UQLM (Uncertainty Quantification for Language Models) is a Python package for UQ-based LLM hallucination detection.

Project description

uqlm: Uncertainty Quantification for Language Models










UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques.
Installation
The latest version can be installed from PyPI:
pip install uqlm
Hallucination Detection
UQLM provides a suite of response-level scorers for quantifying the uncertainty of Large Language Model (LLM) outputs. Each scorer returns a confidence score between 0 and 1, where higher scores indicate a lower likelihood of errors or hallucinations. We categorize these scorers into different types:
| Scorer Type | Added Latency | Added Cost | Compatibility | Off-the-Shelf / Effort |
|---|---|---|---|---|
| Black-Box Scorers | ⏱️ Medium-High (multiple generations & comparisons) | 💸 High (multiple LLM calls) | 🌍 Universal (works with any LLM) | ✅ Off-the-shelf |
| White-Box Scorers | ⚡ Minimal* (token probabilities already returned) | ✔️ None* (no extra LLM calls) | 🔒 Limited (requires access to token probabilities) | ✅ Off-the-shelf |
| LLM-as-a-Judge Scorers | ⏳ Low-Medium (additional judge calls add latency) | 💵 Low-High (depends on number of judges) | 🌍 Universal (any LLM can serve as judge) | ✅ Off-the-shelf |
| Ensemble Scorers | 🔀 Flexible (combines various scorers) | 🔀 Flexible (combines various scorers) | 🔀 Flexible (combines various scorers) | ✅ Off-the-shelf (beginner-friendly); 🛠️ Can be tuned (best for advanced users) |
| Long-Text Scorers | ⏱️ High-Very high (multiple generations & claim-level comparisons) | 💸 High (multiple LLM calls) | 🌍 Universal | ✅ Off-the-shelf |
*Does not apply to multi-generation white-box scorers, which have higher cost and latency.
Below we provide illustrative code snippets and details about available scorers for each type.
Black-Box Scorers (Consistency-Based)
These scorers assess uncertainty by measuring the consistency of multiple responses generated from the same prompt. They are compatible with any LLM, intuitive to use, and don't require access to internal model states or token probabilities.
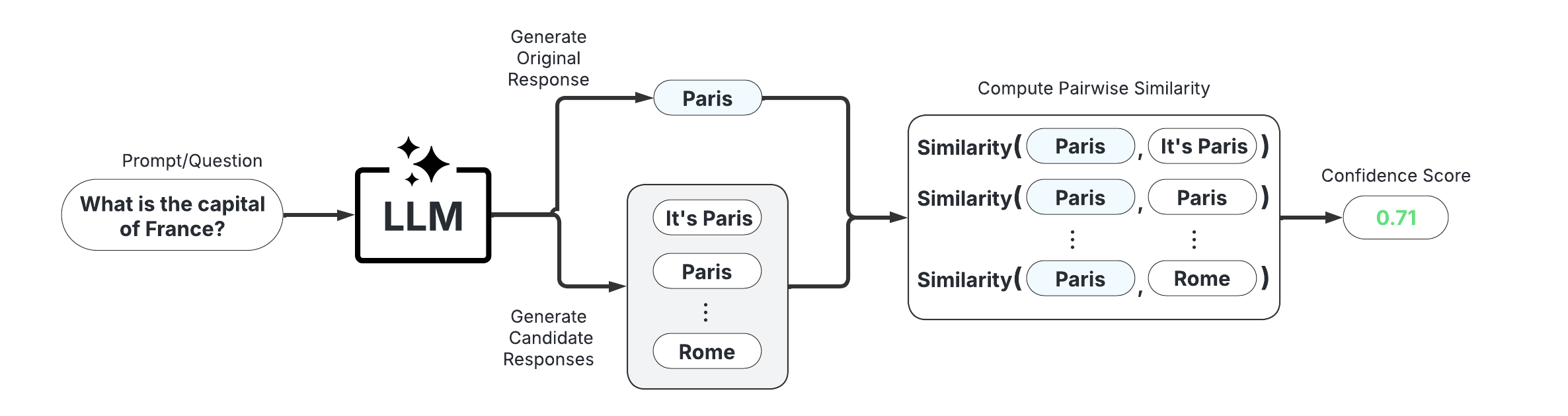
Example Usage:
Below is a sample of code illustrating how to use the BlackBoxUQ class to conduct hallucination detection.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
from uqlm import BlackBoxUQ
bbuq = BlackBoxUQ(llm=llm, scorers=["semantic_negentropy"], use_best=True)
results = await bbuq.generate_and_score(prompts=prompts, num_responses=5)
results.to_df()
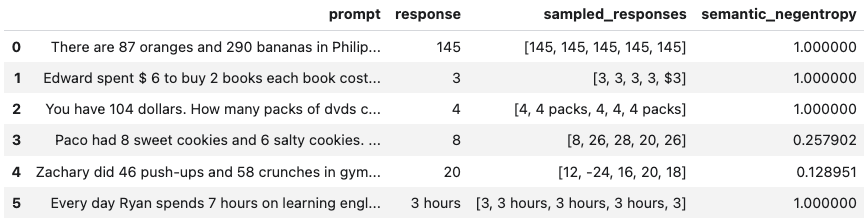
Above, use_best=True implements mitigation so that the uncertainty-minimized responses is selected. Note that although we use ChatOpenAI in this example, any LangChain Chat Model may be used. For a more detailed demo, refer to our Black-Box UQ Demo.
Available Scorers:
- Discrete Semantic Entropy (Farquhar et al., 2024; Bouchard & Chauhan, 2025)
- Number of Semantic Sets (Lin et al., 2024; Vashurin et al., 2025; Kuhn et al., 2023)
- Non-Contradiction Probability (Chen & Mueller, 2023; Lin et al., 2024; Manakul et al., 2023)
- Entailment Probability (Chen & Mueller, 2023; Lin et al., 2024; Manakul et al., 2023)
- Exact Match (Cole et al., 2023; Chen & Mueller, 2023)
- BERTScore (Manakul et al., 2023; Zheng et al., 2020)
- Cosine Similarity (Shorinwa et al., 2024; HuggingFace)
White-Box Scorers (Token-Probability-Based)
These scorers leverage token probabilities to estimate uncertainty. They offer single-generation scoring, which is significantly faster and cheaper than black-box methods, but require access to the LLM's internal probabilities, meaning they are not necessarily compatible with all LLMs/APIs.

Example Usage:
Below is a sample of code illustrating how to use the WhiteBoxUQ class to conduct hallucination detection.
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model='gemini-2.5-pro')
from uqlm import WhiteBoxUQ
wbuq = WhiteBoxUQ(llm=llm, scorers=["min_probability"])
results = await wbuq.generate_and_score(prompts=prompts)
results.to_df()

Again, any LangChain Chat Model may be used in place of ChatVertexAI. For more detailed examples, refer to our demo notebooks on Single-Generation White-Box UQ and/or Multi-Generation White-Box UQ.
Single-Generation Scorers (minimal latency, zero extra cost):
- Minimum token probability (Manakul et al., 2023)
- Length-Normalized Sequence Probability (Malinin & Gales, 2021)
- Sequence Probability (Vashurin et al., 2024)
- Mean Top-K Token Negentropy (Scalena et al., 2025; Manakul et al., 2023)
- Min Top-K Token Negentropy (Scalena et al., 2025; Manakul et al., 2023)
- Probability Margin (Farr et al., 2024)
Self-Reflection Scorers (one additional generation per response):
- P(True) (Kadavath et al., 2022)
Multi-Generation Scorers (several additional generations per response):
- Monte carlo sequence probability (Kuhn et al., 2023)
- Consistency and Confidence (CoCoA) (Vashurin et al., 2025)
- Semantic Entropy (Farquhar et al., 2024)
- Semantic Density (Qiu et al., 2024)
LLM-as-a-Judge Scorers
These scorers use one or more LLMs to evaluate the reliability of the original LLM's response. They offer high customizability through prompt engineering and the choice of judge LLM(s).
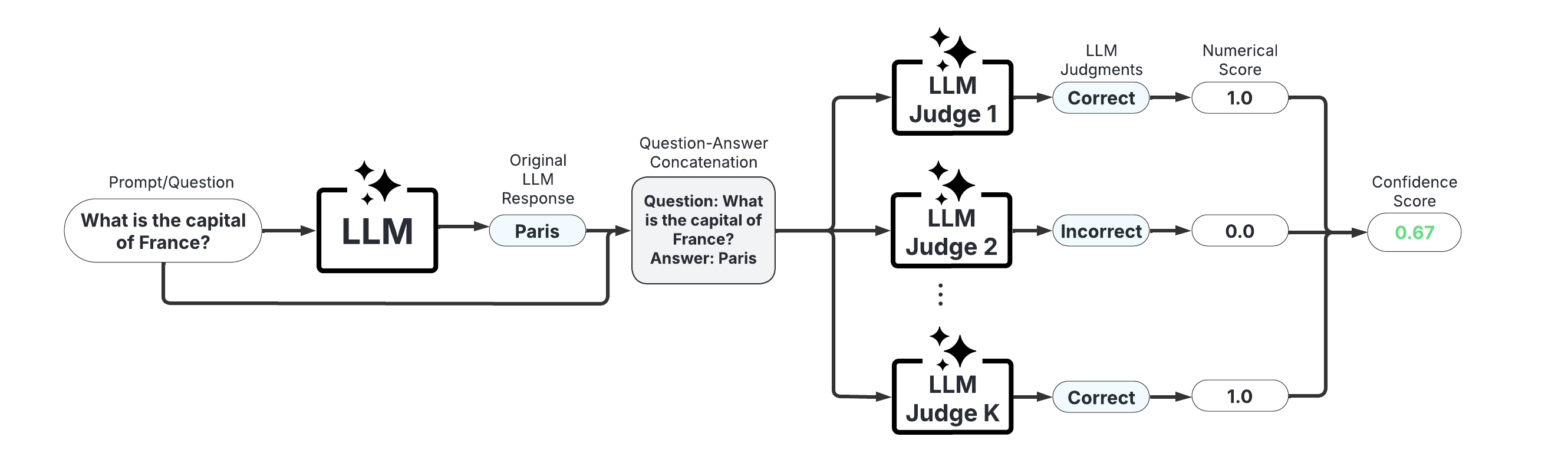
Example Usage:
Below is a sample of code illustrating how to use the LLMPanel class to conduct hallucination detection using a panel of LLM judges.
from langchain_ollama import ChatOllama
llama = ChatOllama(model="llama3")
mistral = ChatOllama(model="mistral")
qwen = ChatOllama(model="qwen3")
from uqlm import LLMPanel
panel = LLMPanel(llm=llama, judges=[llama, mistral, qwen])
results = await panel.generate_and_score(prompts=prompts)
results.to_df()

Note that although we use ChatOllama in this example, we can use any LangChain Chat Model as judges. For a more detailed demo illustrating how to customize a panel of LLM judges, refer to our LLM-as-a-Judge Demo.
Available Scorers:
- Categorical LLM-as-a-Judge (Manakul et al., 2023; Chen & Mueller, 2023; Luo et al., 2023)
- Continuous LLM-as-a-Judge (Xiong et al., 2024)
- Likert Scale LLM-as-a-Judge (Bai et al., 2023)
- Panel of LLM Judges (Verga et al., 2024)
Ensemble Scorers
These scorers leverage a weighted average of multiple individual scorers to provide a more robust uncertainty/confidence estimate. They offer high flexibility and customizability, allowing you to tailor the ensemble to specific use cases.
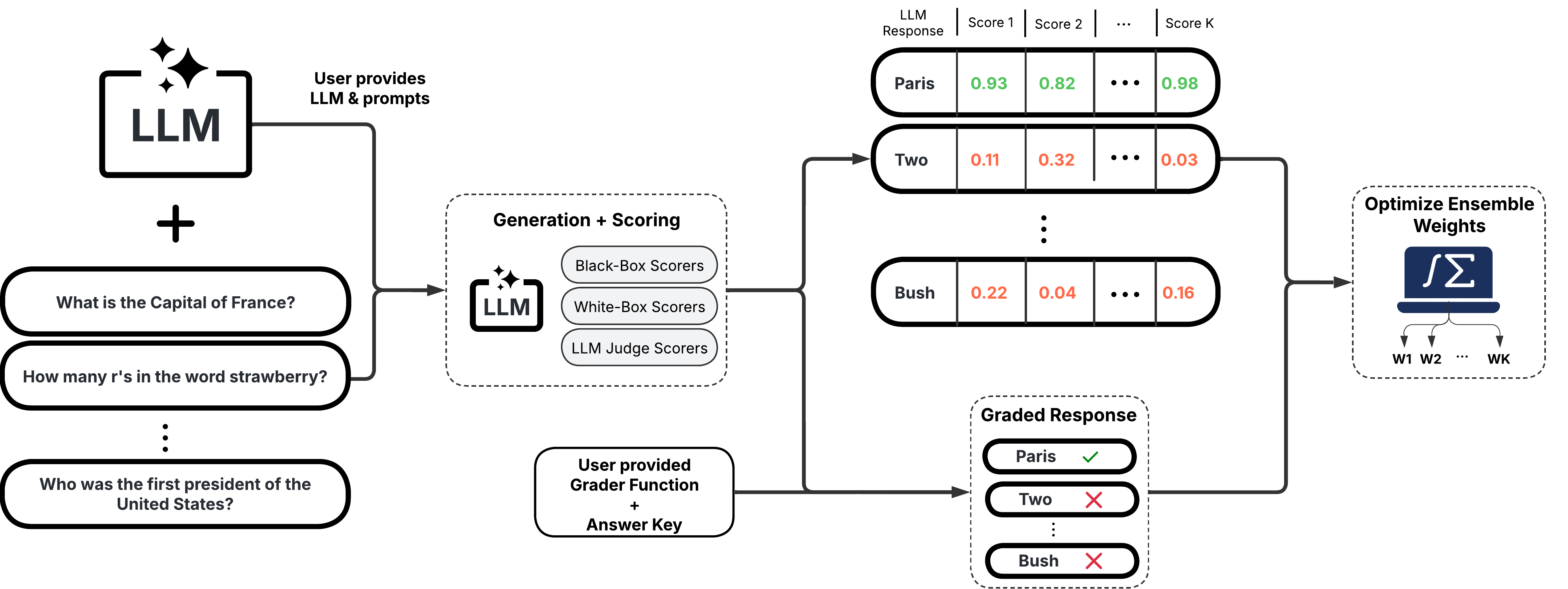
Example Usage:
Below is a sample of code illustrating how to use the UQEnsemble class to conduct hallucination detection.
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(deployment_name="gpt-4o", openai_api_type="azure", openai_api_version="2024-12-01-preview")
from uqlm import UQEnsemble
## ---Option 1: Off-the-Shelf Ensemble---
# uqe = UQEnsemble(llm=llm)
# results = await uqe.generate_and_score(prompts=prompts, num_responses=5)
## ---Option 2: Tuned Ensemble---
scorers = [ # specify which scorers to include
"exact_match", "noncontradiction", # black-box scorers
"min_probability", # white-box scorer
llm # use same LLM as a judge
]
uqe = UQEnsemble(llm=llm, scorers=scorers)
# Tune on tuning prompts with provided ground truth answers
tune_results = await uqe.tune(
prompts=tuning_prompts, ground_truth_answers=ground_truth_answers
)
# ensemble is now tuned - generate responses on new prompts
results = await uqe.generate_and_score(prompts=prompts)
results.to_df()

As with the other examples, any LangChain Chat Model may be used in place of AzureChatOpenAI. For more detailed demos, refer to our Off-the-Shelf Ensemble Demo (quick start) or our Ensemble Tuning Demo (advanced).
Available Scorers:
- BS Detector (Chen & Mueller, 2023)
- Generalized UQ Ensemble (Bouchard & Chauhan, 2025)
Long-Text Scorers (Claim-Level)
These scorers take a fine-grained approach and score confidence/uncertainty at the claim or sentence level. An extension of black-box scorers, long-text scorers sample multiple responses to the same prompt, decompose the original response into claims or sentences, and evaluate consistency of each original claim/sentence with the sampled responses.
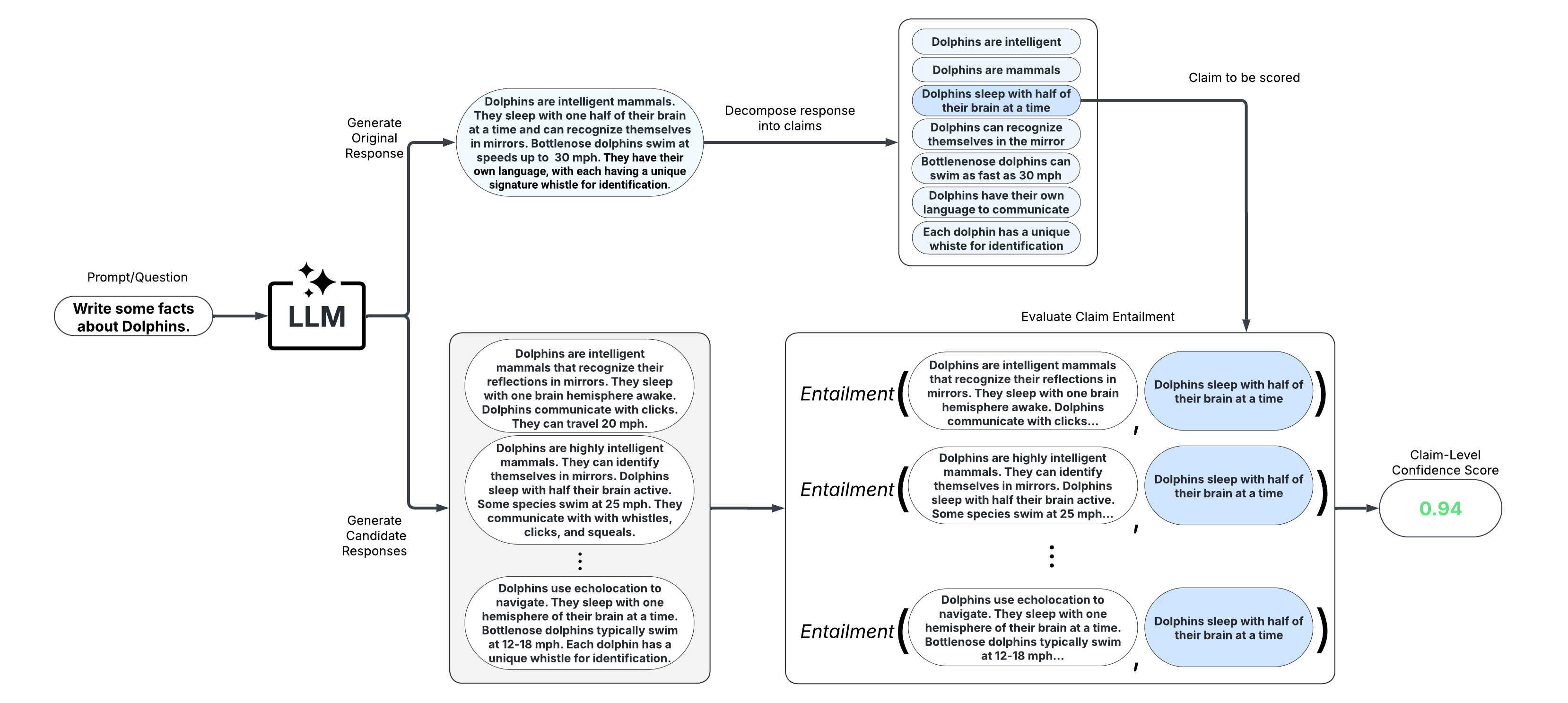
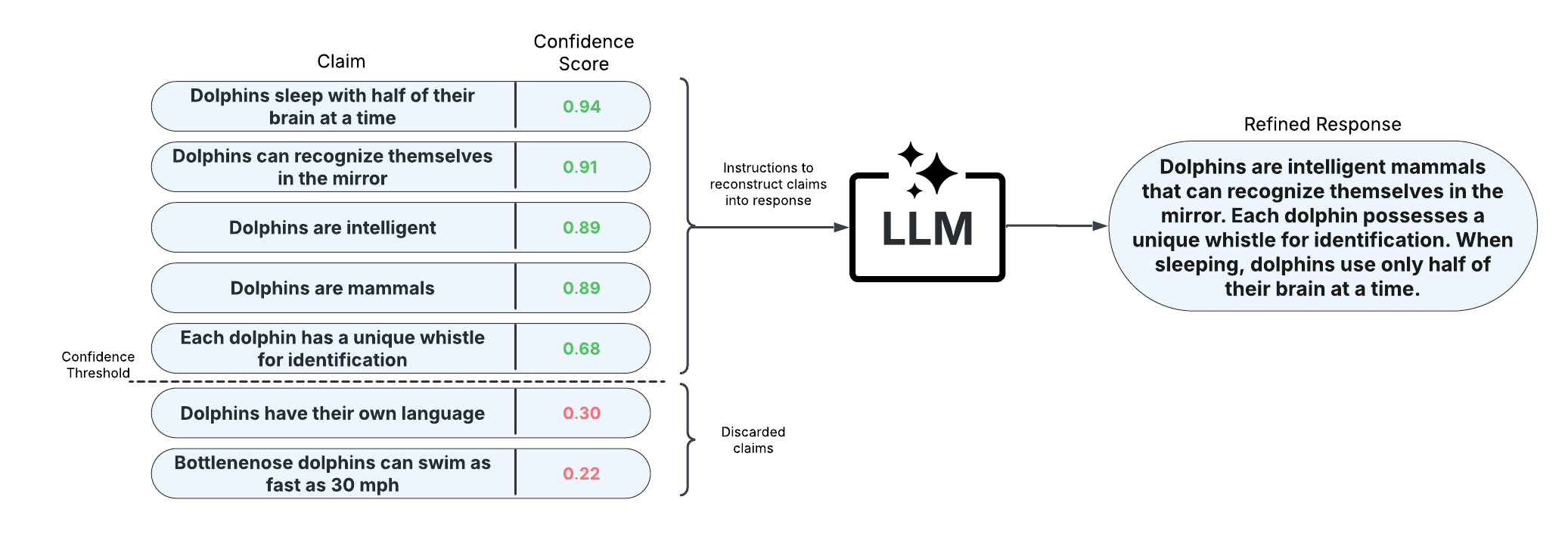
After scoring claims in the response, the response can be refined by removing claims with confidence scores less than a specified threshold and reconstructing the response from the retained claims. This approach allows for improved factual precision of long-text generations.
Example Usage:
Below is a sample of code illustrating how to use the LongTextUQ class to conduct claim-level hallucination detection and uncertainty-aware response refinement.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
from uqlm import LongTextUQ
luq = LongTextUQ(llm=llm, scorers=["entailment"], response_refinement=True)
results = await luq.generate_and_score(prompts=prompts, num_responses=5)
results_df = results.to_df()
results_df
# Preview the data for a specific claim in the first response
# results_df["claims_data"][0][0]
# Output:
# {
# 'claim': 'Suthida Bajrasudhabimalalakshana was born on June 3, 1978.',
# 'removed': False,
# 'entailment': 0.9548099517822266
# }

Above response and entailment reflect the original response and response-level confidence score, while refined_response and refined_entailment are the corresponding values after response refinement. The claims_data column includes granular data for each response, including claims, claim-level confidence scores, and whether each claim is retained in the response refinement process. We use ChatOpenAI in this example, any LangChain Chat Model may be used. For a more detailed demo, refer to our Long-Text UQ Demo.
