SeededPF is a seed guided topic model based on Poisson factorization.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
SeededPF



What is seededPF
seededPF is an easy to use implementation of the Seeded Poisson Factorization (SPF) topic model, introduced in this research paper. SPF provides a guided topic modeling approach that allows users to pre-specify topics of interest by providing sets of seed words. Built on Poisson factorization, it leverages variational inference techniques for efficient and scalable estimation.
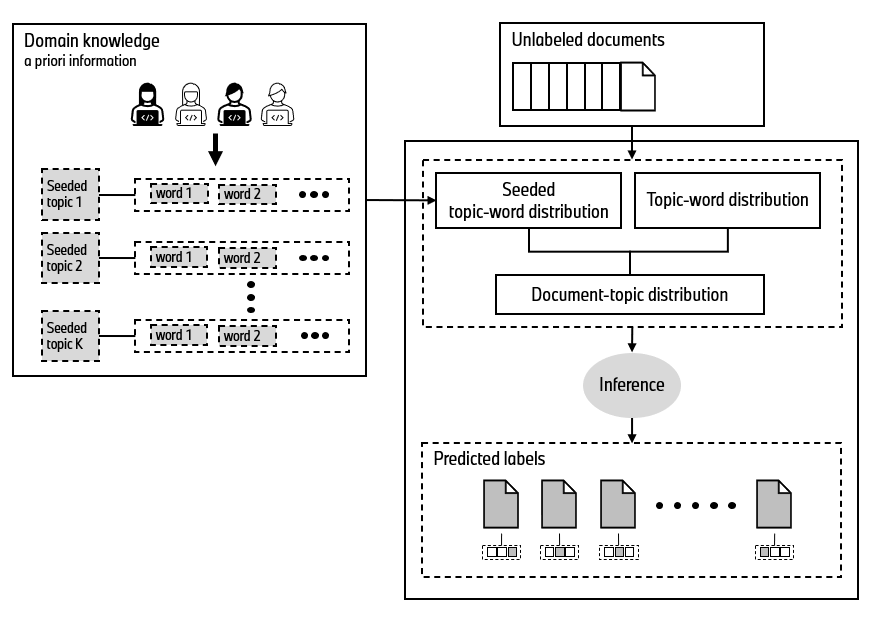
Traditional unsupervised topic models (like LDA) often struggle to align with predefined conceptual domains and typically require significant post-processing efforts, such as topic merging or manual labeling, to ensure topic coherence. seededPF overcomes this limitation by enabling the pre-specification of topics, which leads to improved topic interpretability and reduces the need for manual post-processing. Additionally, it supports the estimation of unsupervised topics when no seed words are provided.
Consider using seededPF if:
- You need to fit a topic model with a specific topic schema.
- You wish to estimate a topic model that is partially or fully unsupervised (i.e., providing no seed words means fitting a standard Poisson factorization topic model without predefined topics).
- You require a fast and scalable topic modeling solution.
seededPF offers a high-performance, scalable interface for guided topic modeling, providing a reliable alternative to keyATM and SeededLDA, while minimizing the need for manual intervention and enhancing topic interpretability.
Installation
seededPF works with Python 3.10 or Python 3.11. The main dependencies are Tensorflow 2.18 and tensorflow_probability 0.25.
Please be sure to adjust the dependencies if you are able to accelerate GPU support.
Via pip
The easiest way to install seededPF is via pip.
pip install seededpf
From source
One can also install the package from GitHub. Configure a virtual environment using Pyhton 3.10 or Python 3.11. Inside the virtual environment, use pip to install the required packages:
(venv)$ pip install -r requirements.txt
Training the Seeded Poisson Factorization model
seededPF is an easy to use library for topic modeling. We quickly walk through the most essential steps below:
- Imports and data preparation
- Initialization
- Reading documents
- Training the model
- Post-hoc analysis
The following minimal example is available on GitHub.
Step 1: Imports and data preparation
Once installed, one can import the SPF class of the seededPF library and is ready to go. There are only 2 things required to fit the SPF topic model:
- Text documents
- A seed word (i.e., keyword) dictionary for each topic to be estimated.
# Imports
from seededpf import SPF
from sklearn.feature_extraction.text import CountVectorizer
# Example documents - customer reviews about either smartphones or computers
documents = [
"My smartphone's battery life is fantastic, lasts all day!",
"The camera on my phone is incredible, takes crystal-clear photos.",
"Love the smooth performance, but it overheats with heavy apps.",
"This phone charges super fast, very convenient.",
"Upgraded my PC and it boots in seconds!",
"Great for gaming, but gets hot after long sessions.",
"My computer sometimes freezes, but a restart fixes it.",
"Best laptop I’ve owned, powerful and reliable!"
]
# Define topic-specific seed words
smartphone = {"smartphone", "iphone", "phone", "touch", "app"}
pc = {"laptop", "keyboard", "desktop", "pc"}
keywords = {"smartphone": smartphone, "pc": pc}
Step 2: Initialization
Now that we have both the documents and the pre-specification of topics to be estimated, we can initialize the SPF topic model.
spf = SPF(keywords = keywords, residual_topics = 0) # Fits 2 seeded topics and 0 unsupervised topics
Step 3: Reading documents
We tokenize the documents and create all data required for model training automatically.
spf.read_docs(documents,
count_vectorizer=CountVectorizer(stop_words="english", min_df = 0),
batch_size = 1024)
Step 4: Training the model
For model training, we have to set the learning rate and the number of epochs.
spf.model_train(lr = 0.1, epochs = 150)
Step 5: Analysis of the results
There are different methods available to analyze the topic model results. We refer to the minimal example or advanced example where we show post-hoc analysis methods.
