2-5X faster training, reinforcement learning & finetuning

Project description

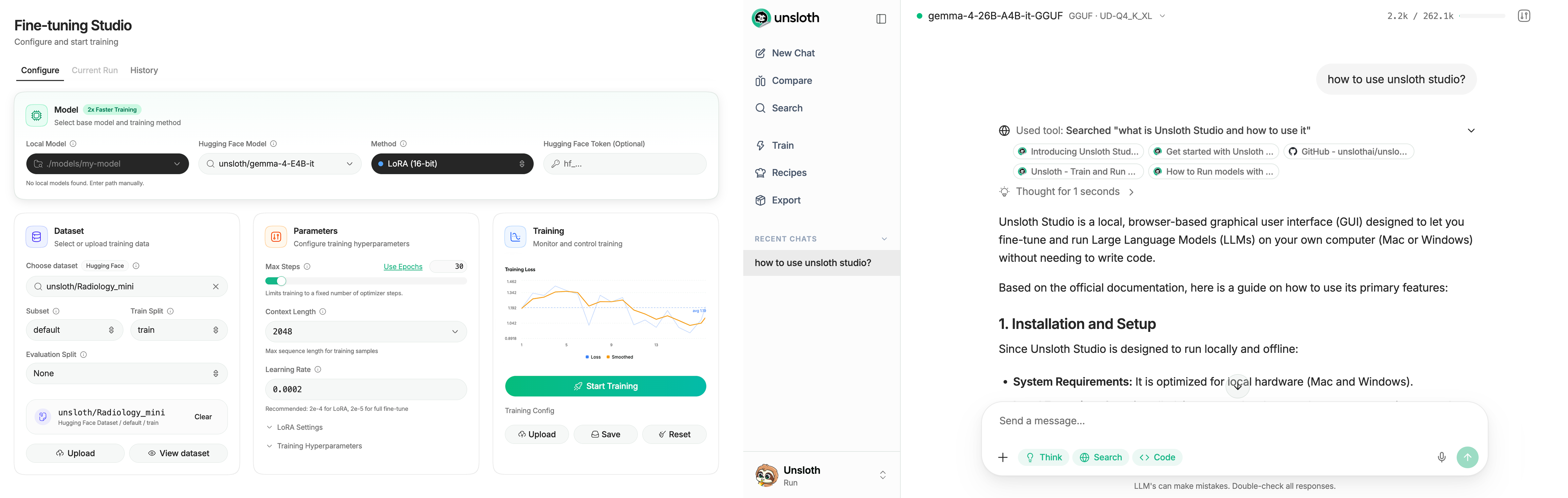
Unsloth Studio lets you run and train models locally.
Features • News • Quickstart • Notebooks • Documentation
⚡ Get started
macOS, Linux, WSL:
curl -fsSL https://unsloth.ai/install.sh | sh
Windows:
irm https://unsloth.ai/install.ps1 | iex
Community:
⭐ Features
Unsloth Studio (Beta) lets you run and train text, audio, embedding, vision models on Windows, Linux and macOS.
Inference
- Search + download + run models including GGUF, LoRA adapters, safetensors
- Export models: Save or export models to GGUF, 16-bit safetensors and other formats.
- Tool calling: Support for self-healing tool calling and web search
- Code execution: lets LLMs test code in Claude artifacts and sandbox environments
- API inference endpoint: Deploy and run local LLMs in Claude Code, Codex tools with Unsloth
- Auto set inference settings and customize chat templates.
- We work directly with teams behind gpt-oss, Qwen3, Llama 4, Mistral, Gemma 1-3, and Phi-4, where we’ve fixed bugs that improve model accuracy.
- Chat with images, audio, PDFs, code, DOCX and more. Connect API providers (OpenAI, Anthropic) or servers (vLLM, Ollama).
- Compare any two models side by side with the same prompt.
- OpenAI/Anthropic-compatible APIs: Serve local models through
/v1/chat/completions,/v1/responsesand/v1/messages. - Connect local models to agents: Use
unsloth startwith Claude Code, Codex, Hermes and more. - Web/PDF search can read PDF papers, manuals and other PDF results.
- GGUF hardware controls: Choose GPUs/layers, offload MoE experts, use multi-GPU or Tensor Parallelism.
- The opt-in MCP control endpoint lets AI clients manage models, training, recipes and exports.
Training
- Train and RL 500+ models up to 2x faster with 70% less VRAM; MoE up to 12x faster.
- Train and run RL on AMD GPUs across Windows, WSL and Linux.
- Data Recipes: Auto-create datasets from PDF, CSV, DOCX etc. Edit data in a visual-node workflow.
- Reinforcement Learning uses 80% less VRAM for GRPO, FP8 and vision RL, with 7x longer contexts.
- Long-context training: 3x faster, 30% less VRAM and 500K+ context.
- Supports LoRA/QLoRA, full fine-tuning, RL, pretraining, 4-bit, 16-bit and FP8.
- Custom Triton and mathematical kernels built with PyTorch and Hugging Face.
- Observability: Monitor training live, track loss and GPU usage and customize graphs.
- Multi-GPU training is supported, with major improvements coming soon.
🚀 Unsloth Start
Unsloth Start connects Claude Code, Codex and other agents to local models with one command.
Start Unsloth, load a model, open your project folder, then run:
unsloth start claude
Replace claude with any supported agent:
| Agent | Command |
|---|---|
| Claude Code | unsloth start claude |
| OpenAI Codex | unsloth start codex |
| Hermes Agent | unsloth start hermes |
| OpenClaw | unsloth start openclaw |
| OpenCode | unsloth start opencode |
| Pi Coding Agent | unsloth start pi |
📥 Install
Unsloth can be used in two ways: through Unsloth Studio, the web UI, or through Unsloth Core, the code-based version. Each has different requirements.
Unsloth Studio (web UI)
Unsloth Studio (Beta) works on Windows, Linux, WSL and macOS.
- CPU: Supported for Chat and Data Recipes currently
- NVIDIA: Training works on RTX 30/40/50, Blackwell, DGX Spark, Station and more
- macOS: Training, MLX and GGUF inference are ALL supported.
- AMD: Training, RL, chat and deployment work on Windows, WSL and Linux. Read the AMD guide.
- Vulkan: GGUF inference is supported on compatible GPUs, including Intel GPUs.
- Multi-GPU: Available now, with a major upgrade on the way
macOS, Linux, WSL:
curl -fsSL https://unsloth.ai/install.sh | sh
Use the same command to update.
Windows:
irm https://unsloth.ai/install.ps1 | iex
Use the same command to update.
Launch
unsloth studio -p 8888
For LAN or cloud access, add -H 0.0.0.0 (raw port only; add --cloudflare for a public URL). By default, Unsloth is accessible only locally.
To reach Unsloth over HTTPS, use unsloth studio --secure. Unsloth stays bound to localhost and is reached only through a free Cloudflare tunnel, which publishes it at a public https://*.trycloudflare.com URL (it fails closed if the tunnel can't start, so the raw port is never exposed). This makes Unsloth reachable from the internet, so anyone with the link and API key can use it and run code: keep your API key private (see Remote access below).
Docker
Use our Docker image unsloth/unsloth container. Run:
docker run -d -e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 8000:8000 -p 2222:22 \
-v $(pwd)/work:/workspace/work \
--gpus all \
unsloth/unsloth
Developer, Nightly, Uninstall
To see developer, nightly and uninstallation etc. instructions, see advanced installation.
Unsloth Core (code-based)
Linux, WSL:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_env --python 3.13
source unsloth_env/bin/activate
uv pip install unsloth --torch-backend=auto
Windows:
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_env --python 3.13
.\unsloth_env\Scripts\activate
uv pip install unsloth --torch-backend=auto
For Windows, pip install unsloth works only if you have PyTorch installed. Read our Windows Guide.
You can use the same Docker image as Unsloth Studio.
AMD, Intel:
For RTX 50x, B200, 6000 GPUs: uv pip install unsloth --torch-backend=auto. Read our guides for: Blackwell and DGX Spark.
To install Unsloth on AMD and Intel GPUs, follow our AMD Guide and Intel Guide.