Available Scorers:
- LUQ scorers (Zhang et al., 2024; Zhang et al., 2025)
- Graph-based scorers (Jiang et al., 2024)
- Generalized long-form semantic entropy (Farquhar et al., 2024)
Documentation
Check out our documentation site for detailed instructions on using this package, including API reference and more.
Example notebooks and tutorials
UQLM comes with a comprehensive set of example notebooks to help you get started with different uncertainty quantification approaches. These examples demonstrate how to use UQLM for various tasks, from basic hallucination detection to advanced ensemble methods.
Browse all example notebooks →
The examples directory contains tutorials for:
- Black-box and white-box uncertainty quantification
- Single and multi-generation approaches
- LLM-as-a-judge techniques
- Ensemble methods
- State-of-the-art techniques like Semantic Entropy and Semantic Density
- Multimodal uncertainty quantification
- Score calibration
Each notebook includes detailed explanations and code samples that you can adapt to your specific use case.
Citation
A technical description of the uqlm scorers and extensive experimental results are presented in this paper, published in Transactions on Machine Learning Research (TMLR). If you use our framework or toolkit, please cite:
@article{
bouchard2025uncertainty,
title={Uncertainty Quantification for Language Models: A Suite of Black-Box, White-Box, {LLM} Judge, and Ensemble Scorers},
author={Dylan Bouchard and Mohit Singh Chauhan},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2025},
url={https://openreview.net/forum?id=WOFspd4lq5},
note={}
}
The uqlm software package is described in this this paper, published in the Journal of Machine Learning Research (JMLR). If you use the software, please cite:
@article{JMLR:v27:25-1557,
author = {Dylan Bouchard and Mohit Singh Chauhan and David Skarbrevik and Ho-Kyeong Ra and Viren Bajaj and Zeya Ahmad},
title = {UQLM: A Python Package for Uncertainty Quantification in Large Language Models},
journal = {Journal of Machine Learning Research},
year = {2026},
volume = {27},
number = {13},
pages = {1--10},
url = {http://jmlr.org/papers/v27/25-1557.html}
}
The long-text methods and experiment results are described in this paper, available as a preprint on arXiv. To cite:
@misc{bouchard2026finegraineduncertaintyquantificationlongform,
title={Fine-Grained Uncertainty Quantification for Long-Form Language Model Outputs: A Comparative Study},
author={Dylan Bouchard and Mohit Singh Chauhan and Viren Bajaj and David Skarbrevik},
year={2026},
eprint={2602.17431},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2602.17431},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file uqlm-0.5.6.tar.gz.
File metadata
- Download URL: uqlm-0.5.6.tar.gz
- Upload date:
- Size: 10.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.29 {"installer":{"name":"uv","version":"0.9.29","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"11","id":"bullseye","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bb8f9d42860828a3e56ec9dbd9d16fbb92a04a69202f735408f4a193e65c8696
|
|
| MD5 |
98014f5b65d8d30f44996e0e97316e56
|
|
| BLAKE2b-256 |
06db16abb21063059bf69f311cb7f6f87753d355377885e1f5665b7ef89034b0
|
File details
Details for the file uqlm-0.5.6-py3-none-any.whl.
File metadata
- Download URL: uqlm-0.5.6-py3-none-any.whl
- Upload date:
- Size: 167.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.29 {"installer":{"name":"uv","version":"0.9.29","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Debian GNU/Linux","version":"11","id":"bullseye","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9c1b90fc7cd9e1e03c89627e433697e66f33e8fb8d3fff2273fd3114b6562800
|
|
| MD5 |
289bcef231f258c7bc06503e578ed90a
|
|
| BLAKE2b-256 |
a287069a45f3047146e41321284305f8b4e0eb2d6246f3e99b117258ad9011af
|







