Automatizar labores presentes en el día a día de los Data Scientists.

Project description
Quickdata Librery
Optimiza tu tiempo como Data Scientist
Por Diego Alejandro Ramírez Araujo - Github
Librería que te permitirá automatizar y simplificar tus labores cotidianas como científico/analista de datos.
Actualmente, su función principal se enfoca en optimizar el análisis univariado de variables categóricas/cualitativas, mediante la visualización automatizada de manera ponderada y sin ponderar de la variable en cuestión.
Para utilizarlo simplemente necesitas incluir como primer argumento el data frame y como segundo argumento una lista con la/las variables a graficar (los argumentos de personalización son opcionales). La función devolverá una gráfica sin ponderar y ponderada por cada variable.
📝 Note: Actualmente se están desarrollando otras funciones de automatización de gráficos combinados y detección/tratamiento/manejo de outliers.

Prerequisitos 🎬
Funcionalidades del proyecto 🛠️
pip install Quickdata
from Quickdata import complot
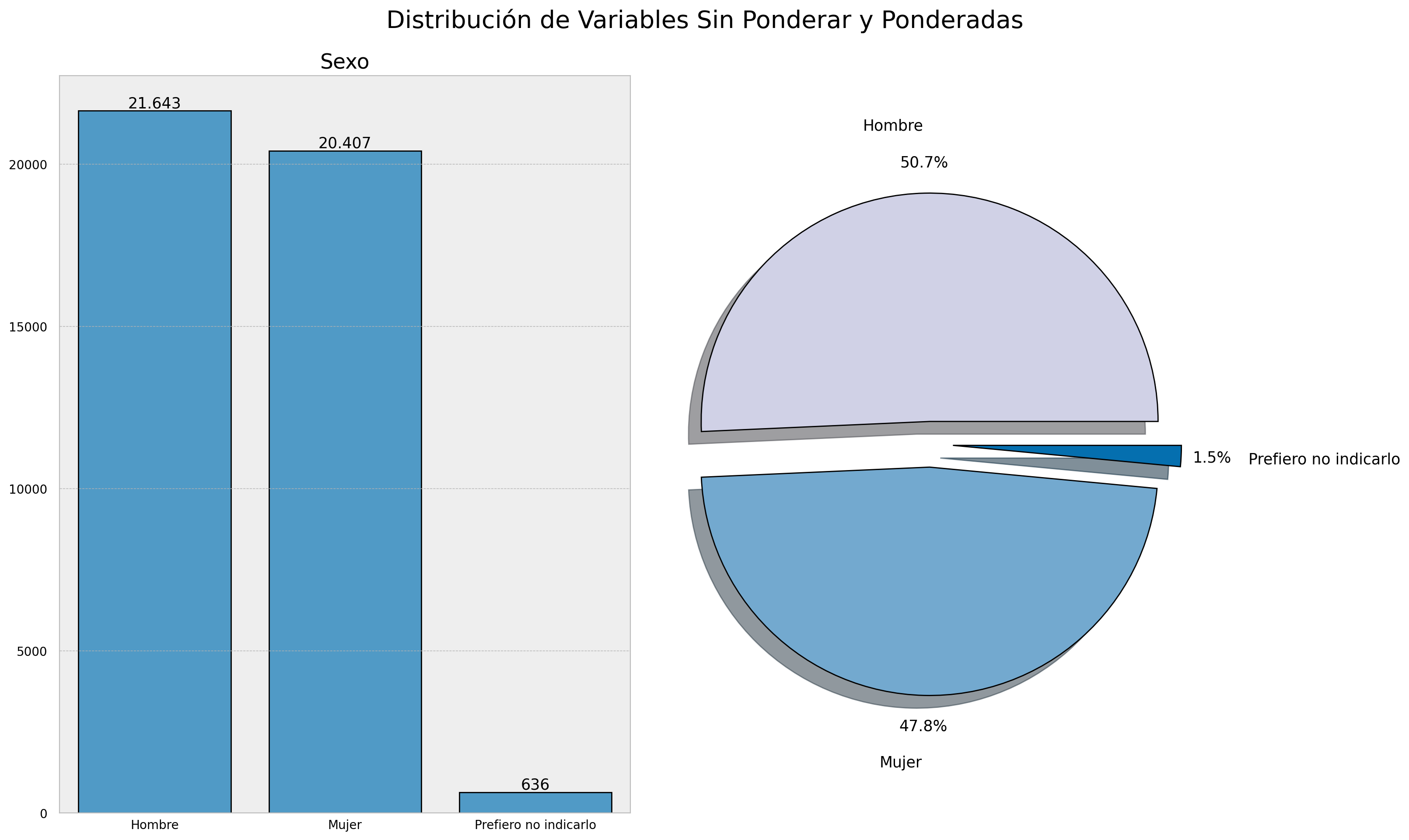
Funcionalidad simple: Obtener a través de menos de una línea de código una gráfica sin poderar y ponderada de una variable de tu DataFrame (configuración de axes, figure, títulos, labels y efectos visuales automatizados).
complot(example,["sexo"])
Funcionalidad avanzada: Introduce múltiple variables de tu DataFrame dentro de la función. Cada variable obtendrá dos gráficos (sin ponderar y ponderado). La función múltiple ordena de manera individual cada variable en el eje x o en y (para múltiples categorías se recomienda utilizar el eje y), agrupa de forma predeterminada las categorías con poca frecuencia para introcucirlas en el gráfico de pie como una sola (mejor visualización) y ordena de forma automática cada variable dependiendo de el tipo de su tipo de dato correspondiete: nominales (ordenados de mayor a menor según la frecuencia) y ordinales (ordinados de menor a mayor según la etiqueta).
complot(ejemplo,['Rango de edad', 'Familiares vinculados', 'Motivo de estancia'],
chart_type="donut", count_labels=False)
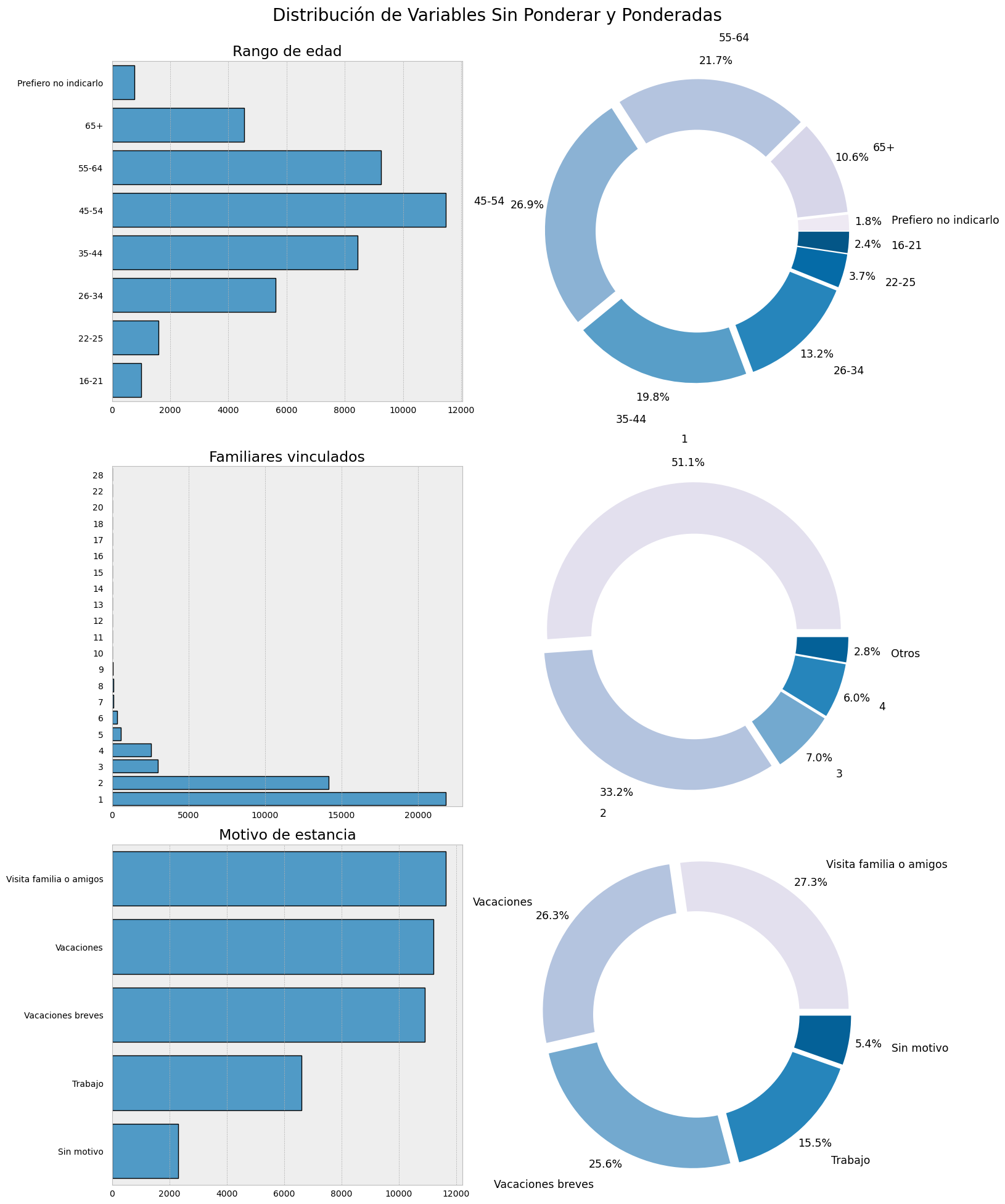
📝 Note:
1. El orden de los datos en el gráfico no ponderado varia dependiendo del tipo de categoría.
2. El gráfico ponderado de "Familiares vinculados" se encuentra agrupado por default.
Otras funcionalidades: Exportar, guardar y personalizar la configuración interna de los gráficos (paleta de colores, tamaño de figuras, establecer o no segmentación automática, limite de variables a introducir en el eje x, entre otros).
complot(ejemplo,['Rango de edad', 'Familiares vinculados', 'Motivo de estancia'],
chart_type="donut", count_labels=False, count_x_limit=5, palette="inferno",
figsize=(15,15), save=True)
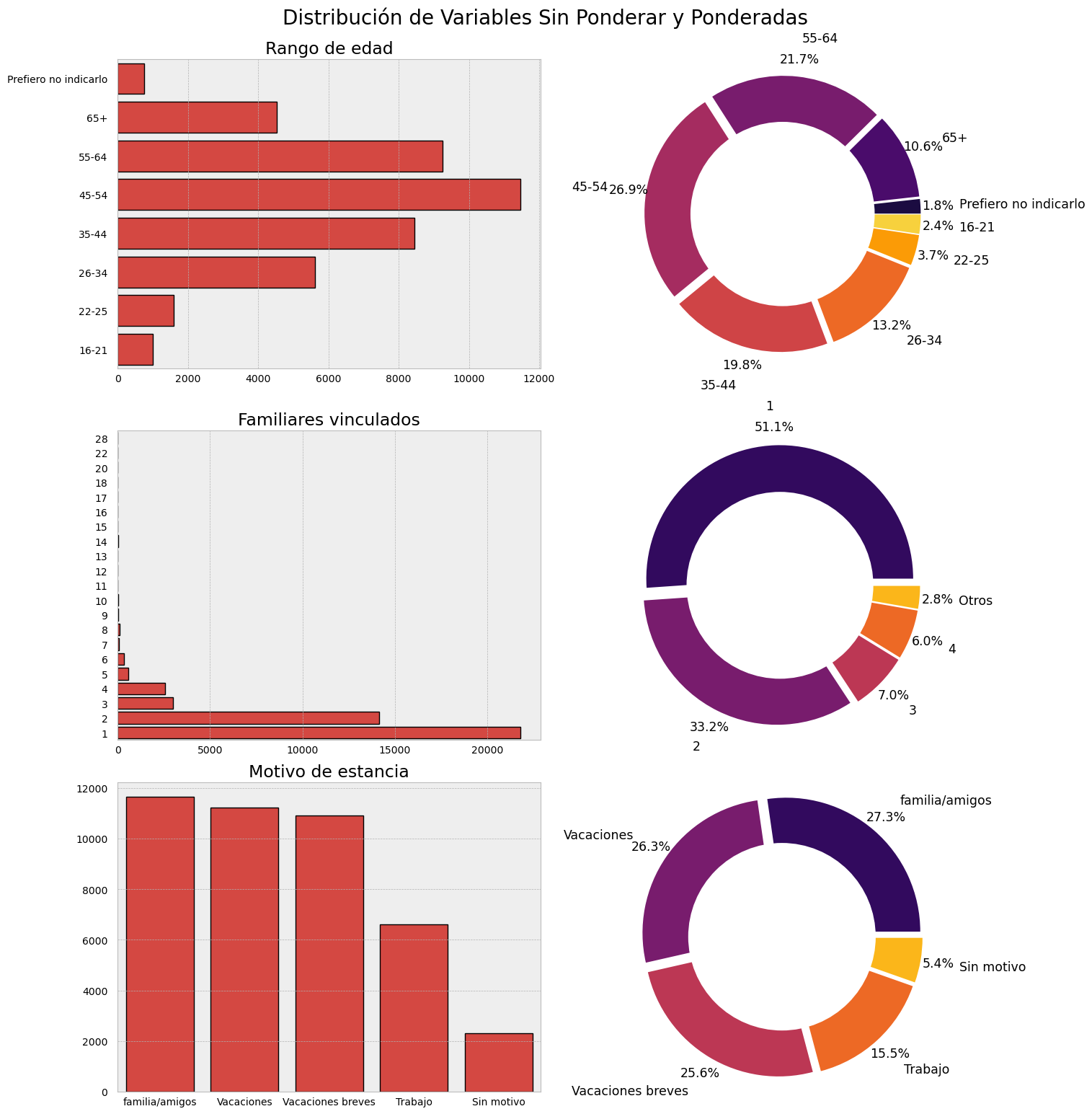
📝 Note: Entre las nuevas funcionalidades que se están desarrollando, se incluye en una de ellas otorgar libertar absoluta al usuario para configurar cada gráfico de manera individual bajo los mismos atributos que se emplearían en las librerías principales (seaborn y matplotlib).
Parámetros ❔
data: pd.DataFrame
Dataset a graficar.
var: list
Lista con una o múltiples variables a graficar.
figsize: tuple (optional)
Ancho y alto de la figura en la cual se graficará.
Palette: palette name or list (optional)
Colores a utilizar en los gráficos.
Chart_type: 'donut' o 'pie' (optional)
Tipo de gráfico ponderado.
Segmentation: Bool (optional)
Agrupación de categorías con poca representación en las variables al momento de crear el pie/donut chart.
Segmentation_minimum: float (optional)
En caso de incluir segmentación, ponderación mínima por categoría antes de ser segmentada.
