Open-source Python toolkit for building Vietnamese AI applications.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Nôm 喃
Open-source Python toolkit for building Vietnamese AI applications.
Named after chữ Nôm — the script Vietnam wrote in for a millennium.




A local-first toolkit. No data leaves your machine. Use any LLM (Ollama by default), any embedder, any document type — Nôm wires them into a Vietnamese-aware RAG pipeline you can ship as either a Python library or a deployable chat web app.
Every default is benched on real Vietnamese data. Where a public Apache/MIT model beats a multilingual one, we use it. See docs/benchmark.md for the receipts.
The 3-line demo
pip install "nom-vn[chat]" # FastAPI + React UI + parsers + embeddings
nom serve # opens http://localhost:8080
# upload PDFs/Word/Excel/PowerPoint/images, ask questions in Vietnamese
The web app is built into the wheel — there's nothing else to install. As of
v0.2.30 it's a full playground: chat-with-RAG plus stateless tool pages
for diacritic restore (rule / HF seq2seq / LLM backends), word + sentence
segmentation, NFC normalize + VN detect, strip-diacritics, and a reproducible
noise generator for training. Cmd/Ctrl + Enter runs from anywhere.
Recommended stack — measured 2026-05-02
Every recommendation has a measured number from a script in
benchmarks/ that runs on a clean clone. No projected
numbers. No "based on the model card." Numbers came out of our hardware,
on real Vietnamese corpora, this week.
| Task | Pick | License | Disk | Measured | Beats |
|---|---|---|---|---|---|
| Spell correction (recommended default) → | nrl-ai/vn-spell-correction-base v0.2.29 (ViT5 220 M, ours) |
Apache 2.0 | 900 MB | 98.32 % light avg synthetic · 79.62 % OOD aggregate | #1 on real-world OOD — beats Toshiiiii1 +2.22 pp, bmd1905 +30.41 pp; fixes typos + accents + OCR + Telex errors in one pass |
| Spell correction (fast tier) → | nrl-ai/vn-spell-correction-small v0.2.29 (BARTpho-syllable 115 M, ours) |
Apache 2.0 | 530 MB | 94.59 % light avg synthetic · 77.55 % OOD aggregate | half the params of base, ~3× faster; still beats Toshiiiii1 on OOD aggregate |
| Spell correction (edge / browser / mobile) → | nrl-ai/vn-spell-correction-base-onnx-int8 (ONNX int8, ours) |
Apache 2.0 | 438 MB | 78.76 % OOD aggregate | base model dynamic int8 quantized; 51 % smaller, no PyTorch; still beats Toshiiiii1 +1.36 pp |
| Spell correction (smallest) → | nrl-ai/vn-spell-correction-small-onnx-int8 (ONNX int8, ours) |
Apache 2.0 | 307 MB | 77.30 % OOD aggregate | smallest tier still beating Toshiiiii1; onnxruntime-web / -mobile ready |
| Diacritic restoration (formal text only) → | nrl-ai/vn-diacritic-vit5-base v0.2.29 (ViT5 220 M, ours) |
Apache 2.0 | 900 MB | 99.52 % formal · 96.14 % business · 94.16 % conversational · 89.97 % literary | for input known to be strip-only ASCII (legal docs, ASCII pipes); spell-correction-base is the universal default |
| Diacritic restoration (fast tier) → | nrl-ai/vn-diacritic-small (BARTpho-syllable 115 M, ours) |
Apache 2.0 | 530 MB | 94.44 % business · 86.33 % literary · 90.68 % conv · 91.51 % formal · ~50-100 ms/sent | half the params of the base, ~2× faster |
| Diacritic (zero-dep fallback) | rule-based table (nom.text.fix_diacritics) |
Apache 2.0 | 0 | 41.06 % word acc · <1 ms | — |
| Diacritic (local LLM) | gemma4:e4b Q4 via Ollama |
Apache 2.0 | 9.6 GB | 93.18 % business-mixed · 92.71 % formal · 87.91 % conv · 77.78 % literary · 0.88 s p50 GPU | gemma3:4b (-3 to -16 pp depending on register, 3 GB smaller); qwen3:1.7b 16.60 % (sub-rule-baseline). Best local LLM in the lineup — only 5-12 pp behind our ViT5 fine-tune. |
| Word segmentation (speed) | nom.text.word_tokenize (rule, zero deps) |
Apache 2.0 | 0 | F1 76.46 % · 747 k tok/s | — |
| Word segmentation (quality) | underthesea 9.4.0 (CRF, opt-in) |
Apache 2.0 | <10 MB | F1 95.70 % · 38 k tok/s | matches its own published VLSP 2013 numbers |
| OCR (printed clean lines) → | Tesseract 5 + vie traineddata |
Apache 2.0 | ~30 MB | CER 0.00 % clean · 0.70 % noisy · 30.34 % hard scan · 80 ms p50 | EasyOCR (1.42/4.87/87.09 %), VietOCR (1.41/3.37/29.00 %), PaddleOCR PP-OCRv5 (24.70/31.33/86.13 %), RapidOCR (63.97/77.83/100 %) |
| OCR (handwritten lines) → | VietOCR vgg_transformer (pbcquoc/vietocr) |
Apache 2.0 | ~110 MB | CER 31.82 % on brianhuster/VietnameseOCRdataset test 200 · 246 ms p50 GPU |
Tesseract (69.34 %), PaddleOCR PP-OCRv5 (59.43 %, no VN-specific recognizer), TrOCR-handwritten EN-only (75.89 %), EasyOCR (71.52 %) |
| PDF text extraction | pypdfium2 (BSD-3 wrap of PDFium Apache-2.0) |
BSD-3 / Apache | <10 MB | 99.81 % char overlap · 2.35 M chars/s | pdfplumber (51 k chars/s), Docling (15 k chars/s) |
| Dense embedder (RAG retrieval) | bkai-foundation-models/vietnamese-bi-encoder (opt-in) |
Apache 2.0 | 383 MB | R@1 76.25 % · R@10 98.75 % on Zalo Legal QA 5 k | dangvantuan/vietnamese-embedding (35.00 % R@1) by +41.25 pp |
| Dense embedder (default, cache-stable) | dangvantuan/vietnamese-embedding |
Apache 2.0 | 440 MB | R@1 35.00 % on Zalo Legal QA 5 k | — |
| Reranker | BAAI/bge-reranker-v2-m3 |
Apache 2.0 | ~2 GB | R@1 86.3 % paired w/ dense (Zalo Legal 5 k) | namdp-ptit/ViRanker (85.0 %) |
| BM25 | bm25s (Lucene-formula) |
MIT | <10 MB | R@1 76.2 % on Zalo Legal 5 k · 0.7 ms/query | 607× faster than v0.2.5 pure-Python implementation |
The decision in plain English:
- Want VN diacritics fixed? Install
nom-vn[diacritic-hf]and use the default —nrl-ai/vn-diacritic-vit5-base. Wins on formal + conversational + business + literary against the public landscape; the-smallvariant trades 4 pp for ~3× speed. - Want spell correction (typos + accents + OCR errors in one pass)? Same install, swap the model id to
nrl-ai/vn-spell-correction-base. Beatsbmd1905/vietnamese-correction-v2by 11-25 pp. - Care about real-world (not just synthetic) accuracy? Read the out-of-distribution OOD bench — 150 hand-curated real Vietnamese typos across 6 registers, with bootstrap 95 % CI. Headline (v0.2.29): synthetic 98.32 % light avg, OOD aggregate 79.62 % — beats
Toshiiiii1(77.40 %) andbmd1905(49.21 %). - Want local RAG over Vietnamese documents? Install
nom-vn[chat,embeddings,nlp], swap the default embedder toBKaiEmbedder. +41 pp R@1. - Need OCR on Vietnamese scans? Two answers depending on what you have: Tesseract
vieis the right call for printed lines (0.00 % CER on clean printed). VietOCR is the right call for handwriting (31.82 % CER vs Tesseract 69.34 % — the 37.5 pp gap is the biggest single OCR finding in the repo). PaddleOCR PP-OCRv5 ranks 3rd everywhere because it ships no VN-specific recognizer;lang='vi'loads genericlatin_PP-OCRv5_mobile_recwhich strips diacritics. Don't reach for VLM OCR on tight line crops — VLMs hallucinate at line scale (use a VLM only when you have full-document context like forms or invoices). - Need PDF text extraction in a license-clean way? Use
pypdfium2(we ship it). Skip PyMuPDF — its AGPL forces every downstream into AGPL.
