Neural building blocks for speaker diarization

Project description
Using pyannote.audio open-source toolkit in production?
Make the most of it thanks to our consulting services.
pyannote.audio speaker diarization toolkit
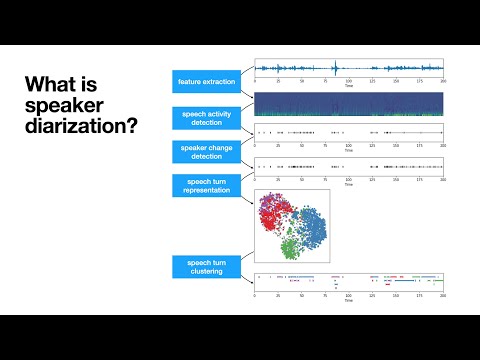
pyannote.audio is an open-source toolkit written in Python for speaker diarization. Based on PyTorch machine learning framework, it comes with state-of-the-art pretrained models and pipelines, that can be further finetuned to your own data for even better performance.
TL;DR
- Install
pyannote.audio3.0withpip install pyannote.audio - Accept
pyannote/segmentation-3.0user conditions - Accept
pyannote/speaker-diarization-3.0user conditions - Create access token at
hf.co/settings/tokens.
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.0",
use_auth_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE")
# send pipeline to GPU (when available)
import torch
pipeline.to(torch.device("cuda"))
# apply pretrained pipeline
diarization = pipeline("audio.wav")
# print the result
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")
# start=0.2s stop=1.5s speaker_0
# start=1.8s stop=3.9s speaker_1
# start=4.2s stop=5.7s speaker_0
# ...
Highlights
- :hugs: pretrained pipelines (and models) on :hugs: model hub
- :exploding_head: state-of-the-art performance (see Benchmark)
- :snake: Python-first API
- :zap: multi-GPU training with pytorch-lightning
Documentation
- Changelog
- Frequently asked questions
- Models
- Available tasks explained
- Applying a pretrained model
- Training, fine-tuning, and transfer learning
- Pipelines
- Available pipelines explained
- Applying a pretrained pipeline
- Adapting a pretrained pipeline to your own data
- Training a pipeline
- Contributing
- Adding a new model
- Adding a new task
- Adding a new pipeline
- Sharing pretrained models and pipelines
- Blog
- Videos
- Introduction to speaker diarization / JSALT 2023 summer school / 90 min
- Speaker segmentation model / Interspeech 2021 / 3 min
- First releaase of pyannote.audio / ICASSP 2020 / 8 min
Benchmark
Out of the box, pyannote.audio speaker diarization pipeline v3.0 is expected to be much better (and faster) than v2.x.
Those numbers are diarization error rates (in %):
| Dataset \ Version | v1.1 | v2.0 | v2.1 | v3.0 | Premium |
|---|---|---|---|---|---|
| AISHELL-4 | - | 14.6 | 14.1 | 12.3 | 12.3 |
| AliMeeting (channel 1) | - | - | 27.4 | 24.3 | 19.4 |
| AMI (IHM) | 29.7 | 18.2 | 18.9 | 19.0 | 16.7 |
| AMI (SDM) | - | 29.0 | 27.1 | 22.2 | 20.1 |
| AVA-AVD | - | - | - | 49.1 | 42.7 |
| DIHARD 3 (full) | 29.2 | 21.0 | 26.9 | 21.7 | 17.0 |
| MSDWild | - | - | - | 24.6 | 20.4 |
| REPERE (phase2) | - | 12.6 | 8.2 | 7.8 | 7.8 |
| VoxConverse (v0.3) | 21.5 | 12.6 | 11.2 | 11.3 | 9.5 |
Citations
If you use pyannote.audio please use the following citations:
@inproceedings{Plaquet23,
author={Alexis Plaquet and Hervé Bredin},
title={{Powerset multi-class cross entropy loss for neural speaker diarization}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
}
@inproceedings{Bredin23,
author={Hervé Bredin},
title={{pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
}
Development
The commands below will setup pre-commit hooks and packages needed for developing the pyannote.audio library.
pip install -e .[dev,testing]
pre-commit install
Test
pytest
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyannote.audio-3.0.0.tar.gz.
File metadata
- Download URL: pyannote.audio-3.0.0.tar.gz
- Upload date:
- Size: 15.6 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fc50ac5f357789f4817175aed0b136264fe2b1791182e3737dba1f2825eb4f8c
|
|
| MD5 |
60d17b14383074898a3e4a786fdf1dc6
|
|
| BLAKE2b-256 |
813a06a92d2d180a153cd50db5366c99ed28f28895e71ef91a16280812569ab0
|
File details
Details for the file pyannote.audio-3.0.0-py2.py3-none-any.whl.
File metadata
- Download URL: pyannote.audio-3.0.0-py2.py3-none-any.whl
- Upload date:
- Size: 200.1 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d70559dda211d90c20a93ed524de92770dc8ef959d7479cad964833b0ec76232
|
|
| MD5 |
703816df5970eca0c71da60f265062fe
|
|
| BLAKE2b-256 |
b08e2b74f4fdfc0666f0e3acbe526c5ab0323b098f6edbbebcc9fb21bf806c60
|







