the patches were normalized before the network had to predict them. If you want to visualize the predictions, you'll have to unnormalize them using the visible patches (which might work but wouldn't be perfect) or unnormalize them using the ground truth. For model more names and corresponding checkpoint names see below.
Hugging Face Hub
This repo also has 🤗 hub support. With the hiera-transformer and huggingface-hub packages installed, you can simply run, e.g.,
from hiera import Hiera
model = Hiera.from_pretrained("facebook/hiera_base_224.mae_in1k_ft_in1k") # mae pt then in1k ft'd model
model = Hiera.from_pretrained("facebook/hiera_base_224.mae_in1k") # just mae pt, no ft
to load a model. Use <model_name>.<checkpoint_name> from model zoo below.
If you want to save a model, use model.config as the config, e.g.,
model.save_pretrained("hiera-base-224", config=model.config)
Image Models
| Model | Model Name | Pretrained Models (IN-1K MAE) |
Finetuned Models (IN-1K Supervised) |
IN-1K Top-1 (%) |
A100 fp16 Speed (im/s) |
|---|---|---|---|---|---|
| Hiera-T | hiera_tiny_224 |
mae_in1k | mae_in1k_ft_in1k | 82.8 | 2758 |
| Hiera-S | hiera_small_224 |
mae_in1k | mae_in1k_ft_in1k | 83.8 | 2211 |
| Hiera-B | hiera_base_224 |
mae_in1k | mae_in1k_ft_in1k | 84.5 | 1556 |
| Hiera-B+ | hiera_base_plus_224 |
mae_in1k | mae_in1k_ft_in1k | 85.2 | 1247 |
| Hiera-L | hiera_large_224 |
mae_in1k | mae_in1k_ft_in1k | 86.1 | 531 |
| Hiera-H | hiera_huge_224 |
mae_in1k | mae_in1k_ft_in1k | 86.9 | 274 |
Each model inputs a 224x224 image.
Video Models
| Model | Model Name | Pretrained Models (K400 MAE) |
Finetuned Models (K400) |
K400 (3x5 views) Top-1 (%) |
A100 fp16 Speed (clip/s) |
|---|---|---|---|---|---|
| Hiera-B | hiera_base_16x224 |
mae_k400 | mae_k400_ft_k400 | 84.0 | 133.6 |
| Hiera-B+ | hiera_base_plus_16x224 |
mae_k400 | mae_k400_ft_k400 | 85.0 | 84.1 |
| Hiera-L | hiera_large_16x224 |
mae_k400 | mae_k400_ft_k400 | 87.3 | 40.8 |
| Hiera-H | hiera_huge_16x224 |
mae_k400 | mae_k400_ft_k400 | 87.8 | 20.9 |
Each model inputs 16 224x224 frames with a temporal stride of 4.
Note: the speeds listed here were benchmarked without PyTorch's optimized scaled dot product attention. If using PyTorch 2.0 or above, your inference speed will probably be faster than what's listed here.
Usage
This repo implements the code to run Hiera models for inference. This repository is still in progress. Here's what we currently have available and what we have planned:
- Image Inference
- MAE implementation
- Video Inference
- MAE implementation
- Full Model Zoo
- Training scripts
See examples for examples of how to use Hiera.
Inference
See examples/inference for an example of how to prepare the data for inference.
Instantiate a model with either torch hub or 🤗 hub or by installing hiera and running:
import hiera
model = hiera.hiera_base_224(pretrained=True, checkpoint="mae_in1k_ft_in1k")
Then you can run inference like any other model:
output = model(x)
Video inference works the same way, just use a 16x224 model instead.
Note: for efficiency, Hiera re-orders its tokens at the start of the network (see the Roll and Unroll modules in hiera_utils.py). Thus, tokens aren't in spatial order by default. If you'd like to use intermediate feature maps for a downstream task, pass the return_intermediates flag when running the model:
output, intermediates = model(x, return_intermediates=True)
MAE Inference
By default, the models do not include the MAE decoder. If you would like to use the decoder or compute MAE loss, you can instantiate an mae version by running:
import hiera
model = hiera.mae_hiera_base_224(pretrained=True, checkpoint="mae_in1k")
Then when you run inference on the model, it will return a 4-tuple of (loss, predictions, labels, mask) where predictions and labels are for the deleted tokens only. The returned mask will be True if the token is visible and False if it's deleted. You can change the masking ratio by passing it during inference:
loss, preds, labels, mask = model(x, mask_ratio=0.6)
The default mask ratio is 0.6 for images, but you should pass in 0.9 for video. See the paper for details.
Note: We use normalized pixel targets for MAE pretraining, meaning the patches are each individually normalized before the model model has to predict them. Thus, you have to unnormalize them using the ground truth before visualizing them. See get_pixel_label_2d in hiera_mae.py for details.
Benchmarking
We provide a script for easy benchmarking. See examples/benchmark to see how to use it.
Scaled Dot Product Attention
PyTorch 2.0 introduced optimized scaled dot product attention, which can speed up transformers quite a bit. We didn't use this in our original benchmarking, but since it's a free speed-up this repo will automatically use it if available. To get its benefits, make sure your torch version is 2.0 or above.
Training
Coming soon.
Citation
If you use Hiera or this code in your work, please cite:
@article{ryali2023hiera,
title={Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles},
author={Ryali, Chaitanya and Hu, Yuan-Ting and Bolya, Daniel and Wei, Chen and Fan, Haoqi and Huang, Po-Yao and Aggarwal, Vaibhav and Chowdhury, Arkabandhu and Poursaeed, Omid and Hoffman, Judy and Malik, Jitendra and Li, Yanghao and Feichtenhofer, Christoph},
journal={ICML},
year={2023}
}
License
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.

Contributing
See contributing and the code of conduct.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file hiera-transformer-0.1.4.tar.gz.
File metadata
- Download URL: hiera-transformer-0.1.4.tar.gz
- Upload date:
- Size: 32.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
885de17187e724098b3dc9f4a2199808415de92684c5165b55265258e31ff545
|
|
| MD5 |
e249534b5a447ae66154fbfe55f1ba73
|
|
| BLAKE2b-256 |
7cb4152a663ff3bd4739c4575470b067fee2dc08cd63a06098117f86285efd68
|
File details
Details for the file hiera_transformer-0.1.4-py3-none-any.whl.
File metadata
- Download URL: hiera_transformer-0.1.4-py3-none-any.whl
- Upload date:
- Size: 31.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d81c1f4abea8938d597f48bf09874d9b4c278bee6e303fe0132818866643a183
|
|
| MD5 |
505ed621d6fef33d77ca578b402b878f
|
|
| BLAKE2b-256 |
e4c5899bfe51e6147b73edc11b153ece8ed03eff25cb61fb2a566e3c119e22d1
|







