Python module for Hybrid Rule Lists/Black-Box models, based on the Python binding of the CORELS algorithm

Project description
HybridCORELS, a Python Module for Learning Optimal Hybrid Interpretable (Rule-Based) & Black Box models
Relevant paper: [TODO]
HybridCORELS is a Python module for learning Hybrid Rule-Based/Black-Box models, using modified versions of the CORELS algorithm for the rule-based part learning. It is based on the CORELS Python binding, PyCORELS.
Both our proposed algorithms provide optimality guarantees and allow direct control of the desired transparency level (proportion of examples classified by the interpretable part of the hybrid interpretable model).
If you encounter any issue when using this module please either open a ticket here or email jferry@laas.fr.
This package is joint work between Julien Ferry, Gabriel Laberge and Ulrich Aïvodji.
Learning Optimal Hybrid Interpretable Models with Fixed Transparency Level
Hybrid interpretable models are predictive models formed by an interpretable and a black-box part. The interpretable part makes predictions, and the black-box handles the examples not captured by the later. Hereafter are two examples of such models learnt on the exact same data using the two methods proposed within this module:
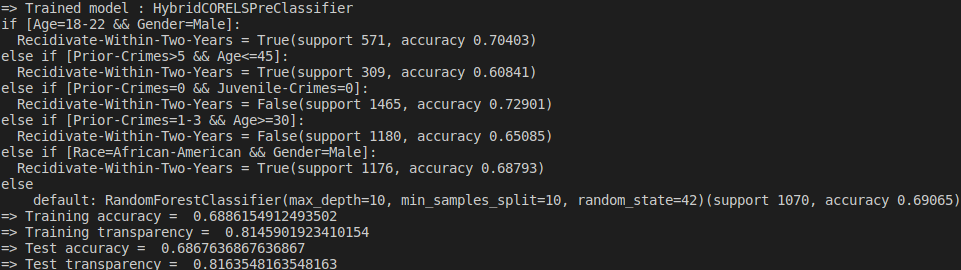
Example Hybrid Model learnt on the COMPAS dataset using HybridCORELSPre (minimum desired transparency 0.8) along with a standard sklearn RandomForest as black-box model (example_HybridCORELSPre.py script).
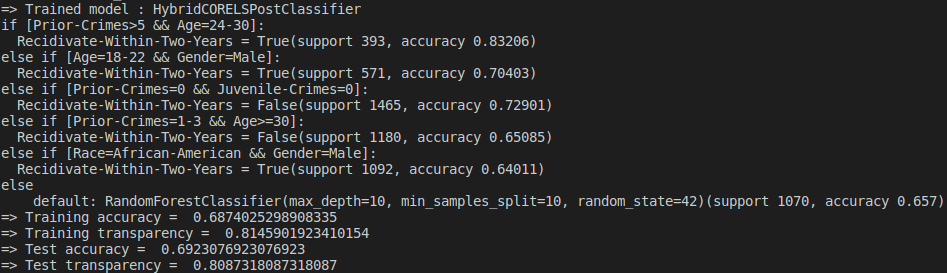
Example Hybrid Model learnt on the COMPAS dataset using HybridCORELSPost (minimum desired transparency 0.8) along with a standard sklearn RandomForest as black-box model (example_HybridCORELSPost.py script).
This module contains our two proposed algorithms introduced in Section 4 of our paper. They implement the two hybrid interpretable models learning paradigms identified in Section 3.1:
-
HybridCORELSPreClassifieruses the Pre-Black-Box paradigm: the interpretable part of the Hybrid model is trained first, using a modified version of the CORELS algorithm. Given a desired minimum transparency level, the algorithm returns the certifiaby optimal prefix, minimizing the overall model classification error lower bound. Then, a BB model is trained to perform well on the remaining examples. The BB can then be specialized on such examples. In this case, optimality is certified for the interpretable part alone, which is guaranteed to have the best objective function given the coverage constraint. The intuition for this type of approach is to handle the "easy" examples using the interpretable part of the model, and leverage the black-box complexity to classify the hardest ones. -
HybridCORELSPostClassifieruses the Post-Black-Box paradigm: the BB part of the Hybrid model is trained first. Then, the interpretable part is trained, using a modified version of the CORELS algorithm. Given a desired minimum transparency level, along with the BB predictions, the algorithm returns the certifiaby optimal prefix. Because it is trained after the BB, the interpretable part is able to correct its mistakes. In this case, optimality is certified for the interpretable part, but regarding the overall model's predictions. Indeed, the overall model is guaranteed to have the best objective function given the coverage constraint and the black-box mistakes.
