Replaces and translates voices in youtube videos

Project description
TurnVoice
A command-line tool to transform voices in (YouTube) videos with additional translation capabilities. [^1]
https://github.com/KoljaB/TurnVoice/assets/7604638/e0d9071c-0670-44bd-a6d5-4800e9f6190c
Features
-
Voice Transformation
Turn voices with the free Coqui TTS at no operating costs (supports voice cloning, 58 voices included -
Voice Variety
Support for popular TTS engines like Elevenlabs, OpenAI TTS, or Azure for more voices. [^7] -
Translation
Translates videos at zero costs, for example from english to chinese. powered by free deep-translator -
Change Speaking Styles (AI powered)
Make every spoken sentence delivered in a custom speaking style for a unique flair using prompting. [^6] -
Full Rendering Control
Precise rendering control by customizing the sentence text, timings, and voice selection.💡 Tip: the Renderscript Editor makes this step easy
-
Local Video Processing
Process any local video files. -
Background Audio Preservation
Keeps the original background audio intact.
Discover more in the release notes.
Prerequisites
Minimum 8 GB VRAM Nvidia graphics card recommended, tested on Python 3.11.4 / Windows 10.
-
NVIDIA CUDA Toolkit 11.8 installed
To install NVIDIA CUDA Toolkit:
- Visit NVIDIA CUDA Toolkit Archive.
- Select operating system and version.
- Download and install the software.
-
NVIDIA cuDNN installed.
To install NVIDIA cuDNN:
- Visit NVIDIA cuDNN Archive.
- Download and install the software.
(tested with v8.7.0, should also work with newer versions)
-
Rubberband command-line utility installed [^2]
-
ffmpeg command-line utility installed [^3]
To install ffmpeg with a package manager:
-
On Ubuntu or Debian:
sudo apt update && sudo apt install ffmpeg
-
On Arch Linux:
sudo pacman -S ffmpeg
-
On MacOS using Homebrew (https://brew.sh/):
brew install ffmpeg
-
On Windows using Chocolatey (https://chocolatey.org/):
choco install ffmpeg
-
On Windows using Scoop (https://scoop.sh/):
scoop install ffmpeg
-
-
Huggingface conditions accepted for Speaker Diarization and Segmentation
-
Huggingface access token in env variable HF_ACCESS_TOKEN [^4]
[!TIP] Set your HF token with `setx HF_ACCESS_TOKEN "your_token_here"
Installation
pip install turnvoice
[!TIP] For faster rendering with GPU prepare your CUDA environment after installation:
For CUDA 11.8
pip install torch==2.1.2+cu118 torchaudio==2.1.2+cu118 --index-url https://download.pytorch.org/whl/cu118For CUDA 12.1
pip install torch==2.1.2+cu118 torchaudio==2.1.2+cu211 --index-url https://download.pytorch.org/whl/cu211
Usage
turnvoice [-i] <YouTube URL|ID|Local File> [-l] <Translation Language> -e <Engine(s)> -v <Voice(s)> -o <Output File>
Submit a string to the 'voice' parameter for each speaker voice you wish to use. If you specify engines, the voices will be assigned to these engines in the order they are listed. Should there be more voices than engines, the first engine will be used for the excess voices. In the absence of a specified engine, the Coqui engine will be used as the default. If no voices are defined, a default voice will be selected for each engine.
Example Command:
Arthur Morgan narrating a cooking tutorial:
turnvoice -i AmC9SmCBUj4 -v arthur.wav -o cooking_with_arthur.mp4
[!NOTE] Requires the cloning voice file (e.g., arthur.wav or .json) in the same directory (you find one in the tests directory).
Workflow
Preparation
Prepare a script with transcription, speaker diarization (and optionally translation or prompting) using:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c --prepare
Translation and prompts should be applied in this preparation step. Engines or voices come later in the render step.
