Quantitative Summarization – Key Point Analysis

Project description
🏅Quantitative Summarization – Key Point Analysis🏅






Keypoint Analysis
This library is based on the Transformers library by HuggingFace. Keypoint Analysis quickly embeds the statements with the provided supported topic and the stances toward that topic. It is a part of our approach in the Quantitative Summarization – Key Point Analysis shared task by IBM. We use the ArgKP dataset (Bar-Haim et al., ACL-2020), which contains ~24K argument/key-point pairs, for 28 controversial topics in our training and evaluation.
What's New
July 1, 2021
- First release of qs-kpa python package
July 4, 2021
- Our method achieved the 4th position in track I of the shared task [paper]
Installation
Install with pip (stable version)
pip install qs-kpa
Install from sources (latest version)
git clone https://github.com/VietHoang1512/KPA
pip install -e .
Quick example
Currently, a pretrained KPA encoder with RoBERTa backbone is available, which can be automatically downloaded from Google Drive when initializing the KeyPointAnalysis instance. We used the 4 last hidden state representations of the [CLS] token as the whole sentence embedding and trained it with TupletMarginLoss and IntraPairVarianceLoss on the ArgKP dataset. For the code, see main.py.
# Import needed libraries
from qs_kpa import KeyPointAnalysis
# Create a KeyPointAnalysis model
# Set from_pretrained=True in order to download the pretrained model
encoder = KeyPointAnalysis(from_pretrained=True)
# Model configuration
print(encoder)
# Preparing data (a tuple of (topic, statement, stance) or a list of tuples)
inputs = [
(
"Assisted suicide should be a criminal offence",
"a cure or treatment may be discovered shortly after having ended someone's life unnecessarily.",
1,
),
(
"Assisted suicide should be a criminal offence",
"Assisted suicide should not be allowed because many times people can still get better",
1,
),
("Assisted suicide should be a criminal offence", "Assisted suicide is akin to killing someone", 1),
]
# Go and embedd everything
output = encoder.encode(inputs, convert_to_numpy=True)
In a comparison with the baseline model-which directly uses sentence embedding from RoBERTa model, in a subset of ArgKP dataset (for avoiding target leakage), our model strongly outperforms and exhibits rich representation learning capacity. Evaluation metrics (relaxed and strict mean Average Precision) are retained from the KPA_2021_shared_task.
Model using roBERTa directly: mAP strict = 0.4633403767342183 ; mAP relaxed = 0.5991767005443296
Our pretrained model: mAP strict = 0.9170783671441644 ; mAP relaxed = 0.9722347939653511
Detailed training
Given a pair of key point and argument (along with their supported topic & stance) and the matching score. Similar pairs with label 1 are pulled together, or pushed away otherwise.
Model
| Model | BERT/ConvBERT | BORT | LUKE | DistilBERT | ALBERT | XLNet | RoBERTa | ELECTRA | BART | MPNet |
|---|---|---|---|---|---|---|---|---|---|---|
| Siamese Baseline | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Siamese Question Answering-like | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Custom loss Baseline | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
Loss
- Constrastive
- Online Constrastive
- Triplet
- Online Triplet (Hard negative/positive mining)
Distance
- Euclidean
- Cosine
- Manhattan
Utils
- K-folds
- Full-flow
Pseudo-label
Group the arguments by their key point and consider the order of that key point within the topic as their labels (see pseudo_label). We can now utilize available Pytorch metrics learning distance, losses, miners or reducers from this great open-source in the main training workflow. For training, we use a key point and some of its positive/negative arguments as a batch. The goal is to minimize the distance between the keypoint and positive arguments as well as the arguments themselves. This is also our best approach (single-model) so far.
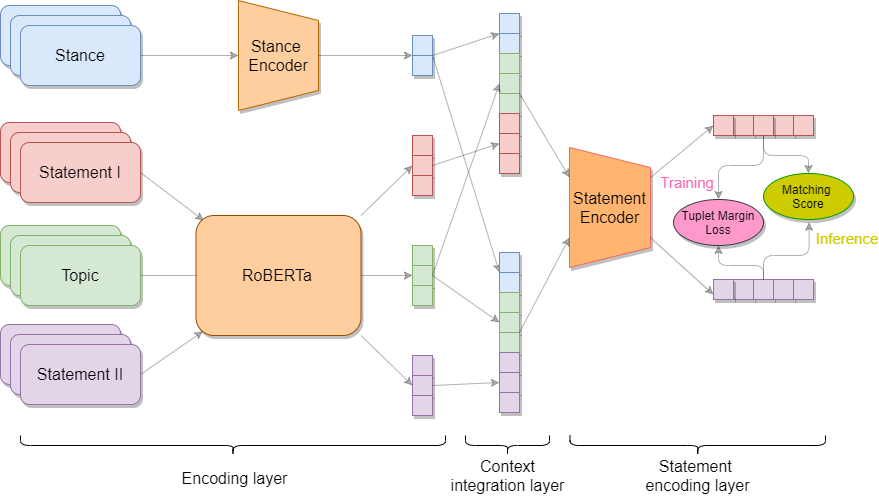
Training example
An example script for training RoBERTa on the ArgKP dataset. It runs in about 15 minutes each fold on a single Google Colab Tesla P100.
OUTPUT_DIR=outputs/pseudo_label/roberta-base/
echo "OUTPUT DIRECTORY $OUTPUT_DIR"
mkdir -p $OUTPUT_DIR
cp qs_kpa/pseudo_label/models.py $OUTPUT_DIR
for fold_id in 1 2 3 4 5 6 7
do
echo "TRAINING ON FOLD $fold_id"
python scripts/main.py \
--experiment "pseudolabel" \
--output_dir "$OUTPUT_DIR/fold_$fold_id" \
--model_name_or_path roberta-base \
--tokenizer roberta-base \
--distance "cosine" \
--directory "kpm_k_folds/fold_$fold_id" \
--test_directory "kpm_k_folds/test/" \
--logging_dir "$OUTPUT_DIR/fold_$fold_id" \
--logging_steps 20 \
--max_pos 30 \
--max_neg 90\
--max_unknown 15 \
--overwrite_output_dir \
--num_train_epochs 5 \
--early_stop 10 \
--train_batch_size 1 \
--val_batch_size 128 \
--do_train \
--evaluate_during_training \
--warmup_steps 0 \
--gradient_accumulation_steps 1 \
--learning_rate 0.00003 \
--margin 0.3 \
--drop_rate 0.2 \
--n_hiddens 4 \
--max_len 30 \
--statement_max_len 50 \
--stance_dim 32 \
--text_dim 256 \
--num_workers 4 \
--seed 0
done
Training with the previously defined hyper-parameters yields above mentioned mAP score. Other approaches could be found in bin.
Contributors
- Phan Viet Hoang
- Nguyen Duc Long
BibTeX
@misc{hoang2021qskpa,
author = {Phan, V.H. & Nguyen, D.L.},
title = {Keypoint Analysis},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/VietHoang1512/KPA}}
}
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.