Installation
Two options are possible:
- installation from source: clone this repository and do
python setup.py install - via the PyPi project (TODO):
pip install HybridCORELS
Organization of the Repository
Folder HybridCORELS contains the code for our module.
Folder paper contains all the code we used to perform the experiments and plots presented in our paper.
It also contains the raw results for our large-scale experiments. All the scripts needed to treat them and generate the Figures are provided.
Raw results for Section 5.2 (Exploring the Pre-Black-Box Paradigm) are provided within paper/results_part_3_collab.zip.
Raw results for Section 5.3 (Tradeoffs and Comparison with the State of the Art) are provided within paper/results_part_4.zip.
Raw results for the Appendix C.2 (HybridCORELSPre,NoCollab: Empirical Evaluation) are provided within paper/results_part_3.zip.
Folder examples contains example uses of our different methods. The example_HybridCORELSPre.py script trains a HybridCORELSPreClassifier, displays it and evaluates it on a test set. The example_HybridCORELSPost_pretrained_black_box.py (respectively, example_HybridCORELSPost.py) script does the same using a HybridCORELSPostClassifier with a given pretrained black-box model (respectively, with no given pretrained black-box).
IMPORTANT: in the data folders (within ./examples or ./paper) the only dataset ready to use is compas_mined.csv.
For Adult and ACS Employment, the rules must first be mined from the raw datasets before experiments can be run.
This is due to the large size of the mined datasets, which do not fit on the repository.
You can easily generate the mined versions for all datasets with python run_rules_mining.py within the paper folder.
Hereafter is a minimal running example (requiring the scikit-learn library as a sklearn.ensemble.RandomForestClassifier() will be used by default as black-box part) that should be launched from the examples folder:
from HybridCORELS import *
# Load data
X, y, features, prediction = load_from_csv("./data/compas_mined.csv")
# Define a hybrid model that will use the Pre-Black-Box training paradigm
# We want a transparency greater than 80%
# We set max_card to 1 as rule mining is already done in our dataset
hyb_model = HybridCORELSPreClassifier(min_coverage=0.8, max_card=1)
# Trains it
hyb_model.fit(X, y, features=features, prediction_name=prediction, time_limit=60, memory_limit=4000)
# Displays it
print(hyb_model)
Expected output:
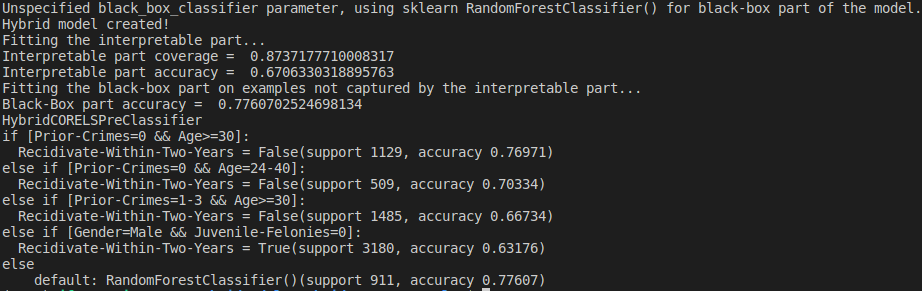
Example Hybrid Model learnt on the COMPAS dataset using HybridCORELSPre (minimum desired transparency 0.8) along with a standard sklearn RandomForest as black-box model (minimal running example provided in this README).