The seededPF package offers several methods, including:
SPF.plot_model_loss(): Checks convergence of the negative ELBO.SPF.return_topics(): Returns a tuple (categories, E_theta), with categories being the most probable topic for each document and E_theta being the approximate posterior mean estimates per document and topic.SPF.calculate_topic_word_distributions(): Returns a pandas dataframe containing the approximate topic-term mean intensities.SPF.print_topics(): Returns a dictionary with the highest intensity words per topic.SPF.plot_seeded_topic_distribution(): Plots the variational topic word distribution of all seed words belonging to the topic parameter.SPF.plot_word_distribution(): Shows the fitted variational distribution of q(\Tilde{\beta}){topic,word} and q(\beta^*)_{topic,word}.
Contribution
If you encounter any bugs or would like to suggest new features for the library, please feel free to contact us or create an issue.
Citing
When citing seededPF, please use this BibTeX entry:
@article{PROSTMAIER2025114116,
title = {Seeded Poisson Factorization: leveraging domain knowledge to fit topic models},
journal = {Knowledge-Based Systems},
volume = {327},
pages = {114116},
year = {2025},
issn = {0950-7051},
doi = {https://doi.org/10.1016/j.knosys.2025.114116},
url = {https://www.sciencedirect.com/science/article/pii/S095070512501161X},
author = {Bernd Prostmaier and Jan Vávra and Bettina Grün and Paul Hofmarcher},
keywords = {Poisson factorization, Topic model, Variational inference, Customer feedback},
abstract = {Topic models are widely used for discovering latent thematic structures in large text corpora, yet traditional unsupervised methods often struggle to align with pre-defined conceptual domains. This paper introduces seeded Poisson factorization (SPF), a novel approach that extends the Poisson factorization (PF) framework by incorporating domain knowledge through seed words. SPF enables a structured topic discovery by modifying the prior distribution of topic-specific term intensities, assigning higher initial rates to pre-defined seed words. The model is estimated using variational inference with stochastic gradient optimization, ensuring scalability to large datasets. We present in detail the results of applying SPF to an Amazon customer feedback dataset, leveraging pre-defined product categories as guiding structures. SPF achieves superior performance compared to alternative guided probabilistic topic models in terms of computational efficiency and classification performance. Robustness checks highlight SPF’s ability to adaptively balance domain knowledge and data-driven topic discovery, even in case of imperfect seed word selection. Further applications of SPF to four additional benchmark datasets, where the corpus varies in size and the number of topics differs, demonstrate its general superior classification performance compared to the unseeded PF model.}
}
License
Code licensed under MIT.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file seededpf-0.1.1.tar.gz.
File metadata
- Download URL: seededpf-0.1.1.tar.gz
- Upload date:
- Size: 52.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2eedd7a08cfe1901937765e8593c2dca46fa94711a093035eef6a46ed9261f93
|
|
| MD5 |
7d6d9139706cdcce9ca2005af6fc338a
|
|
| BLAKE2b-256 |
4550b6d4153a1757c8abb88e21e38567398ebabcb7647949af01fd62de9eed4b
|
Provenance
The following attestation bundles were made for seededpf-0.1.1.tar.gz:
Publisher:
release.yaml on BPro2410/Seeded-Poisson-Factorization
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
seededpf-0.1.1.tar.gz -
Subject digest:
2eedd7a08cfe1901937765e8593c2dca46fa94711a093035eef6a46ed9261f93 - Sigstore transparency entry: 349397800
- Sigstore integration time:
-
Permalink:
BPro2410/Seeded-Poisson-Factorization@f33bb5e9ecee885f2d90785565e44fbdc23ebdd4 -
Branch / Tag:
refs/tags/0.1.1 - Owner: https://github.com/BPro2410
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yaml@f33bb5e9ecee885f2d90785565e44fbdc23ebdd4 -
Trigger Event:
push
-
Statement type:
File details
Details for the file seededpf-0.1.1-py3-none-any.whl.
File metadata
- Download URL: seededpf-0.1.1-py3-none-any.whl
- Upload date:
- Size: 48.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f69d9828ad016e119f3674d3100e703e21054a8435f224559cc0578c270f829c
|
|
| MD5 |
9f3b4bbecd2b99853480b7b27b5a9d96
|
|
| BLAKE2b-256 |
42d53affd9e521732bc016afd573b03b02e3403e2553f965f12f9f45c1b45223
|
Provenance
The following attestation bundles were made for seededpf-0.1.1-py3-none-any.whl:
Publisher:
release.yaml on BPro2410/Seeded-Poisson-Factorization
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
seededpf-0.1.1-py3-none-any.whl -
Subject digest:
f69d9828ad016e119f3674d3100e703e21054a8435f224559cc0578c270f829c - Sigstore transparency entry: 349397811
- Sigstore integration time:
-
Permalink:
BPro2410/Seeded-Poisson-Factorization@f33bb5e9ecee885f2d90785565e44fbdc23ebdd4 -
Branch / Tag:
refs/tags/0.1.1 - Owner: https://github.com/BPro2410
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yaml@f33bb5e9ecee885f2d90785565e44fbdc23ebdd4 -
Trigger Event:
push
-
Statement type:







