Automating the process of Data Preprocessing for Data Science

Project description
Automate Data Preprocessing for Data Science Projects
Glide through the most repetitive part of Data Science, preprocessing the dataframes with prepdata. prepdata lets you train your Machine Learning models without worrying about the imperfections of the underlying dataset. Replace missing values, remove outliers, encode categorical variables, split the dataset and train your model automatically with the comprehensive functions of this library.
Visit the project GitHub
Sample Code
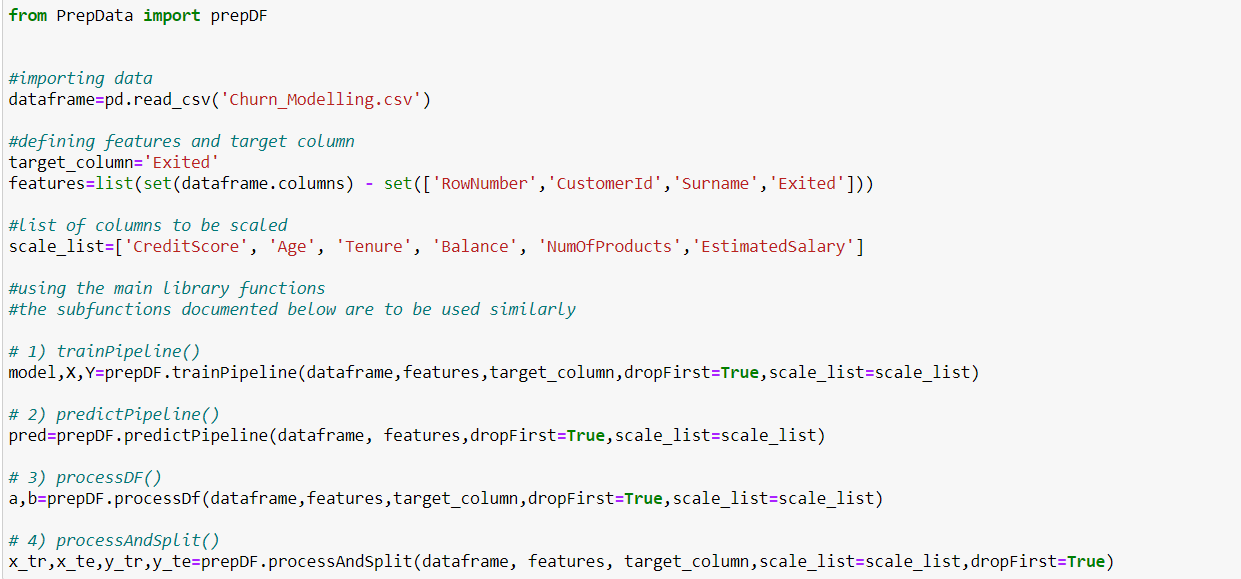
Documentation
The library works on Pandas dataframes. All the available functions have been documented below.
Main Functions:
1) trainPipeline() - Main function to run the complete data preprocessing and model training pipeline. Automatically replace missing values, encode categorical features, remove outliers, scale values, split the dataset and train the model.
``` def trainPipeline(dataframe,features,target,na_method='drop',ohe=True, dropFirst=False,rem_outliers=True,n_std=3,scale_vals=True, scale_list=None,scale_type='std',test_split=0.2,folds=5,model_name='model')
```
Arguments:
dataframe - the pandas dataframe to be used for processing (pandas.DataFrame)
features - list of columns in the dataframe to be used as features (list)
target - name of target column (string)
na_method- method used to deal with the missing values (string).
Possible values- 'drop' (default), 'mode' and 'mean'
ohe - Method used for converting categorical columns (Boolean)
Possible values- True for one hot encoding, False for label encoding
dropFirst - Method to determine whether dummy variable is to be discarded or not. Valid only if ohe=True (Boolean).
Possible values- True for dropping dummy variable, otherwise False
rem_outliers - whether outliers are to be removed (Boolean)
Possible values- True for removing outliers (Default), otherwise False
n_std- The number of standard deviations upto which the values are to be kept (int)
Default - 3
scale_vals - whether values are to be scaled or not (Boolean)
Possible values- True for scaling (Default), False for no scaling
scale_list- list of all columns to be scaled. Default: all columns (list).
scale_type- Method used for scaling (string)
Possible values- 'std' for standard scaling (default) and 'minmax' for min-max scaling
test_split - Ratio of test set to the the total data (float). Default: 0.2
folds - number of folds for k-fold cross validation (int). Default: 5
task_type - type of task to be carried out by the random forest model (string).
Possible values- 'c' for classification (default) and 'r' for regression
model_name - name of the model pkl file to be saved (string). Default: 'model'
Returns:
model - sklearn model (Random Forest) trained on the given dataset.
X - Preprocessed dataframe used to train model
y - target vector
2) predictPipeline() - Main function to run the complete prediction pipeline using the model trained with the trainPipeline() function. The trainPipeline() function must be executed before using the predictPipeline().
``` def predictPipeline(dataframe,features,na_method='drop',ohe=True, dropFirst=False,rem_outliers=True,n_std=3,scale_vals=True, scale_list=None,scale_type='std',model_name='model'):
```
Arguments for predictPipeline() must be identical to trainPipeline() to ensure that the processed dataframes are identical in both cases.
Arguments:
dataframe - the pandas dataframe to be used for predictions (pandas.DataFrame)
features - list of columns in the dataframe to be used as features (list)
model_name - name of the model saved in the trainPipeline() (string).
Remaining arguments are identical to trainPipeline().
Returns:
pred - array of predictions made using the given dataframe and model.
3) processDf() - Function to preprocess the dataframe. Similar to trainPipeline() except no model is trained and returned.
``` def processDf(dataframe,features,target,na_method='drop',ohe=True, dropFirst=False,rem_outliers=True,n_std=3,scale_vals=True, scale_list=None,scale_type='std')
```
Arguments:
Arguments are identical to trainPipeline().
Returns:
X - Preprocessed dataframe for model training
y - target vector
4) processAndSplit() - Function to preprocess the dataframe and split into train and test set. Similar to processDF() except the processed dataframe is split and returned.
``` def processAndSplit(dataframe,features,target,na_method='drop',ohe=True, dropFirst=False,rem_outliers=True,n_std=3,scale_vals=True, scale_list=None,scale_type='std',test_split=0.2):
```
Arguments:
Arguments are identical to trainPipeline().
Returns:
4 Dataframes -
X_train,X_test,y_train,y_test
5) prepText() - Main function to preprocess text data.
def prepText(df,col,na_method='drop',stopword=True,lemmatize=True,lem_method='l')
Arguments:
df - the pandas dataframe to be used (pandas.DataFrame)
col - column in the dataframe containing the text (string)
na_method- method used to deal with the missing values (string).
Possible values- 'drop' (default) or any string to replace the missing value
stopword- whether stopwords are to be removed or not (Boolean).
Possible values- True (default) for dropping stopwords else False
lemmatize- whether words are to be lemmatized/stemmed (Boolean).
Possible values- True (default), False
lm_method- method to be used for lemmatizing/stemming (string).
Possible values- 'l' for lemmatizing, 's' for stemming
Returns:
corpus - list containing the preprocessed text.
Sub-functions:
1) missingVals() - Remove or replace missing values from the dataset
def missingVals(df,na_method ='drop')
Arguments:
df- dataframe to be used (pandas.DataFrame).
na_method- method used to deal with the missing values (string).
Possible values- 'drop' (default), 'mode' and 'mean'
Returns:
Dataframe without missing values.
2) catEncoding() - Converting categorical columns to numerical, using label encoding or one-hot encoding.
def catEncoding(df,ohe=True,dropFirst=False)
Arguments:
df- dataframe to be used (pandas.DataFrame).
ohe- Method used for converting categorical columns (Boolean)
Possible values- True for one hot encoding, False for label encoding
dropFirst- Method to determine whether dummy variable is to be discarded or not. Valid only if ohe=True (Boolean).
Possible values- True for dropping dummy variable, otherwise False
Returns:
Dataframe with all numerical columns.
3) remOutliers() - Remove outliers from the dataset using number of standard deviations (z-score).
def remOutliers(df,n_std=3)
Arguments:
df- dataframe to be used (pandas.DataFrame).
n_std- The number of standard deviations upto which the values are to be kept (float).
Default - 3.0
Returns:
Dataframe without outliers.
4) scaleVals() - Scale the values present in the dataset
def scaleVals(df,scale_list=None,scale_type='std')
Arguments:
df- dataframe to be used (pandas.DataFrame).
scale_list- list of all columns to be scaled. Default: all columns (list).
scale_type- Method used for scaling (string)
Possible values- 'std' for standard scaling (default) and 'minmax' for min-max scaling
Returns:
Dataframe with scaled values.
5) testSplit() - Split the dataset into training and test set
def testSplit(X,y,test_split=0.2)
Arguments:
X- dataframe with all the features (pandas.DataFrame/ numpy.array).
y- target column (pandas.DataFrame/ numpy.array).
test_split- Ratio of test set to the the total data (float). Default: 0.2
Returns:
4 Dataframes -
X_train,X_test,y_train,y_test
6) splitAndTrain() - Split the dataset into train and test test, train a random forest model on the training set and save the model as a pickle file.
def splitAndTrain(X,y,test_split=0.2,folds=5,task_type='c',model_name='model')
Arguments:
X - dataframe with all the features (pandas.DataFrame/ numpy.array).
y - target column (pandas.DataFrame/ numpy.array).
scale_list - list of all columns to be scaled (list). Default: all columns.
test_split - Ratio of test set to the the total data (float). Default: 0.2
folds - number of folds for k-fold cross validation (int). Default: 5
task_type - type of task to be carried out by the random forest model (string).
Possible values- 'c' for classification (default) and 'r' for regression
model_name - name of the model pkl file to be saved (string). Default: 'model'
Returns:
score - accuracy of the model trained. Accuracy for classification and R2 score for regression.
model - sklearn model (Random Forest) trained by the function on the given dataset.
7) predScore() - Score the models predictions
def predScore(y_true,y_pred,task_type='c'):
Arguments:
y_true- Vector of actual labels from the test set (numpy.array)
y_pred- Vector of predictions made by the model (numpy.array).
task_type - type of task that was carried out (string).
Possible values- 'c' for classification (default) and 'r' for regression
Prints:
Prints the accuracy value for classification and MSE score for regression.
Copyright (c) 2021 Karan-Malik
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file PrepData-0.1.12.tar.gz.
File metadata
- Download URL: PrepData-0.1.12.tar.gz
- Upload date:
- Size: 7.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.6.1 requests/2.25.0 setuptools/52.0.0 requests-toolbelt/0.9.1 tqdm/4.54.0 CPython/3.7.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
245a63a1b0b91a6e09c5a238c570170018b373f3a228af690fab9118b9291ed1
|
|
| MD5 |
eafa42edcb09eddf00c9686b245f8afc
|
|
| BLAKE2b-256 |
3c92f1470cd9340ce45ce295b57628feb13c3bc8a23380b50d2a59330fbeedfd
|
File details
Details for the file PrepData-0.1.12-py3-none-any.whl.
File metadata
- Download URL: PrepData-0.1.12-py3-none-any.whl
- Upload date:
- Size: 8.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.6.1 requests/2.25.0 setuptools/52.0.0 requests-toolbelt/0.9.1 tqdm/4.54.0 CPython/3.7.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
834f190708554ef6fe3630aa8860d80d69df4bd0826a0b2923178a65e3efb845
|
|
| MD5 |
e71ae5df301732c638c48c99088a0666
|
|
| BLAKE2b-256 |
03a409d2a83e337e185fbf7d5cd8a643e4c9517dbc6a2d1deebf40485b9bc2cd
|