This minimal example also works replacing HybridCORELSPreClassifier by HybridCORELSPostClassifier, to learn hybrid interpretable models using the Post-Black-Box paradigm.
Detail of the Methods' Hyperparameters
HybridCORELSPreClassifier
Classifier Object Hyperparameters
-
obj_mode: Type of learning objective for the Pre-Black-Box paradigm. If 'collab', maximizes (prefix accuracy + BB accuracy UB) - i.e., takes care of the inconsistent examples let to the BB part (as in Section 4.4 of our paper). If 'no_collab', only maximizes the prefix's accuracy (as in the Appendix C of our paper) (default: 'collab')
-
black_box_classifier: user-provided object for the black-box part of the interpretable model - note that this classifier object must follow sklearn naming conventions, and in particular implement the .fit() method with cost-sensitive training (i.e., the
sample_weightparameter). It does not need to be trained as it will be trained automatically after learning the interpretable part (default: sklearn.ensemble.RandomForestClassifier()) -
alpha: black-box specialization coefficient (used to weight the black-box training set) (default: 0.0 (i.e., no specialization))
-
beta: float, regularization hyperparameter weighting transparency in the objective function. When using the min_coverage hard constraint, we recommend to set beta < 1/n_samples <= c (default: 0.0)
-
min_coverage: float (between 0.0 and 1.0), minimum acceptable value for the hybrid model transparency (proportion of examples classified by the interpretable part of the model) (default 0.0 (i.e., no constraint))
-
Arguments of the original CORELS algorithm (see PyCORELS documentation for more details)
- c: regularization coefficient for sparsity ($\lambda$) (default: 0.001)
- n_iter: maximum number of nodes in the prefix tree (default: 10**7) - because we now offer precise control over the memory use we suggest to set this parameter to a very high value and control the memory use using the
memory_limitargument of the.fit()method - map_type: type of map used to cut down the prefix tree symmetries (default: "prefix")
- policy: ordering criterion for the priority queue (defines in which order the prefix tree will be explored) (default: "lower_bound")
- verbosity: list of required verbosity levels. Among others, "rulelist" prints the trained rule list when finished, "progress" displays information about the search, "mine" shows the mined rules and "hybrid" (new possible value) prints information regarding the Hybrid model learning framework (default: ["hybrid"])
- ablation: indicates which bounds to use while searching (default: 0 (all bounds))
- max_card: maximum rules cardinality (number of involved attributes) (default: 2). When dealing when pre-mined rules, this parameter should be set to 1
- min_support: minimum support that rules must have in order to be used (default: 0.01)
Fit Method Hyperparameters
-
X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8.
-
y : array-line, shape = [n_samples] The target values for the training input. Must be binary.
-
features : list, optional(default=[]) A list of strings of length n_features. Specifies the names of each of the features. If an empty list is provided, the feature names are set to the default of ["feature1", "feature2"... ].
-
prediction_name : string, optional(default="prediction") The name of the feature that is being predicted.
-
time_limit : int, maximum number of seconds allowed for the model building (this timeout considers only the interpretable part building using the modified CORELS algorithm). Note that this specifies the CPU time and NOT THE WALL-CLOCK TIME (default: None (i.e., no limit))
-
memory_limit: int, maximum memory use (in MB) (this memory limit considers only the interpretable part building using the modified CORELS algorithm) (default: None (i.e., no limit))
Other Methods
Prediction Methods:
-
predict(self, X): Returns the model's predictions for inputs X
- X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8. The features must be the same as those of the data used to train the model.
- Returns:
- array of shape = [n_samples]
-
predict_proba(self, X): Returns the model's class probabilities for inputs X (computed using each rule's training support set accuracy)
- X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8. The features must be the same as those of the data used to train the model.
- Returns:
- array of shape = [n_samples]
-
predict_with_type(self, X): Returns the model's predictions for inputs X, along with a boolean (one per example) indicating whether the example was classified by the interpretable part of the model or not
- X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8. The features must be the same as those of the data used to train the model.