count_labels: Bool (optional)
Activa o desactiva las etiquetas de datos del gráfico sin ponderar.
count_x_limit: int (optional)
Número de variables máximas permitidas en el eje x del gráfico no ponderado (en caso de superarse se graficará en el eje y).
save: Bool (optional)
Guarda automáticamente en formato .png los gráficos creados.
Autor 👽

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file Quickdata-1.0.2.tar.gz.
File metadata
- Download URL: Quickdata-1.0.2.tar.gz
- Upload date:
- Size: 7.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9a0708ec3e048fb96ae654ad0379788782ce5458d0621ecef4c8910f2ef8d02
|
|
| MD5 |
46f689533e124e4269d8890bc8318d01
|
|
| BLAKE2b-256 |
b6c5381b887d70355fc22d94fb640c92366cf6f7e607fcc9398400a14161704b
|
File details
Details for the file Quickdata-1.0.2-py3-none-any.whl.
File metadata
- Download URL: Quickdata-1.0.2-py3-none-any.whl
- Upload date:
- Size: 8.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
747035b9c115e43daef94a0d9550dd6a6e3493266f5d79c6bcd68ec35534cc8e
|
|
| MD5 |
6c84c3311ddb083066f4016e6ac9b64f
|
|
| BLAKE2b-256 |
aa5effa1b79d9873ec59bbe9bb75071d78bf11e438aacc42bf8426c7069866ae
|