Renderscript Editor
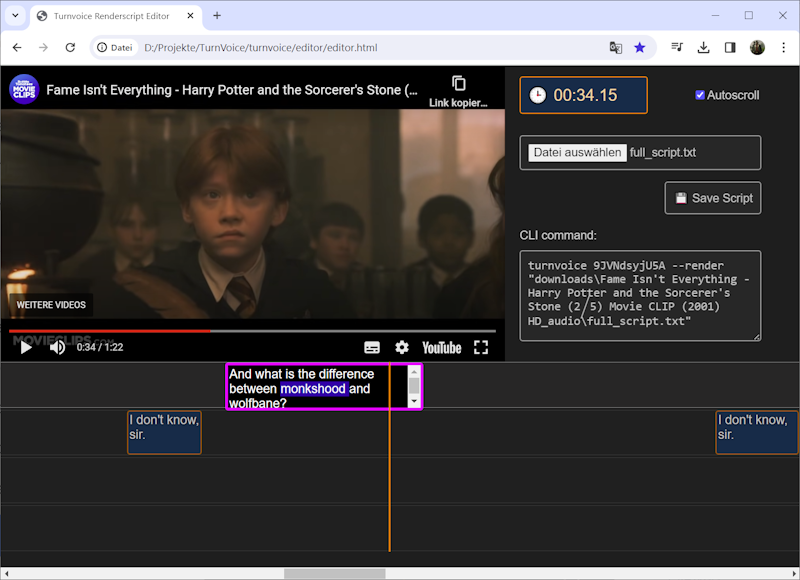
- Open script
Open the editor.html file. Click on the file open button and navigate to the folder you started turnvoice from. Open download folder. Open the folder with the name of the video. Open the file full_script.txt. - Edit
The Editor will visualize the transcript and speaker diarization results and start playing the original video now. While playing verify texts, starting times and speaker assignments and adjust them if the detection went wrong. - Save
Save the script. Remember the path to the file.
Rendering
Render the refined script to generate the final video using:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c --render <path_to_script>
Adjust the path in the displayed CLI command (the editor can't read that information out from the browser).
Assign engines and voices to each speaker track with the -e and -v commands.
Parameters
-i,--in: Input video. Accepts a YouTube video URL or ID, or a path to a local video file.-l,--language: Language for translation. Coqui synthesis supports: en, es, fr, de, it, pt, pl, tr, ru, nl, cs, ar, zh, ja, hu, ko. Omit to retain the original video language.-il,--input_language: Language code for transcription, set if automatic detection fails.-v,--voice: Voices for synthesis. Accepts multiple values to replace more than one speaker.-o,--output_video: Filename for the final output video (default: 'final_cut.mp4').-a,--analysis: Print transcription and speaker analysis without synthesizing or rendering the video.-from: Time to start processing the video from.-to: Time to stop processing the video at.-e,--engine: Engine(s) to synthesize with. Can be coqui, elevenlabs, azure, openai or system. Accepts multiple values, linked to the the submitted voices.-s,--speaker: Speaker number to be transformed.-snum,--num_speakers: Helps diarization. Specify the exact number of speakers in the video if you know it in advance.-smin,--min_speakers: Helps diarization. Specify the minimum number of speakers in the video if you know it in advance.-smax,--max_speakers: Helps diarization. Specify the maximum number of speakers in the video if you know it in advance.-dd,--download_directory: Directory for saving downloaded files (default: 'downloads').-sd,--synthesis_directory: Directory for saving synthesized audio files (default: 'synthesis').-ex,--extract: Enables extraction of audio from the video file. Otherwise downloads audio from the internet (default).-c,--clean_audio: Removes original audio from the final video, resulting in clean synthesis.-tf,--timefile: Define timestamp file(s) for processing (functions like multiple --from/--to commands).-p,--prompt: Define a prompt to apply a style change to sentences like "speaking style of captain jack sparrow" [^6]-prep,--prepare: Write full script with speaker analysis, sentence transformation and translation but doesn't perform synthesis or rendering. Can be continued.-r,--render: Takes a full script and only perform synthesis and rendering on it, but no speaker analysis, sentence transformation or translation.-faster,--use_faster: Usage of faster_whisper for transcription. If stable_whisper transcription throws OOM errors or delivers suboptimal results. (Optional)-model,--model: Transcription model to be used. Defaults to large-v2. Can be 'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1', 'large-v2', 'large-v3', or 'large'. (Optional)
-iand-lcan be used as both positional and optional arguments.
Translation
Translate a video into another language using the -l parameter.
For example, to translate into chinese you could use:
turnvoice https://www.youtube.com/watch?v=ZTH771HIhpg -l zh-CN -v daisy
Output Video
💡 Tip: In the tests folder you find a voice "chinese.json" trained on chinese phonemes.
Languages for Coqui Engine
| Shortcut | Language |
|---|---|
| ar | Arabic |
| cs | Czech |
| de | German |
| en | English |
| es | Spanish |
| fr | French |
| it | Italian |
| hu | Hungarian |
| ja | Japanese |
| ko | Korean |
| nl | Dutch |
| pl | Polish |
| pt | Portuguese |
| ru | Russian |
| tr | Turkish |
| zh-cn | Chinese |
Languages for other engines
Make sure to select voice a supporting the language in Azure and System Engine.| Shortcut | Language |
|---|---|
| af | Afrikaans |
| sq | Albanian |
| am | Amharic |
| ar | Arabic |
| hy | Armenian |
| as | Assamese |
| ay | Aymara |
| az | Azerbaijani |
| bm | Bambara |
| eu | Basque |
| be | Belarusian |
| bn | Bengali |
| bho | Bhojpuri |
| bs | Bosnian |
| bg | Bulgarian |
| ca | Catalan |
| ceb | Cebuano |
| ny | Chichewa |
| zh-CN | Chinese (Simplified) |
| zh-TW | Chinese (Traditional) |
| co | Corsican |
| hr | Croatian |
| cs | Czech |
| da | Danish |
| dv | Dhivehi |
| doi | Dogri |
| nl | Dutch |
| en | English |
| eo | Esperanto |
| et | Estonian |
| ee | Ewe |
| tl | Filipino |
| fi | Finnish |
| fr | French |
| fy | Frisian |
| gl | Galician |
| ka | Georgian |
| de | German |
| el | Greek |
| gn | Guarani |
| gu | Gujarati |
| ht | Haitian Creole |
| ha | Hausa |
| haw | Hawaiian |
| iw | Hebrew |
| hi | Hindi |
| hmn | Hmong |
| hu | Hungarian |
| is | Icelandic |
| ig | Igbo |
| ilo | Ilocano |
| id | Indonesian |
| ga | Irish |
| it | Italian |
| ja | Japanese |
| jw | Javanese |
| kn | Kannada |
| kk | Kazakh |
| km | Khmer |
| rw | Kinyarwanda |
| gom | Konkani |
| ko | Korean |
| kri | Krio |
| ku | Kurdish (Kurmanji) |
| ckb | Kurdish (Sorani) |
| ky | Kyrgyz |
| lo | Lao |
| la | Latin |
| lv | Latvian |
| ln | Lingala |
| lt | Lithuanian |
| lg | Luganda |
| lb | Luxembourgish |
| mk | Macedonian |
| mai | Maithili |
| mg | Malagasy |
| ms | Malay |
| ml | Malayalam |
| mt | Maltese |
| mi | Maori |
| mr | Marathi |
| mni-Mtei | Meiteilon (Manipuri) |
| lus | Mizo |
| mn | Mongolian |
| my | Myanmar |
| ne | Nepali |
| no | Norwegian |
| or | Odia (Oriya) |
| om | Oromo |
| ps | Pashto |
| fa | Persian |
| pl | Polish |
| pt | Portuguese |
| pa | Punjabi |
| qu | Quechua |
| ro | Romanian |
| ru | Russian |
| sm | Samoan |
| sa | Sanskrit |
| gd | Scots Gaelic |
| nso | Sepedi |
| sr | Serbian |
| st | Sesotho |
| sn | Shona |
| sd | Sindhi |
| si | Sinhala |
| sk | Slovak |
| sl | Slovenian |
| so | Somali |
| es | Spanish |
| su | Sundanese |
| sw | Swahili |
| sv | Swedish |
| tg | Tajik |
| ta | Tamil |
| tt | Tatar |
| te | Telugu |
| th | Thai |
| ti | Tigrinya |
| ts | Tsonga |
| tr | Turkish |
| tk | Turkmen |
| ak | Twi |
| uk | Ukrainian |
| ur | Urdu |
| ug | Uyghur |
| uz | Uzbek |
| vi | Vietnamese |
| cy | Welsh |
| xh | Xhosa |
| yi | Yiddish |
| yo | Yoruba |
| zu | Zulu |
Coqui Engine
Coqui engine is the default engine if no other engine is specified with the -e parameter.
To use voices from Coqui:
Voices (-v parameter)
You may either use one of the predefined coqui voices or clone your own voice.
Predefined Voices
To use a predefined voice submit the name of one of the following voices:
'Claribel Dervla', 'Daisy Studious', 'Gracie Wise', 'Tammie Ema', 'Alison Dietlinde', 'Ana Florence', 'Annmarie Nele', 'Asya Anara', 'Brenda Stern', 'Gitta Nikolina', 'Henriette Usha', 'Sofia Hellen', 'Tammy Grit', 'Tanja Adelina', 'Vjollca Johnnie', 'Andrew Chipper', 'Badr Odhiambo', 'Dionisio Schuyler', 'Royston Min', 'Viktor Eka', 'Abrahan Mack', 'Adde Michal', 'Baldur Sanjin', 'Craig Gutsy', 'Damien Black', 'Gilberto Mathias', 'Ilkin Urbano', 'Kazuhiko Atallah', 'Ludvig Milivoj', 'Suad Qasim', 'Torcull Diarmuid', 'Viktor Menelaos', 'Zacharie Aimilios', 'Nova Hogarth', 'Maja Ruoho', 'Uta Obando', 'Lidiya Szekeres', 'Chandra MacFarland', 'Szofi Granger', 'Camilla Holmström', 'Lilya Stainthorpe', 'Zofija Kendrick', 'Narelle Moon', 'Barbora MacLean', 'Alexandra Hisakawa', 'Alma María', 'Rosemary Okafor', 'Ige Behringer', 'Filip Traverse', 'Damjan Chapman', 'Wulf Carlevaro', 'Aaron Dreschner', 'Kumar Dahl', 'Eugenio Mataracı', 'Ferran Simen', 'Xavier Hayasaka', 'Luis Moray', 'Marcos Rudaski'
💡 Tip: simply write -v gracie as also parts of voice names are recognized and it's case-insensitive
Cloned Voices
Submit path to one or more audiofiles containing 16 bit 24kHz mono source material as reference wavs.
Example:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c -e coqui -v female.wav
The Art of Choosing a Reference Wav
- A 24000, 44100 or 22050 Hz 16-bit mono wav file of 10-30 seconds is your golden ticket.
- 24k mono 16 is my default, but I also had voices where I found 44100 32-bit to yield best results
- I test voices with this tool before rendering
- Audacity is your friend for adjusting sample rates. Experiment with frame rates for best results!
Fixed TTS Model Download Folder
Keep your models organized! Set COQUI_MODEL_PATH to your preferred folder.
Windows example:
setx COQUI_MODEL_PATH "C:\Downloads\CoquiModels"
Elevenlabs Engine
[!NOTE] To use Elevenlabs voices you need the API Key stored in env variable ELEVENLABS_API_KEY
All voices are synthesized with the multilingual-v1 model.
[!CAUTION] Elevenlabs is a pricy API. Focus on short videos. Don't let a work-in-progress script like this run unattended on a pay-per-use API. Bugs could be very annoying when occurring at the end of a pricy long rendering process.
To use voices from Elevenlabs:
Voices (-v parameter)
Submit name(s) of either a generated or predefined voice.
Example:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c -e elevenlabs -v Giovanni
[!TIP] Test rendering with a free engine like coqui first before using pricy ones.
OpenAI Engine
[!NOTE] To use OpenAI TTS voices you need the API Key stored in env variable OPENAI_API_KEY
To use voices from OpenAI:
Voice (-v parameter)
Submit name of voice. Currently only one voice for OpenAI supported. Alloy, echo, fable, onyx, nova or shimmer.
Example:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c -e openai -v shimmer
Azure Engine
[!NOTE] To use Azure voices you need the API Key for SpeechService resource in AZURE_SPEECH_KEY and the region identifier in AZURE_SPEECH_REGION
To use voices from Azure:
Voices (-v parameter)
Submit name(s) of either a generated or predefined voice.
Example:
turnvoice https://www.youtube.com/watch?v=BqnAeUoqFAM -e azure -v ChristopherNeural
System Engine
To use system voices:
Voices (-v parameter)
Submit name(s) of voices as string.
Example:
turnvoice https://www.youtube.com/watch?v=BqnAeUoqFAM -e system -v David
What to expect
- early alpha / work-in-progress, so bugs might occur (please report, need to be aware to fix)
- might not always achieve perfect lip synchronization, especially when translating to a different language
- speaker detection does not work that well, probably doing something wrong or or perhaps the tech[^5] is not yet ready to be reliable
- translation feature is currently in experimental prototype state (powered by deep-translate) and still produces very imperfect results
- occasionally, the synthesis might introduce unexpected noises or distortions in the audio (we got way better reducing artifacts with the new v0.0.30 algo)
- spleeter might get confused when a spoken voice and backmusic with singing are present together in the source audio
Source Quality
- delivers best results with YouTube videos featuring clear spoken content (podcasts, educational videos)
- requires a high-quality, clean source WAV file for effective voice cloning
Pro Tips
How to exchange a single speaker
First perform a speaker analysis with -a parameter:
turnvoice https://www.youtube.com/watch?v=2N3PsXPdkmM -a
Then select a speaker from the list with -s parameter
turnvoice https://www.youtube.com/watch?v=2N3PsXPdkmM -s 2
License
TurnVoice is proudly under the Coqui Public Model License 1.0.0.
Contact 🤝
Share your funniest or most creative TurnVoice creations with me!
And if you've got a cool feature idea or just want to say hi, drop me a line on
If you like the repo please leave a star
✨ 🌟 ✨
[^1]: State is work-in-progress (early pre-alpha). Ülease expect CLI API changes to come and sorry in advance if anything does not work as expected.
Developed on Python 3.11.4 under Win 10.
[^2]: Rubberband is needed to pitchpreserve timestretch audios for fitting synthesis into timewindow.
[^3]: ffmpeg is needed to convert mp3 files into wav
[^4]: Huggingface access token is needed to download the speaker diarization model for identifying speakers with pyannote.audio.
[^5]: Speaker diarization is performed with the pyannote.audio default HF implementation on the vocals track splitted from the original audio.
[^6]: Generates costs. Uses gpt-4-1106-preview model and needs OpenAI API Key stored in env variable OPENAI_API_KEY.
[^7]: Generates costs. Elevenlabs is pricy, OpenAI TTS, Azure are affordable. Needs API Keys stored in env variables, see engine information for details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file TurnVoice-0.0.65.tar.gz.
File metadata
- Download URL: TurnVoice-0.0.65.tar.gz
- Upload date:
- Size: 3.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a2e880e30d63d36924dd8e669a60552ae269644ae2219750fa1fb38b217e99bd
|
|
| MD5 |
47f6293da1f1243cef27dcdd566ae7c0
|
|
| BLAKE2b-256 |
37af26b5515db1048c60364113de4da2ecfb7125339140eb98f5f6109081a5bf
|
File details
Details for the file TurnVoice-0.0.65-py3-none-any.whl.
File metadata
- Download URL: TurnVoice-0.0.65-py3-none-any.whl
- Upload date:
- Size: 3.3 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8809533d83b525d162fe0cf32062090fa76d56c7c3c1852689c6acf4aeecb3a9
|
|
| MD5 |
20a1c6fe0f56c468e46a56d5b29251a1
|
|
| BLAKE2b-256 |
7b706f2046a13c6164e759b6df88d822cd89db800e5e28559ec027694dbec732
|