- Returns:
- p, t : array of shape = [n_samples], array of shape = [n_samples]
- p: The classifications of the input samples
- t: The part of the Hybrid model which decided for the classification (1: interpretable part, 0: black-box part)
- p, t : array of shape = [n_samples], array of shape = [n_samples]
-
score(self, X, y): Computes the hybrid interpretable model's accuracy on the provided dataset
- X : array-like, shape = [n_samples, n_features] OR shape = [n_samples] The input samples, or the sample predictions. All features must be binary.
- y : array-like, shape = [n_samples] The input labels. All labels must be binary.
Loading/Saving Methods:
-
load(fname): Class Method to load a previously trained HybridCORELSPreClassifier from a file, using python's pickle module.
- fname : string, File name to load the hybrid model from
- Example use:
hybrid_model = HybridCORELSPreClassifier.load("test_save_load")
-
save(self, fname): Saves this HybridCORELSPreClassifier to a file, using python's pickle module.
- fname : string, File name to save the hybrid model in
- Example use:
hybrid_model.save("test_save_load")
Others:
-
refit_black_box(self, X, y, alpha, black_box_classifier): To only retrain the black-box part (using a new, provided black-box) of a trained hybrid interpretable model
- X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8.
- y : array-line, shape = [n_samples] The target values for the training input. Must be binary.
- alpha : float or int, new specialization coefficient value
- black_box_classifier: classifier to be used as the black-box (will be trained)
-
str(self): Get a textual representation of the hybrid interpretable model
-
get_sparsity(self): Returns the number of rules within the learnt prefix
-
get_status(self): Returns the status of the training. Can be:
- "exploration running" if the training is being performed
- "not_fitted" if the training has not been launched yet
- "time_out" if the training stopped because provided time limit was reached
- "memory_out" if the training stopped because provided memory limit was reached
- "max_nodes_reached" if the training stopped because provided maximum number of nodes within the cache (prefix tree) was reached
- "opt" is the training reached and proved optimality
- "exploration_not_started" if the training was initiated (call to the C++ core algorithm via Cython) but did not begin yet
- "unknown" if something went wrong (should not happen)
HybridCORELSPostClassifier
Classifier Object Hyperparameters
-
black_box_classifier: user-provided object for the black-box part of the interpretable model - note that this classifier object must follow sklearn naming conventions. If it is already trained, this must be indicated using the bb_pretrained parameter (see hereafter). (default: sklearn.ensemble.RandomForestClassifier())
-
bb_pretrained : boolean indicating whether the given black_box_classifier is already trained or not. (default=False) If False, the BB will be trained while calling the
fitmethod. If True, we check whether it is effectively fitted. -
beta: float, regularization hyperparameter weighting transparency in the objective function. When using the min_coverage hard constraint, we recommend to set beta < 1/n_samples <= c (default: 0.0)
-
min_coverage: float (between 0.0 and 1.0), minimum acceptable value for the hybrid model transparency (proportion of examples classified by the interpretable part of the model) (default 0.0 (i.e., no constraint))
-
Arguments of the original CORELS algorithm (see PyCORELS documentation for more details)
- c: regularization coefficient for sparsity ($\lambda$) (default: 0.001)
- n_iter: maximum number of nodes in the prefix tree (default: 10**7) - because we now offer precise control over the memory use we suggest to set this parameter to a very high value and control the memory use using the
memory_limitargument of the.fit()method - map_type: type of map used to cut down the prefix tree symmetries (default: "prefix")
- policy: ordering criterion for the priority queue (defines in which order the prefix tree will be explored) (default: "lower_bound")
- verbosity: list of required verbosity levels. Among others, "rulelist" prints the trained rule list when finished, "progress" displays information about the search, "mine" shows the mined rules and "hybrid" (new possible value) prints information regarding the Hybrid model learning framework (default: ["hybrid"])
- ablation: indicates which bounds to use while searching (default: 0 (all bounds))
- max_card: maximum rules cardinality (number of involved attributes) (default: 2). When dealing when pre-mined rules, this parameter should be set to 1
- min_support: minimum support that rules must have in order to be used (default: 0.01)
Fit Method Hyperparameters
-
X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8.
-
y : array-line, shape = [n_samples] The target values for the training input. Must be binary.
-
features : list, optional(default=[]) A list of strings of length n_features. Specifies the names of each of the features. If an empty list is provided, the feature names are set to the default of ["feature1", "feature2"... ].
-
prediction_name : string, optional(default="prediction") The name of the feature that is being predicted.
-
time_limit : int, maximum number of seconds allowed for the model building (this timeout considers only the interpretable part building using the modified CORELS algorithm). Note that this specifies the CPU time and NOT THE WALL-CLOCK TIME (default: None (i.e., no limit))
-
memory_limit: int, maximum memory use (in MB) (this memory limit considers only the interpretable part building using the modified CORELS algorithm) (default: None (i.e., no limit))
Other Methods
Prediction Methods:
-
predict(self, X): Returns the model's predictions for inputs X
- X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8. The features must be the same as those of the data used to train the model.
- Returns:
- array of shape = [n_samples]
-
predict_proba(self, X): Returns the model's class probabilities for inputs X (computed using each rule's training support set accuracy)
- X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8. The features must be the same as those of the data used to train the model.
- Returns:
- array of shape = [n_samples]
-
predict_with_type(self, X): Returns the model's predictions for inputs X, along with a boolean (one per example) indicating whether the example was classified by the interpretable part of the model or not
- X : array-like, shape = [n_samples, n_features] The training input samples. All features must be binary, and the matrix is internally converted to dtype=np.uint8. The features must be the same as those of the data used to train the model.
- Returns:
- p, t : array of shape = [n_samples], array of shape = [n_samples]
- p: The classifications of the input samples
- t: The part of the Hybrid model which decided for the classification (1: interpretable part, 0: black-box part)
- p, t : array of shape = [n_samples], array of shape = [n_samples]
-
score(self, X, y): Computes the hybrid interpretable model's accuracy on the provided dataset
- X : array-like, shape = [n_samples, n_features] OR shape = [n_samples] The input samples, or the sample predictions. All features must be binary.
- y : array-like, shape = [n_samples] The input labels. All labels must be binary.
Loading/Saving Methods:
-
load(fname): Class Method to load a previously trained HybridCORELSPostClassifier from a file, using python's pickle module.
- fname : string, File name to load the hybrid model from
- Example use:
hybrid_model = HybridCORELSPostClassifier.load("test_save_load")
-
save(self, fname): Saves this HybridCORELSPostClassifier to a file, using python's pickle module.
- fname : string, File name to save the hybrid model in
- Example use:
hybrid_model.save("test_save_load")
Others:
-
str(self): Get a textual representation of the hybrid interpretable model
-
get_sparsity(self): Returns the number of rules within the learnt prefix
-
get_status(self): Returns the status of the training. Can be:
- "exploration running" if the training is being performed
- "not_fitted" if the training has not been launched yet
- "time_out" if the training stopped because provided time limit was reached
- "memory_out" if the training stopped because provided memory limit was reached
- "max_nodes_reached" if the training stopped because provided maximum number of nodes within the cache (prefix tree) was reached
- "opt" is the training reached and proved optimality
- "exploration_not_started" if the training was initiated (call to the C++ core algorithm via Cython) but did not begin yet
- "unknown" if something went wrong (should not happen)
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file HybridCORELS-0.53.tar.gz.
File metadata
- Download URL: HybridCORELS-0.53.tar.gz
- Upload date:
- Size: 144.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c082d93341e47a29c9358516b180951eb210a6aa9cbc291f51b2c8a85f25b75f
|
|
| MD5 |
5b7c16e493ba6d21fed52e84ef28e72e
|
|
| BLAKE2b-256 |
75c41a14fbb12ef720aae6c2ae7db25b97d7c32837e7a01f332115da610294c1
|