What ships today
| Module | What it does | Status |
|---|---|---|
nom.text |
NFC normalize, rule diacritic restoration, word tokenization. Also: HFDiacriticModel (Toshiiiii1 T5, 97.81 %, opt-in) |
✅ |
nom.chunking |
VN-aware document chunking | ✅ |
nom.embeddings |
Embedder Protocol + VietnameseEmbedder (default) + BKaiEmbedder (recommended, retrieval-trained) + AITeamVNEmbedder (BGE-M3 ft) |
✅ |
nom.retrieve |
BM25Retriever (bm25s, 607× faster than v0.2.5), DenseRetriever, hybrid RRF fusion |
✅ |
nom.doc |
PDF (pypdfium2 46× faster than pdfplumber) / DOCX / XLSX / PPTX / HTML / image (Tesseract OCR) → text |
✅ |
nom.llm |
LLM Protocol + Ollama adapter (default think=False) + OpenAI + Anthropic |
✅ |
nom.rag |
One-line RAG composition + cross-encoder reranker (BAAI/bge-reranker-v2-m3) |
✅ |
nom.chat |
FastAPI server + React/ShadCN UI, MemoryStore + SqliteStore + pluggable EmbeddingsCache |
✅ |
Multi-task playground web app (since v0.2.30)
Left rail switches between chat (RAG over your docs) and stateless tools — diacritic restore, tokenize, normalize/detect, strip diacritics, noise generator — plus a Settings page (server health, bearer-token auth, LLM backend picker, default top_k) and an API & Setup page (cURL examples + setup commands for Ollama / llama.cpp / HuggingFace / OpenAI / Anthropic). Editorial palette, sharp corners, full keyboard navigation (Cmd/Ctrl + Enter runs the active tool, gear icon top-right opens Settings).
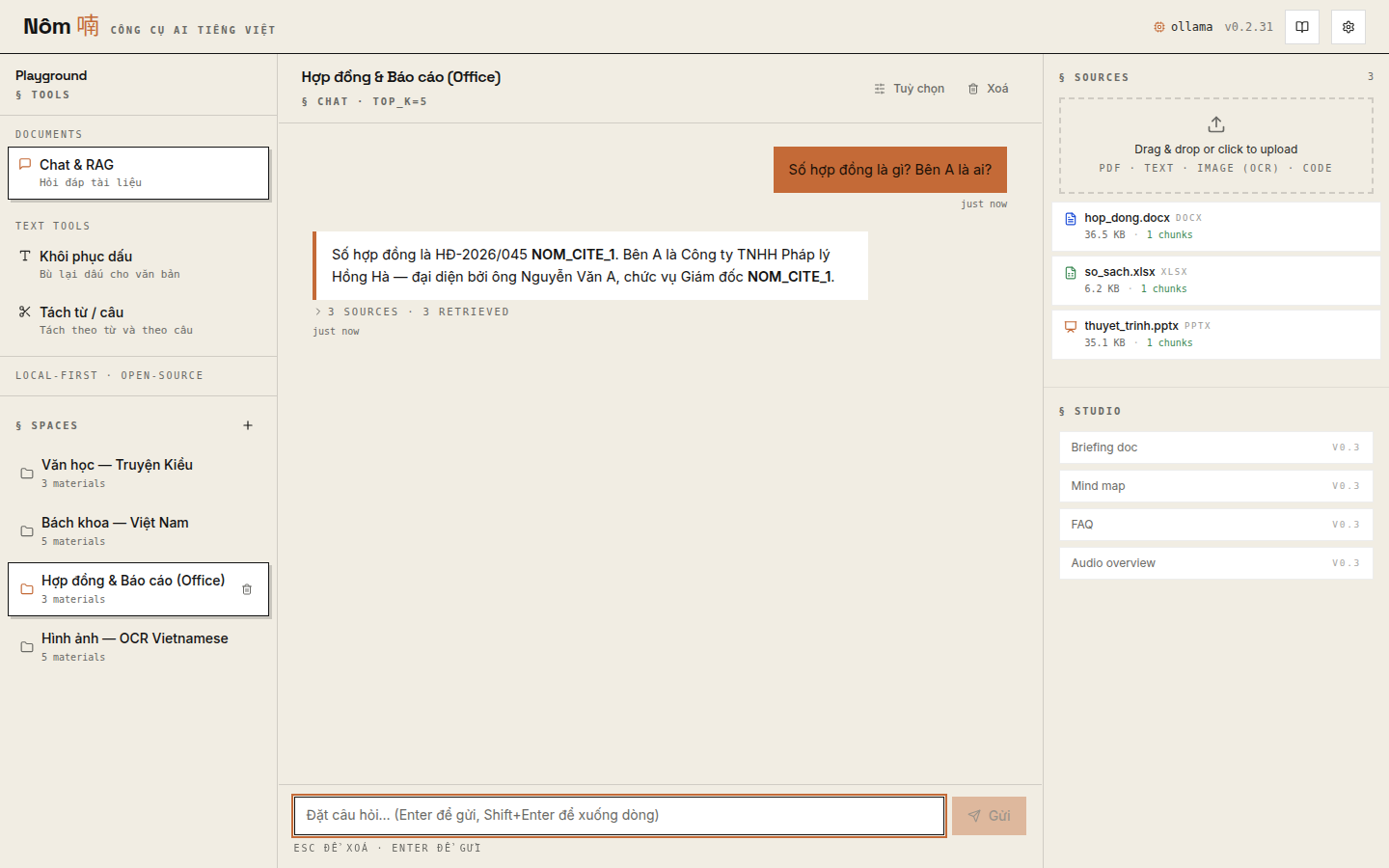
Chat with citations grounded in indexed Vietnamese documents:
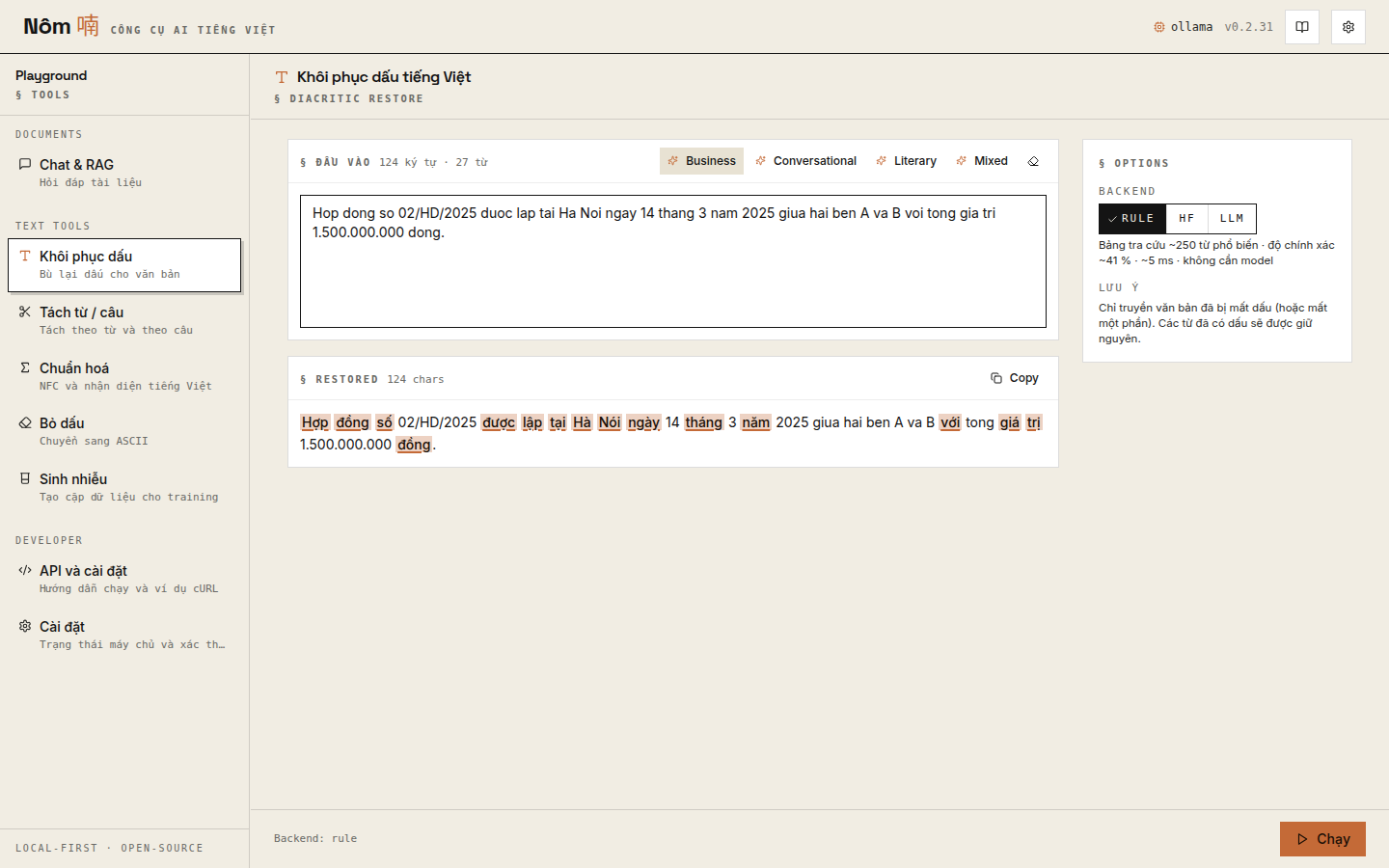