📒 Free Notebooks
Train for free with our notebooks. You can use our new free Unsloth Studio notebook to run and train models for free in a web UI. Read our guide. Add dataset, run, then deploy your trained model.
| Model | Free Notebooks | Performance | Memory use |
|---|---|---|---|
| Gemma 4 (E2B) | ▶️ Start for free | 1.5x faster | 50% less |
| Qwen3.5 (4B) | ▶️ Start for free | 1.5x faster | 60% less |
| gpt-oss (20B) | ▶️ Start for free | 2x faster | 70% less |
| Qwen3.5 GSPO | ▶️ Start for free | 2x faster | 70% less |
| gpt-oss (20B): GRPO | ▶️ Start for free | 2x faster | 80% less |
| Qwen3: Advanced GRPO | ▶️ Start for free | 2x faster | 70% less |
| embeddinggemma (300M) | ▶️ Start for free | 2x faster | 20% less |
| Mistral Ministral 3 (3B) | ▶️ Start for free | 1.5x faster | 60% less |
| Llama 3.1 (8B) Alpaca | ▶️ Start for free | 2x faster | 70% less |
| Llama 3.2 Conversational | ▶️ Start for free | 2x faster | 70% less |
| Orpheus-TTS (3B) | ▶️ Start for free | 1.5x faster | 50% less |
- See all our notebooks for: Kaggle, GRPO, TTS, embedding & Vision
- See all our models and all our notebooks
- See detailed documentation for Unsloth here
🦥 Unsloth News
- AMD training: Train, run RL, chat and deploy on AMD GPUs across Windows, WSL and Linux. Guide
- GGUF hardware controls: Choose GPU/layer placement, offload MoE experts and use multi-GPU or Tensor Parallelism. #6414
- Local models for any agent: Use
unsloth startwith Claude Code, Codex, Hermes, OpenCode, OpenClaw, Pi and more through Unsloth's OpenAI- and Anthropic-compatible APIs. Guide - MCP control endpoint: Let compatible clients manage models, training, recipes, checkpoints and exports. #7191
- Local inference reliability: Resume long chats faster, recover stalled downloads and reuse existing GGUF files. #7204 • #6858 • #7209
- New models: Qwen-AgentWorld, Ornith, Kimi K2.7 Code and MiniMax M3
- GLM-5.2: Run Z.ai's 744B-parameter, 1M-context open model locally with Unsloth Dynamic GGUFs. Guide
- DeepSeek-V4: Run DeepSeek-V4-Flash locally with corrected multi-turn and tool-calling behavior. Guide
- DiffusionGemma: Run and fine-tune Google's diffusion language model with 1.8x faster inference in Unsloth Studio. Guide
- Qwen3.6: Run and train Qwen3.6 with MTP for 1.4-2.2x faster inference and NVFP4 quants for supported GPUs. Guide
- Gemma 4: Run and train Gemma 4 text, image and audio models with QAT, MTP, GGUF and MLX support. Guide
- MCP servers: Connect local models to files, apps, databases and external tools through Model Context Protocol. Guide
- Connections: Mix local models with API providers (OpenAI, Anthropic) or servers (vLLM, Ollama) in the same interface. Guide
- Introducing Unsloth Studio: our new web UI for running and training LLMs. Blog
- Train MoE LLMs 12x faster with 35% less VRAM - DeepSeek, GLM, Qwen and gpt-oss. Blog
- Embedding models: Unsloth now supports ~1.8-3.3x faster embedding fine-tuning. Blog • Notebooks
- New 7x longer context RL vs. all other setups, via our new batching algorithms. Blog
- New RoPE & MLP Triton Kernels & Padding Free + Packing: 3x faster training & 30% less VRAM. Blog
- 500K Context: Training a 20B model with >500K context is now possible on an 80GB GPU. Blog
- FP8 & Vision RL: You can now do FP8 & VLM GRPO on consumer GPUs. FP8 Blog • Vision RL
📥 Advanced Installation
The below advanced instructions are for Unsloth Studio. For Unsloth Core advanced installation, view our docs.
Developer / Nightly / Experimental installs: macOS, Linux, WSL:
The developer install builds from the main branch, which is the latest (nightly) source.
git clone https://github.com/unslothai/unsloth
cd unsloth
./install.sh --local
unsloth studio -p 8888
To install into an isolated location (its own virtual env, auth/, studio.db, cache and llama.cpp build), set UNSLOTH_STUDIO_HOME and pass it again at launch:
UNSLOTH_STUDIO_HOME="$PWD/.studio" ./install.sh --local
UNSLOTH_STUDIO_HOME="$PWD/.studio" unsloth studio -p 8888
Then to update :
cd unsloth && git pull
./install.sh --local
unsloth studio -p 8888
Developer / Nightly / Experimental installs: Windows PowerShell:
The developer install builds from the main branch, which is the latest (nightly) source.
git clone https://github.com/unslothai/unsloth.git
cd unsloth
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -p 8888
To install into an isolated location (its own virtual env, auth/, studio.db, cache and llama.cpp build), set UNSLOTH_STUDIO_HOME and pass it again at launch:
$env:UNSLOTH_STUDIO_HOME="$PWD\.studio"; .\install.ps1 --local
$env:UNSLOTH_STUDIO_HOME="$PWD\.studio"; unsloth studio -p 8888
Then to update :
cd unsloth; git pull
.\install.ps1 --local
unsloth studio -p 8888
Remote access: --secure (HTTPS tunnel) vs raw port
By default unsloth studio binds to 127.0.0.1 (this machine only). To reach it from another device, pick one of:
--secure(recommended): serve only through a free Cloudflare HTTPS link. Unsloth stays bound to localhost and the tunnel provides the public URL; it fails closed (does not start) if the tunnel can't come up, so the raw port is never exposed.
unsloth studio --secure -p 8888
-H 0.0.0.0: bind the raw port on all network interfaces, reachable from anywhere on the network (subject to your firewall). It does not create a public internet URL; add--cloudflareto also publish an internet-reachablehttps://*.trycloudflare.comlink even behind a firewall. Only use this on a network you trust.
unsloth studio -H 0.0.0.0 -p 8888
The Cloudflare tunnel is off by default: -H 0.0.0.0 exposes the raw port only, not a public internet URL. Pair the wildcard bind with --cloudflare (unsloth studio -H 0.0.0.0 --cloudflare) to also publish a public https://*.trycloudflare.com link, or prefer --secure (above), which keeps the raw port private. --cloudflare has no effect on a loopback bind.
The first time Unsloth is published on a public URL (--secure or --cloudflare) with the auto-generated admin password still in place, it asks for a new admin password in the terminal (masked input with confirmation) before the public link goes up. Without an attached terminal it warns instead and keeps the bootstrap deadline: Unsloth shuts down after UNSLOTH_STUDIO_BOOTSTRAP_TIMEOUT (default 1 hour) unless the password is changed in the web UI.
For headless setups that cannot answer that prompt, set the initial admin password non-interactively with --password (only takes effect when no password is set yet; if one already exists it is a hard error, so rotate later with unsloth studio reset-password):
unsloth studio --secure --password 'your-strong-password' # visible in `ps`/history
UNSLOTH_STUDIO_PASSWORD='your-strong-password' unsloth studio --secure # via env var
printf '%s\n' 'your-strong-password' | unsloth studio --secure --password - # via stdin
A literal --password VALUE is visible in the process list and shell history, so prefer the UNSLOTH_STUDIO_PASSWORD env var or --password - (stdin) for automation. This applies to any launch (public or a headless -H 0.0.0.0 bind), and the password is set in the parent before the server binds, so it never reaches a re-executed child process.
Server-side tools (web search, Python and terminal code execution) run as your user and are on by default. Anyone who can reach the server with the API key can run code on this machine, so keep your API key private and pass --disable-tools when exposing Unsloth.
Advanced launch options
Installer options can be passed as environment variables. On macOS, Linux and WSL place the variable after the pipe so the shell passes it to sh; on Windows set it with $env: before piping to iex.
Skip PyTorch (GGUF-only mode):
curl -fsSL https://unsloth.ai/install.sh | UNSLOTH_NO_TORCH=1 sh
$env:UNSLOTH_NO_TORCH=1; irm https://unsloth.ai/install.ps1 | iex
Skip the post-install prompt that starts Unsloth (useful for automated installs):
curl -fsSL https://unsloth.ai/install.sh | UNSLOTH_SKIP_AUTOSTART=1 sh
$env:UNSLOTH_SKIP_AUTOSTART=1; irm https://unsloth.ai/install.ps1 | iex
Pin the Python version:
curl -fsSL https://unsloth.ai/install.sh | UNSLOTH_PYTHON=3.12 sh
$env:UNSLOTH_PYTHON='3.12'; irm https://unsloth.ai/install.ps1 | iex
Install to a custom location with UNSLOTH_STUDIO_HOME:
curl -fsSL https://unsloth.ai/install.sh | UNSLOTH_STUDIO_HOME=/abs/path sh
$env:UNSLOTH_STUDIO_HOME='C:\path'; irm https://unsloth.ai/install.ps1 | iex
On macOS, the installer defaults to the system certificate store (UV_SYSTEM_CERTS=1) so uv trusts the CAs in your Keychain, needed behind TLS-inspecting proxies (Cisco Umbrella, Zscaler, etc.). Opt out with:
curl -fsSL https://unsloth.ai/install.sh | UV_SYSTEM_CERTS=0 sh
Point the frontend build at a corporate npm mirror/proxy with UNSLOTH_NPM_REGISTRY (for the developer install behind a firewall that blocks registry.npmjs.org):
UNSLOTH_NPM_REGISTRY=https://artifactory.example.com/api/npm/npm/ ./install.sh --local
$env:UNSLOTH_NPM_REGISTRY='https://artifactory.example.com/api/npm/npm/'; .\install.ps1 --local
It is threaded as --registry into the Unsloth frontend npm/bun installs; the supply-chain locks (7-day min-release-age, exact version pins) stay in force.
Cap Unsloth's native CPU thread pools on high-core hosts: UNSLOTH_CPU_THREADS=8 unsloth studio -p 8888.
Uninstall
The recommended way to fully remove Unsloth Studio is the matching uninstall script for your OS. It stops any running servers, removes the install dir, the launcher data dir, the desktop shortcut, and any platform-specific entries (macOS .app bundle + Launch Services on Mac; Start Menu, HKCU\Software\Unsloth registry key and user PATH entries on Windows):
- MacOS, WSL, Linux:
curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/main/scripts/uninstall.sh | sh - Windows (PowerShell):
irm https://raw.githubusercontent.com/unslothai/unsloth/main/scripts/uninstall.ps1 | iex
If you only want to drop the install dir and keep the launcher/shortcut for a later reinstall, you can instead run rm -rf ~/.unsloth/studio (Mac/Linux/WSL) or Remove-Item -Recurse -Force "$HOME\.unsloth\studio" (Windows). The model cache at ~/.cache/huggingface is not touched by any of these.
For more info, see our docs.
Deleting model files
You can delete old model files either from the bin icon in model search or by removing the relevant cached model folder from the default Hugging Face cache directory. By default, HF uses:
- MacOS, Linux, WSL:
~/.cache/huggingface/hub/ - Windows:
%USERPROFILE%\.cache\huggingface\hub\
💚 Community and Links
| Type | Links |
|---|---|
| Join Discord server | |
| Join Reddit community | |
| 📚 Documentation & Wiki | Read Our Docs |
| Follow us on X | |
| 🔮 Our Models | Unsloth Catalog |
| ✍️ Blog | Read our Blogs |
Citation
You can cite the Unsloth repo as follows:
@software{unsloth,
author = {Daniel Han, Michael Han and Unsloth team},
title = {Unsloth},
url = {https://github.com/unslothai/unsloth},
year = {2023}
}
If you trained a model with 🦥Unsloth, you can use this cool sticker!

License
Unsloth uses a dual-licensing model of Apache 2.0 and AGPL-3.0. The core Unsloth package remains licensed under Apache 2.0, while certain optional components, such as the Unsloth Studio UI are licensed under the open-source license AGPL-3.0.
This structure helps support ongoing Unsloth development while keeping the project open source and enabling the broader ecosystem to continue growing.
Thank You to
- The llama.cpp library that lets users run and save models with Unsloth
- The Hugging Face team and their libraries: transformers and TRL
- The Pytorch and Torch AO team for their contributions
- NVIDIA for their NeMo DataDesigner library and their contributions
- And of course for every single person who has contributed or has used Unsloth!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file unsloth-2026.7.4.tar.gz.
File metadata
- Download URL: unsloth-2026.7.4.tar.gz
- Upload date:
- Size: 80.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dff7ca9e1e2846d325a145759baca0d0b574620e78d0d6541b9931133eb537b9
|
|
| MD5 |
277a2a0183b5294ee70420fec2a409e1
|
|
| BLAKE2b-256 |
cae23af3359bc80a8f3c0d952da18966c4dff6781225147efa926ddcdcf71b6d
|
File details
Details for the file unsloth-2026.7.4-py3-none-any.whl.
File metadata
- Download URL: unsloth-2026.7.4-py3-none-any.whl
- Upload date:
- Size: 75.8 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
843a217a3bfd14a79f153c97777ed442328c48ad772ea3068a8456bfb20ec39c
|
|
| MD5 |
560def95ff17029bcb7df230960380c7
|
|
| BLAKE2b-256 |
2a36fe8697a4a67c6899e156c83f018d4bbfa9d6e7303e7aae264e69df981b03
|