Diacritic-restore tool with backend picker (rule / HF seq2seq / LLM) and per-word change highlighting:
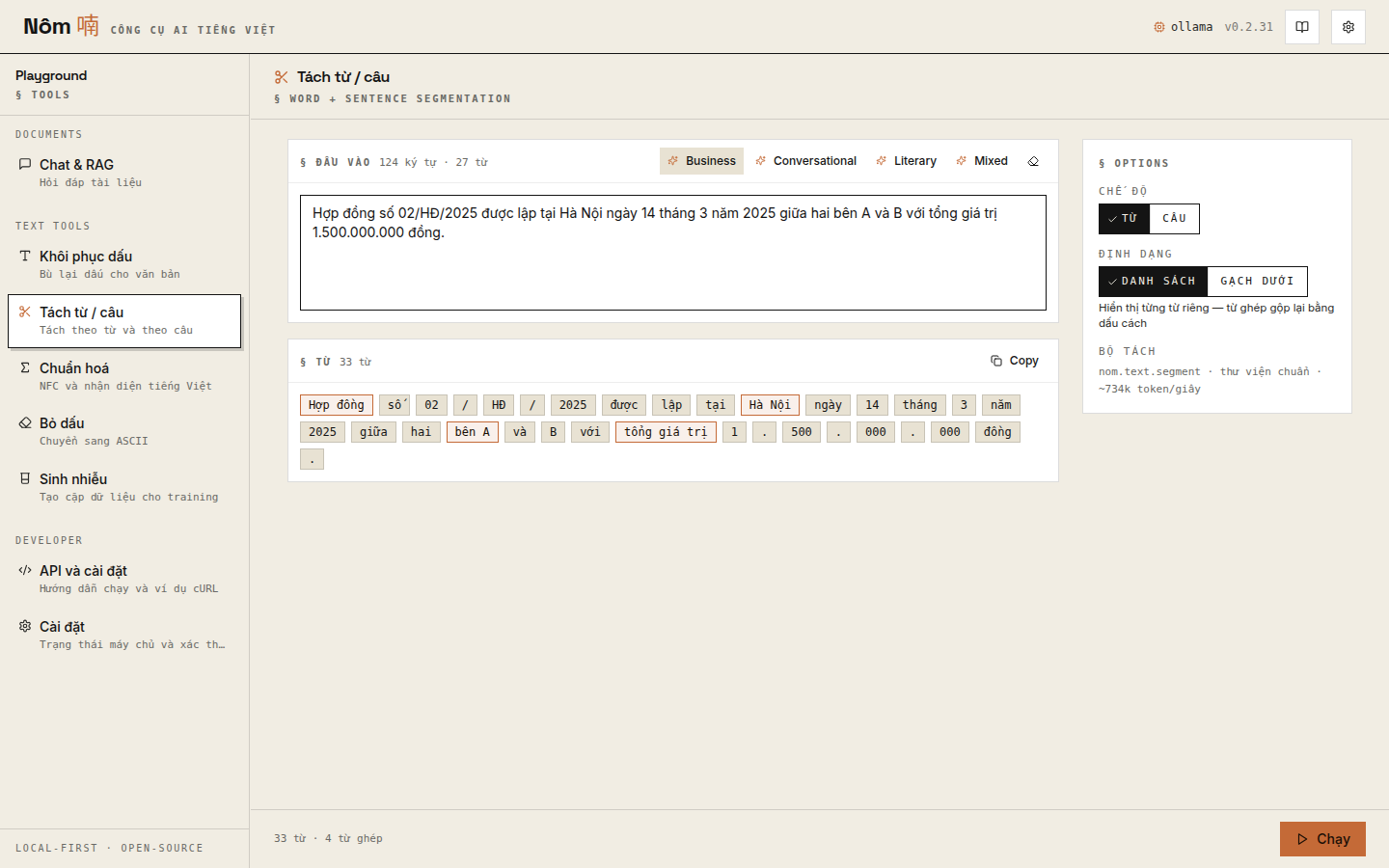
Word + sentence segmentation with compound highlighting:
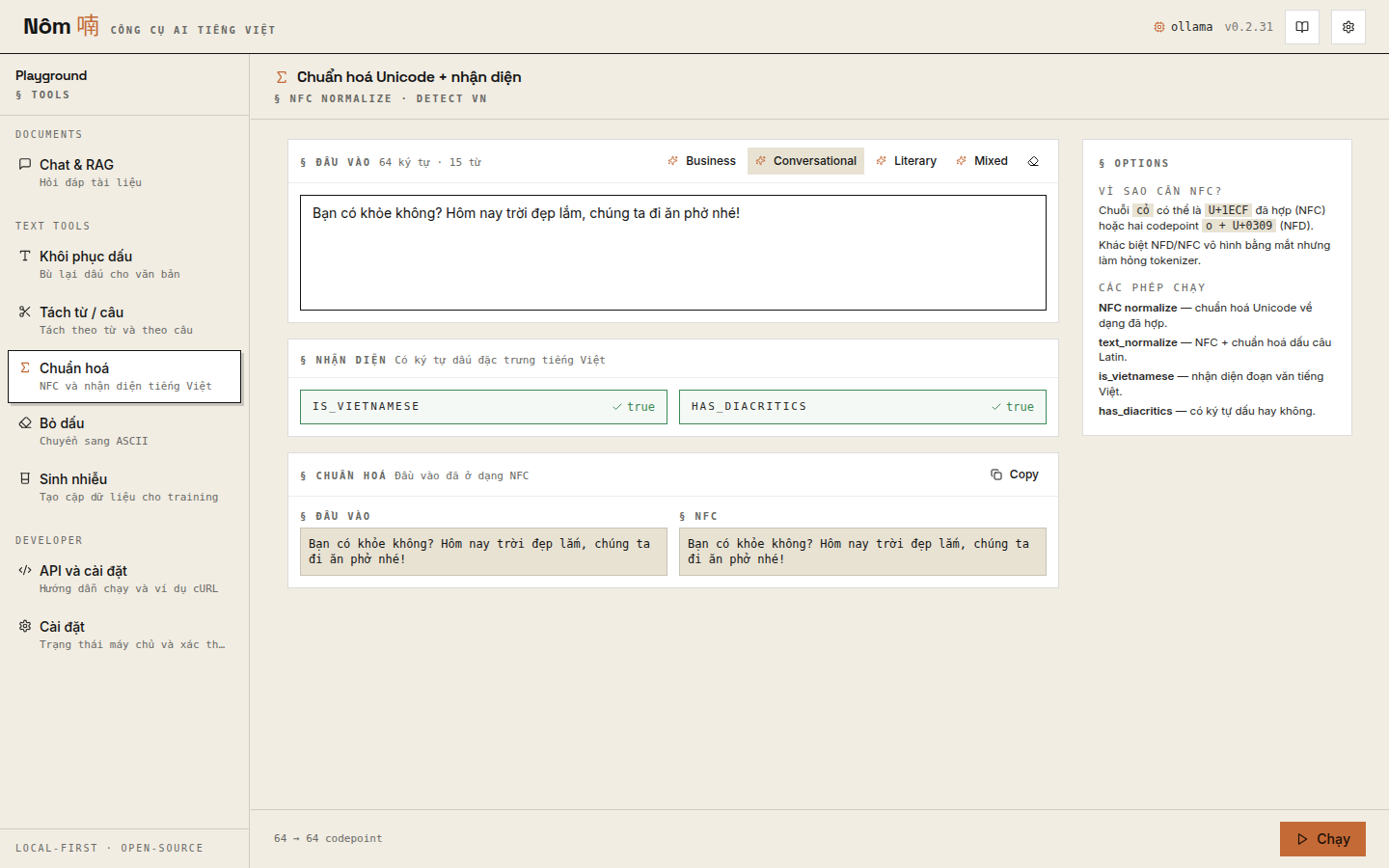
NFC normalize + Vietnamese detection:
Reproducible noise generator for training (noisy → clean pairs) — pick a preset, set a seed, run:

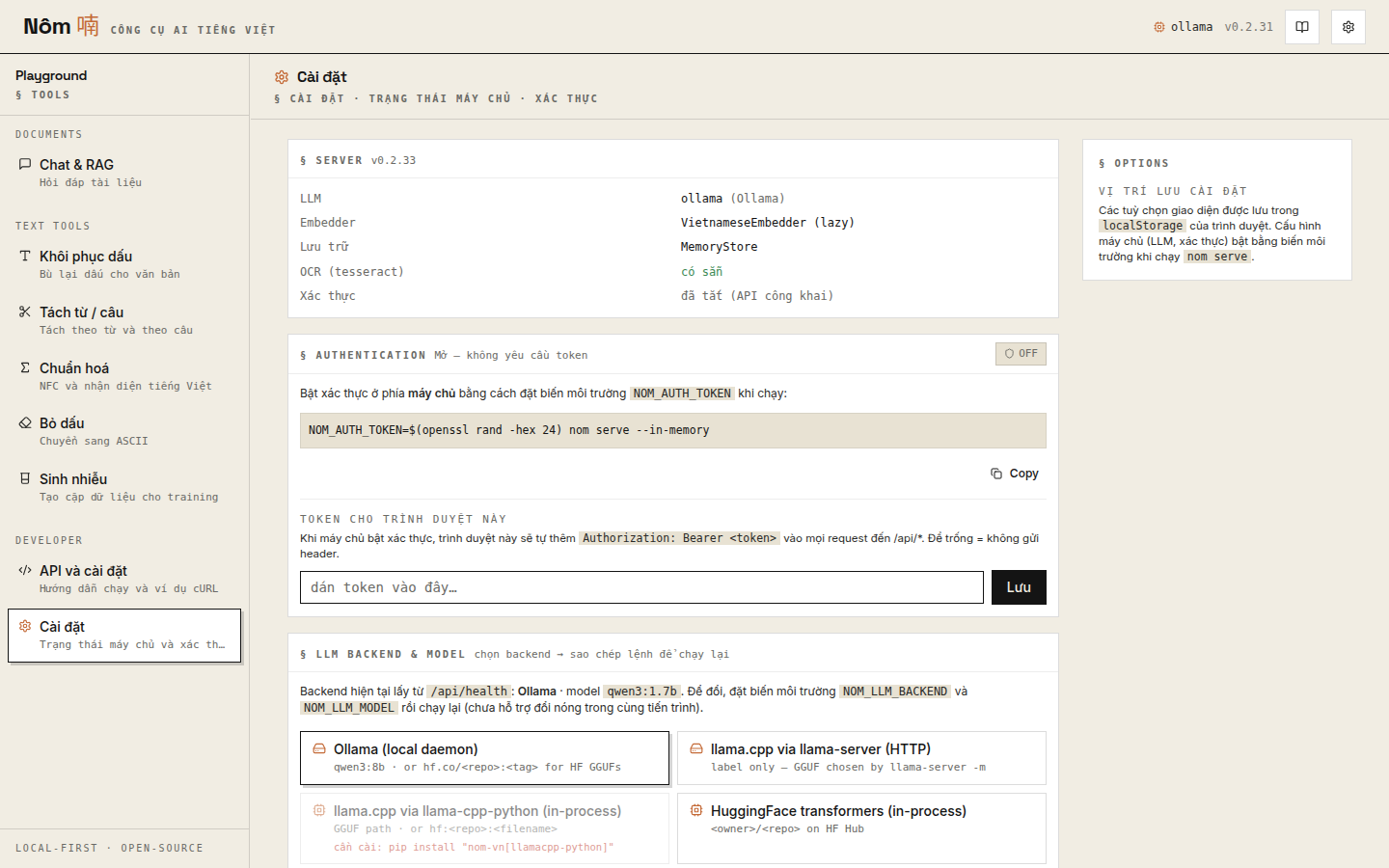
Settings page — server health, authentication toggle, LLM backend picker that emits a copy-paste launch command:
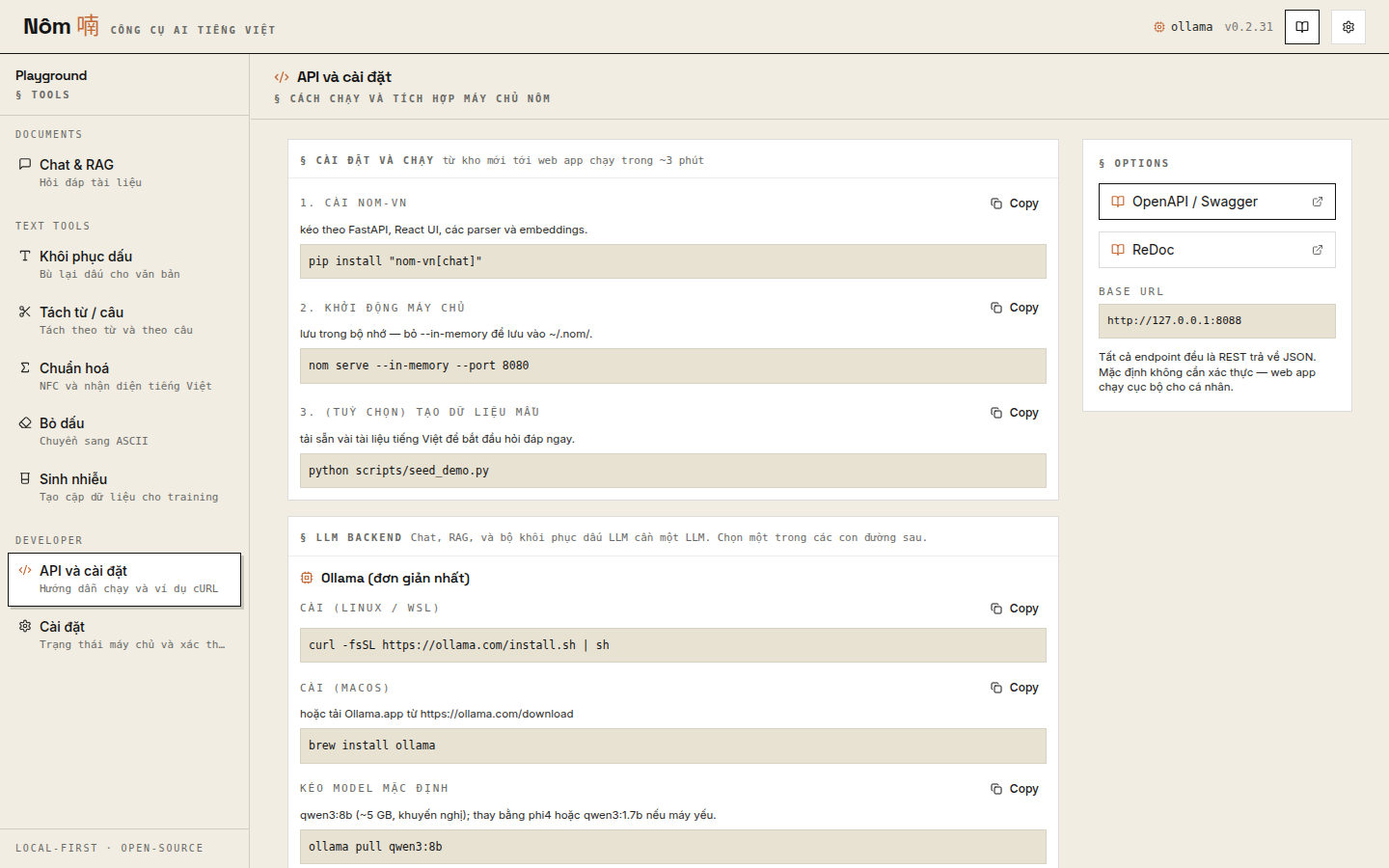
API & Setup page — Vietnamese-language install/run guide and cURL examples for every endpoint:
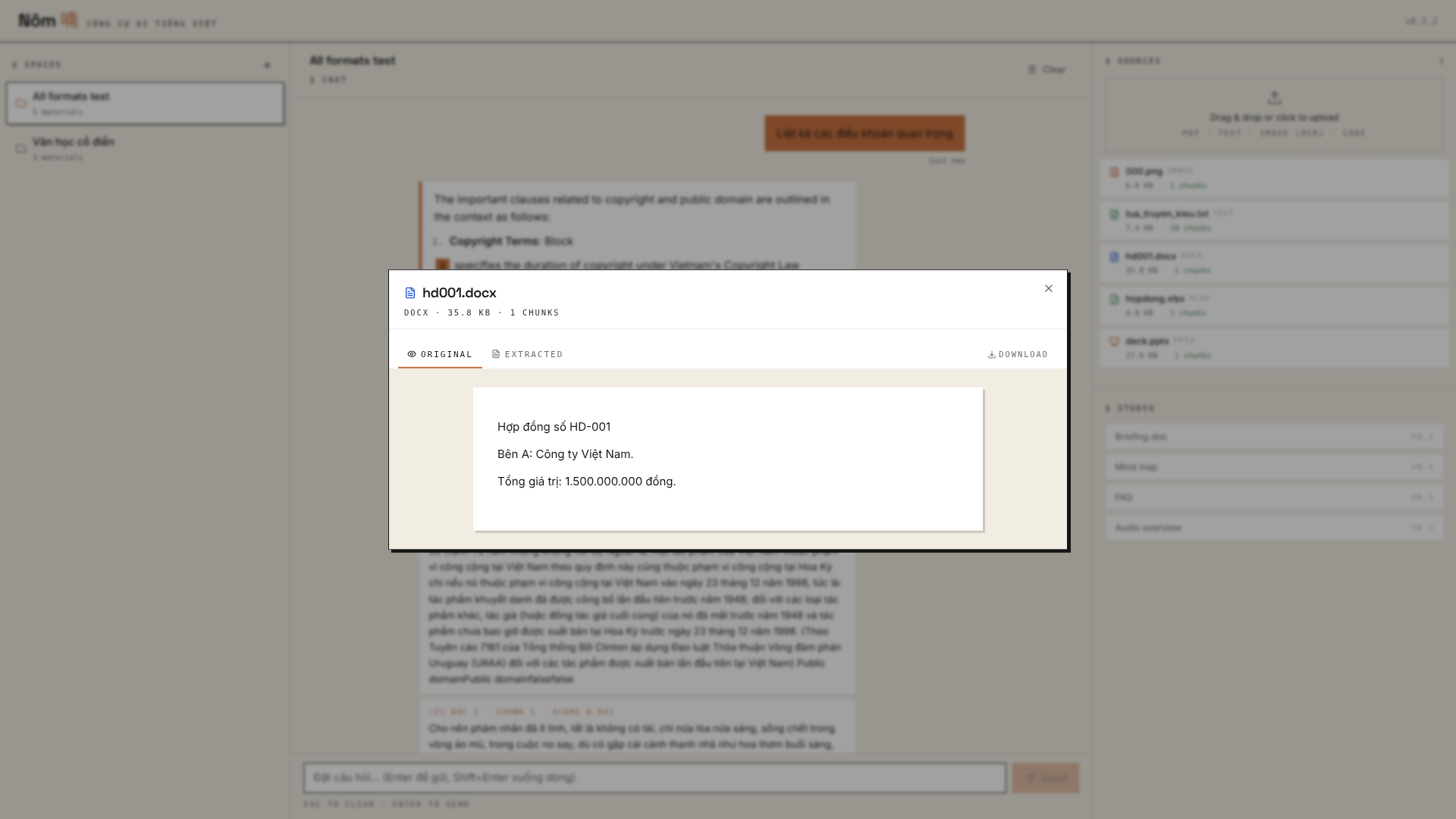
Browser viewers for every supported format
Click any material in the right panel — Original tab renders the file natively, Extracted tab shows what the chunker + embedder saw. PDFs / images use the browser's native viewer; Office formats render as structured HTML so the browser can show them without LibreOffice.
| DOCX → editorial paragraphs | PPTX → 16:10 slide cards | XLSX → HTML tables with sheet picker |
|---|---|---|
 |
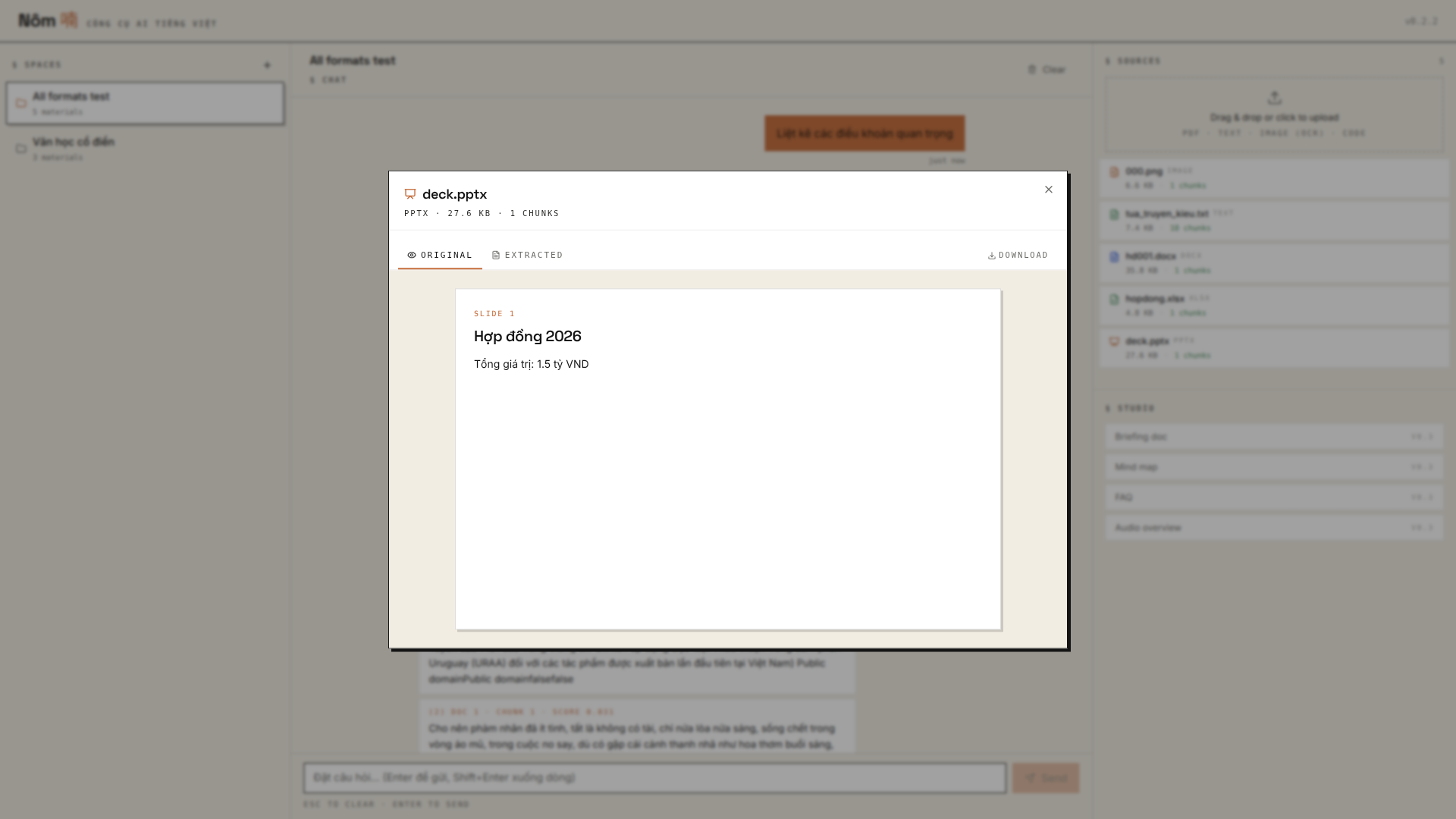 |
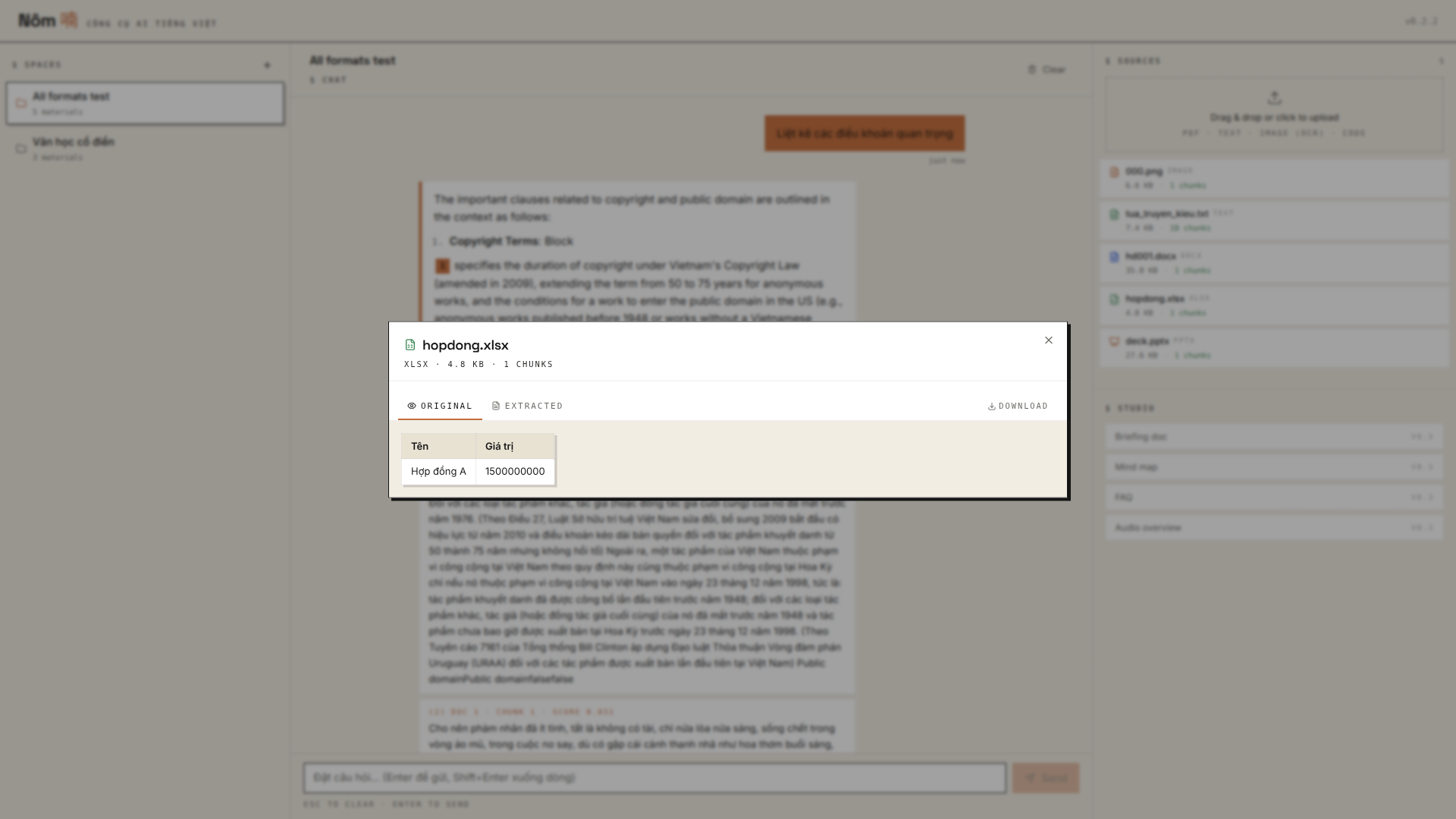 |
Library use (no web app)
from nom.rag import RAG
from nom.llm import Ollama
rag = RAG.from_documents(
["contract.pdf", "letter.docx", "Hợp đồng số HD-001..."],
llm=Ollama(model="qwen3:8b"),
)
answer = rag.ask("Có bao nhiêu hợp đồng có phạt vi phạm?")
print(answer.text) # the LLM's response
print(answer.citations) # [(doc_idx, chunk_idx, score, text), ...]
Document extraction without RAG:
from nom.doc import extract
from nom.llm import Ollama
result = extract(
"hop_dong.pdf",
schema={"so_hop_dong": str, "ngay_ky": "date", "tong_gia_tri": "amount_vnd"},
llm=Ollama(model="qwen3:8b"),
)
Text utilities without the rest:
from nom.text import normalize, fix_diacritics, word_tokenize
clean = normalize("Hợp đồng số 02/HĐ/2025")
# Three diacritic backends — pick by your accuracy / dependency budget:
# (1) zero-dep rule path — 41 % word acc, < 1 ms
fixed_rule = fix_diacritics("Hop dong nay duoc lap")
# (2) public Apache T5 (recommended) — 97.81 % word acc, ~150 ms on GPU
# pip install "nom-vn[diacritic-hf]"
from nom.text.diacritic_models import HFDiacriticModel
fixed = fix_diacritics("Hop dong nay duoc lap", model=HFDiacriticModel())
# (3) pass any LLM adapter — 87-95 % depending on model
from nom.llm import Ollama
fixed_llm = fix_diacritics("Hop dong nay duoc lap", llm=Ollama("gemma3:4b"))
toks = word_tokenize("Thành phố Hồ Chí Minh") # ["Thành phố", "Hồ Chí Minh"]
Install
pip install nom-vn # text + chunking + retrieve + rag (no I/O deps)
pip install "nom-vn[doc]" # + PDF / Office / OCR parsers
pip install "nom-vn[embeddings]" # + sentence-transformers
pip install "nom-vn[llm]" # + httpx for Ollama / OpenAI-compat
pip install "nom-vn[chat]" # + FastAPI / uvicorn + everything above
pip install "nom-vn[all]" # the lot
OCR (image / scanned PDF) needs Tesseract installed system-wide:
# Debian/Ubuntu
sudo apt install tesseract-ocr tesseract-ocr-vie
# Conda
conda install -c conda-forge tesseract
# macOS
brew install tesseract tesseract-lang
nom serve auto-detects the Tesseract binary + finds vie.traineddata; if absent, image uploads index as zero chunks rather than failing.
Architecture in one line
7 layers (Primitives / Models / Retrieval / RAG / Storage / Application / Deployment), every meaningful boundary is a typing.Protocol. Local single-process today; the cloud path replaces three Protocol implementations and changes nothing in the application layer.
See docs/architecture.md for the full layered model, Protocol seam table, and scaling-path reference.
Models & datasets we publish
Apache-2.0-friendly artifacts on Hugging Face Hub (cite Viet-Anh Nguyen and Neural Research Lab per the repo's citation block):
- 🤗
nrl-ai/vn-diacritic-vit5-base— register-balanced ViT5 fine-tune for diacritic restoration - 🤗
nrl-ai/vn-diacritic-eval— 4-register diacritic evaluation grid (1,227 sentence pairs) - 🤗
nrl-ai/vn-diacritic-train— 500K Wikipedia + 150K NFC-fixed VN news training pairs
Full per-task detail: docs/tasks/diacritic-restoration.md.
Documentation
- docs/readme.md — docs index pointing at all per-task pages
- docs/tasks/ — one page per task (public landscape + our pipeline + trained models + datasets + results)
- docs/architecture.md — the 7-layer model, Protocol seams, scaling path, anti-architecture rules
- docs/pipeline.md — the document-extraction pipeline end-to-end with per-stage picks
- docs/benchmark.md — measured numbers per module (the receipts behind every "Recommended stack" row above)
- docs/recipes.md — task-oriented "I want X, do Y" cookbook with copy-paste code
- docs/release.md — how to cut a PyPI release (Trusted Publishing via GitHub Actions, no tokens)
- docs/training_plan_2026q2.md — when to fine-tune vs adopt off-the-shelf, per component, with cost estimates
- docs/sota_vn_2026q2.md — SOTA local LLM / embedding / OCR for Vietnamese (April 2026 snapshot, every claim cited)
- docs/oss_landscape_2026q2.md — OSS local-AI / RAG landscape: patterns to steal, traps to avoid
- benchmarks/ — reproducible measurement scripts (perf + retrieval + accuracy)
- CONTRIBUTING.md — dev setup, PR rules
- CHANGELOG.md — version history
License
Apache 2.0. Fine-tune, redistribute, commercialize freely. Please keep attribution.
Citation
@software{nom2026,
title = {Nôm: an open Python toolkit for Vietnamese AI applications},
author = {Nguyen, Viet-Anh and {Neural Research Lab}},
year = {2026},
url = {https://nrl.ai/nom},
note = {Apache 2.0}
}
Built by
Neural Research Lab — open-source AI tooling. Edge inference, private assistants, training, labeling.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nom_vn-0.2.37.tar.gz.
File metadata
- Download URL: nom_vn-0.2.37.tar.gz
- Upload date:
- Size: 6.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e150c2f562e65ca6b7fde9d262882b8fe7d7bef99caa17281b8fbdf03f6bc390
|
|
| MD5 |
bb85f9bc89f4bb102a172bcce4b7c30c
|
|
| BLAKE2b-256 |
d4ace64c1115c9c0a4c4d8c0dd501e78f257c34e03f3ed5d1d91e9a959416226
|
Provenance
The following attestation bundles were made for nom_vn-0.2.37.tar.gz:
Publisher:
publish.yml on nrl-ai/nom-vn
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
nom_vn-0.2.37.tar.gz -
Subject digest:
e150c2f562e65ca6b7fde9d262882b8fe7d7bef99caa17281b8fbdf03f6bc390 - Sigstore transparency entry: 1426233656
- Sigstore integration time:
-
Permalink:
nrl-ai/nom-vn@3a3799c3a0915666a5dff4ea0f1fb68ed3bd8a21 -
Branch / Tag:
refs/tags/v0.2.37 - Owner: https://github.com/nrl-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@3a3799c3a0915666a5dff4ea0f1fb68ed3bd8a21 -
Trigger Event:
push
-
Statement type:
File details
Details for the file nom_vn-0.2.37-py3-none-any.whl.
File metadata
- Download URL: nom_vn-0.2.37-py3-none-any.whl
- Upload date:
- Size: 294.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bffeefe4cdc91a414229e95ce0f73b65092e208c1a7e120791438e2560b8e20d
|
|
| MD5 |
0c1efb340ae4081bf454f72a79021d7b
|
|
| BLAKE2b-256 |
49d19f1cefefce5e274d5ad79ef61ac0e728b9b2b4b4466b9a727102dfd8d664
|
Provenance
The following attestation bundles were made for nom_vn-0.2.37-py3-none-any.whl:
Publisher:
publish.yml on nrl-ai/nom-vn
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
nom_vn-0.2.37-py3-none-any.whl -
Subject digest:
bffeefe4cdc91a414229e95ce0f73b65092e208c1a7e120791438e2560b8e20d - Sigstore transparency entry: 1426233782
- Sigstore integration time:
-
Permalink:
nrl-ai/nom-vn@3a3799c3a0915666a5dff4ea0f1fb68ed3bd8a21 -
Branch / Tag:
refs/tags/v0.2.37 - Owner: https://github.com/nrl-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@3a3799c3a0915666a5dff4ea0f1fb68ed3bd8a21 -
Trigger Event:
push
-
Statement type:







