A command-line tool to easily transcribe speech-based video files into clean text. also in Colab.

Project description
vid2cleantxt

vid2cleantxt: a transformers-based pipeline for turning heavily speech-based video files into clean, readable text from the audio.
TL;DR check out this Colab script to see a transcription and keyword extraction of a speech by John F. Kennedy by simply running all cells.
Table of Contents
- vid2cleantxt
- Motivation
- Overview
- Installation
- Application
- Design Choices & Troubleshooting
- What python package dependencies does this repo have?
- My computer crashes once it starts running the wav2vec2 model
- The transcription is not perfect, and therefore I am mad
- How can I improve the performance of the model from a word-error-rate perspective?
- Why use wav2vec2 instead of SpeechRecognition or other transcription methods?
- Errors
- Examples
- Future Work, Collaboration, & Citations
Motivation
Video, specifically audio, is an inefficient way to convey dense or technical information. The viewer has to sit through the whole thing, while only part of the video may be relevant to them. If you don't understand a statement or concept, you have to search through the video, or re-watch it. This project attempts to help solve that problem by converting long video files into text that can be easily searched and summarized.
Overview
Example Output
Example output text of a video transcription of JFK's speech on going to the moon:
vid2cleantxt output:
Now look into space to the moon and to the planets beyond and we have vowed that we shall not see it governed by a hostile flag of conquest but. By a banner of freedom and peace we have vowed that we shall not see space filled with weapons of man's destruction but with instruments of knowledge and understanding yet the vow. S of this nation can only be fulfilled if we in this nation are first and therefore we intend to be first. In short our leadership in science and industry our hopes for peace and security our obligations to ourselves as well as others all require. Us to make this effort to solve these mysteries to solve them for the good of all men and to become the world's leading space fearing nationwide set sail on this new sea. Because there is new knowledge to be gained and new rights to be won and they must be won and used for the progress of all before for space science like nuclear science and all techniques. Logo has no conscience of its own whether it will become a force for good or ill depends on man and only if the united states occupies a position of pre eminence. Can we help decide whether this new ocean will be a sea of peace or a new terrifying theatre of war I do not say that we should or will go on. ... (truncated for brevity)
See the demo notebook for the full text output.
Pipeline Intro

- The
transcribe.pyscript uses audio2text_functions.py to convert video files to .wav format audio chunks of duration X* seconds - transcribe all X audio chunks through a pretrained wav2vec2 model
- Write all results of the list into a text file, stores various runtime metrics into a separate text list, and deletes the .wav audio chunk directory after completed using them.
- (Optional) create two new text files: one with all transcriptions appended, and one with all metadata appended. The script then
- FOR each transcription text file:
- Passes the 'base' transcription text through a spell checker (Neuspell) and autocorrect spelling. Saves as new text file.
- Uses pySBD to infer sentence boundaries on the spell-corrected text and add periods in to delineate sentences. Saves as new file.
- Runs basic keyword extraction (via YAKE) on spell-corrected file. All keywords per file are stored in one data frame for comparison, and exported to
.xlsxformat
** (where X is some duration that does not overload your computer or crash your IDE)
By default,
- results are stored in
~/v2clntxt_transcriptions - metadata in
~/v2clntxt_transc_metadata
(where ~ is path entered by user)
Installation
Quickstart (aka: how to get the script running)
Essentially, clone the repo, and run python vid2cleantxt/transcribe.py --input-dir "filepath-to-the-inputs"
- You can get details on all the command line args by running
python vid2cleantxt/transcribe.py --help.
Note: the first time the code runs on your machine, it will download the pretrained transformers models which include wav2vec2 and a scibert model for spell correction. After the first run, it will be cached locally, and you will not need to sit through that again.
git clone https://github.com/pszemraj/vid2cleantxt.git- add
--depth=1to above to clone just the current code & objects and will be faster
- add
cd vid2cleantxt/pip install -r requirements.txtpython vid2cleantxt/transcribe.py --input-dir "examples/TEST_singlefile"- in this example*, all video and audio files in the repo example "example_JFK_speech/TEST_singlefile" would be transcribed.
- download the video with
python examples/TEST_singlefile/dl_src_video.py
- if you are new, you can clone with github desktop
- if neither option works for you, check out the Colab notebooks distributed with this repo.
* the example videos need to be downloaded with the scripts in the relevant dirs, such as
python examples/TEST_singlefile/dl_src_video.py
Use as package
pip install .spacy download en_core_web_smimport vid2cleantxtvid2cleantxt.transcribe.transcribe_dir("examples/TEST_singlefile")
Notebooks on Colab
Notebook versions are available on Google Colab, because they offer free GPUs which makes vid2cleantxt much faster. If you want a notebook to run locally for whatever reason, in Colab you can download as .ipynb, but you may need to make some small changes (some directories, packages, etc. are specific to Colab's structure) - the same goes for the colab notebooks in this repo.
Links to Colab Scripts:
- Single-File Version (Implements GPU)
- Link here, updated on 2022-02-24.
- This notebook downloads a video of JFK's "Moon Speech" (originally downloaded from C-SPAN) and transcribes it, printing and/or optionally downloading the output. No authentication etc required.
- This is the recommended link for seeing how this pipeline works. Only work involved is running all cells.
- Multi-File Version (Implements GPU)
- Link here, updated on 2022-02-24. The example here is MIT OpenCourseWare Lecture Videos (see
examples/for citations). - This notebook connects to the user's google drive to convert a whole folder of videos. The input can be either Colab or URL to a
.zipfile of media. Outputs are stored in the user's Google Drive and optionally downloaded. - NOTE: this notebook does require Drive authorization. Google's instructions for this have improved as of late, and it will pop up a window for confirmation etc.
- Link here, updated on 2022-02-24. The example here is MIT OpenCourseWare Lecture Videos (see
If you are new to Colab, it is probably best to read the Colab Quickstart first and the below, for info on how to do file I/O etc.
- Google's FAQ
- Medium Article on Colab + Large Datasets
- Google's Demo Notebook on I/O
- A better Colab Experience
How long does this take to run?
On Google Colab with a 16 gb GPU (should be available to free Colab accounts): approximately 8 minutes to transcribe ~ 90 minutes of audio. CUDA is supported - if you have an NVIDIA graphics card, you may see runtimes closer to that estimate on your local machine.
On my machine (CPU only due to Windows + AMD GPU) it takes approximately 30-70% of the total duration of input video files. You can also take a look at the "console printout" text files in example_JFK_speech/TEST_singlefile.
- with model = "facebook/wav2vec2-base-960h" (default) approx 30% of original video RT
- with model = "facebook/wav2vec2-large-960h-lv60-self" approx 70% of original video RT
Specs:
Processor Intel(R) Core(TM) i7-8665U CPU @ 1.90GHz
Speed 4.8 GHz
Number of Cores 8
Memory RAM 32 GB
Video Card #1 Intel(R) UHD Graphics 620
Dedicated Memory 128 MB
Total Memory 16 GB
Video Card #2 AMD Radeon Pro WX3200 Graphics
Dedicated Memory 4.0 GB
Total Memory 20 GB
Operating System Windows 10 64-bit
NOTE: that the default model is facebook/wav2vec2-base-960h. This is a pre-trained model that is trained on the librispeech corpus. If you want to use a different model, you can pass the
--modelargument (for example--model "facebook/wav2vec2-large-960h-lv60-self"). The model is downloaded from huggingface.co's servers if it does not exist locally. The large model is more accurate, but is also slower to run. I do not have stats on differences in WER, but facebook may have some posted.
Application
Now I have a bunch of long text files. How are these useful?
short answer: noam_chomsky.jpeg
more comprehensive answer:
Text data can be visualized, summarized, or reduced in many ways with natural language processing and machine learning algorithms. For example, you can use TextHero or ScatterText to compare audio transcriptions with written documents, or use topic models or statistical models to extract key topics from each file. Comparing text data in this way can help you understand how similar they are, or identify key differences.
Visualization and Analysis
- TextHero - cleans text, allows for visualization / clustering (k-means) / dimensionality reduction (PCA, TSNE)
- Use case here: I want to see how this speaker's speeches differ from each other. Which are "the most related"?
- Scattertext - allows for comparisons of one corpus of text to another via various methods and visualizes them.
- Use case here: I want to see how the speeches by this speaker compare to speeches by speaker B in terms of topics, word frequency… so on
Some examples from my own usage are illustrated below from both packages.
Text Extraction / Manipulation
- Textract
- Textacy
- YAKE
- A brief YAKE analysis is completed in this pipeline after transcribing the audio.
Text Summarization
Several options are available on the HuggingFace website. In an effort to create a better, more general model for summarization, I have fine-tuned this model on a book summary dataset which I find provides the best results for "lecture-esque" video conversion. I wrote a little bit about this and compare it to other models WARNING: satire/sarcasm inside here.
I personally use several similar methods in combination with the transcription script, however it isn't in a place to be officially posted yet. It will be posted to a public repo on this account when ready. For now, you can check out this Colab notebook using the same example text that is output when the JFK speeches are transcribed.
TextHero example use case
Clustering vectorized text files into k-means groups:
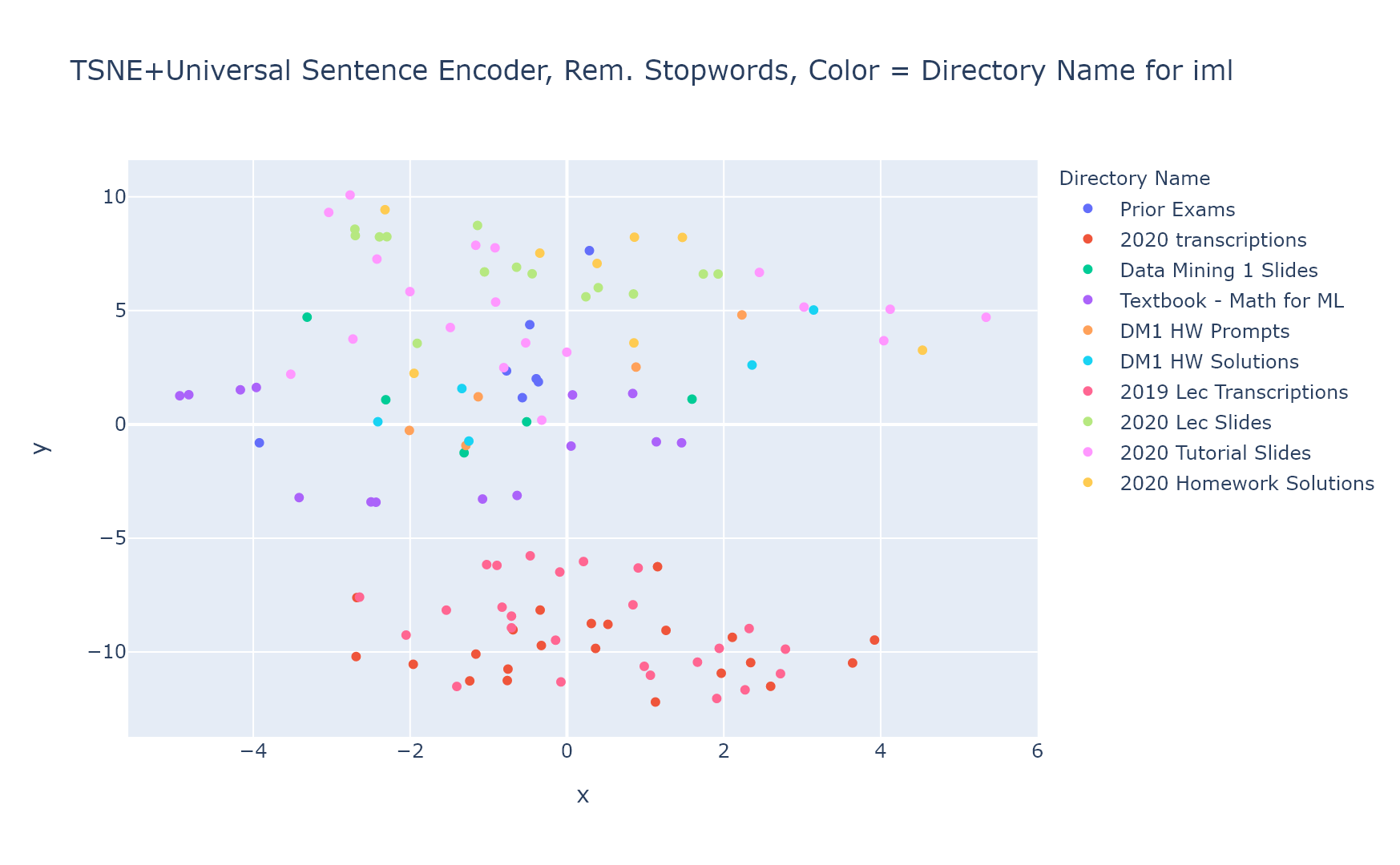
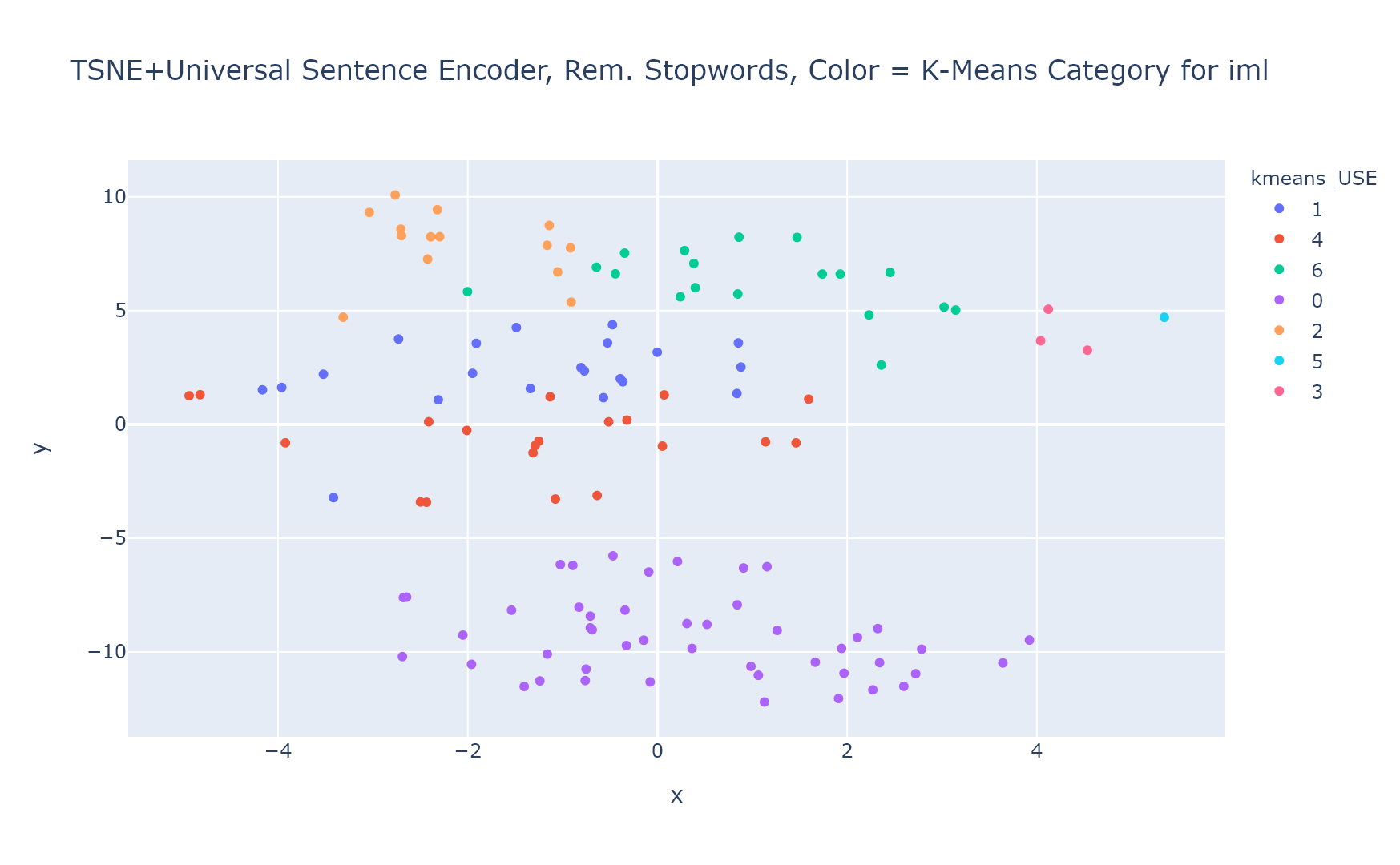
ScatterText example use case
Comparing frequency of terms in one body of text vs. another

Design Choices & Troubleshooting
What python package dependencies does this repo have?
Upon cloning the repo, run the command pip install -r requirements.txt in a terminal opened in the project directory. Requirements (upd. Dec 23, 2021) are:
librosa~=0.8.1
wordninja~=2.0.0
psutil~=5.8.0
natsort~=7.1.1
pandas~=1.3.0
moviepy~=1.0.3
transformers~=4.15.0
numpy~=1.21.0
pydub~=0.24.1
symspellpy~=6.7.0
joblib~=1.0.1
torch~=1.9.0
tqdm~=4.43.0
plotly~=4.14.3
yake~=0.4.8
pysbd~=0.3.4
clean-text
GPUtil~=1.4.0
humanize~=3.13.1
neuspell~=1.0.0
openpyxl >=3
unidecode~=1.3.2
spacy>=3.0.0,<4.0.0
https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0.tar.gz#egg=en_core_web_sm
- Note: the github link in the reqs above downloads the spaCy model
en_core_web_smas part of the setup/installation process so you don't have to manually typepython -m spacy download en_core_web_sminto the terminal to be able to run the code. More on this is described on spaCy's website here
If you encounter warnings/errors that mention ffmpeg, please download the latest version of FFMPEG from their website here and ensure it is added to PATH.
My computer crashes once it starts running the wav2vec2 model
Try passing a lower --chunk-len <INT> when calling vid2cleantxt/transcribe.py. Until you get to really small intervals (say < 8 seconds) each audio chunk can be treated as approximately independent as they are different sentences.
The transcription is not perfect, and therefore I am mad
Perfect transcripts are not always possible, especially when the audio is not clean. For example, the audio is recorded with a microphone that is not always perfectly tuned to the speaker can cause the model to have issues. Additionally, the default models are not trained on specific speakers and therefore the model will not be able to recognize the speaker / their accent.
Despite the small amount of errors, the model is still able to recognize the speaker and their accent and capture a vast majority of the text. This should still save you a lot of time and effort.
How can I improve the performance of the model from a word-error-rate perspective?
if you change the default model by passing --model "facebook/wav2vec2-large-960h-lv60-self"from the default facebook/wav2vec2-base-960h the model will be considerably more accurate (see FAIR repo). In fact, any wav2vec2 or wavLM model from the huggingface hub can be used, just pass the model ID string with --model when running the script.
You can also train your own model, but that requires that you already have a transcription of that person's speech already. As you may find, manual transcription is a bit of a pain and therefore transcripts are rarely provided - hence this repo. If interested see this notebook
Why use wav2vec2 instead of SpeechRecognition or other transcription methods?
Google's SpeechRecognition (with the free API) requires optimization of three unknown parameters*, which in my experience can vary widely among english as a second language speakers. With wav2vec2, the base model is pretrained, so a 'decent transcription' can be made without having to spend a bunch of time testing and optimizing parameters.
Also, because it's an API you can't train it even if you wanted to, you have to be online for functionally most of the script runtime, and then of course you have privacy concerns with sending data out of your machine.
* these statements reflect the assessment completed around project inception about early 2021.
Errors
- _pickle.UnpicklingError: invalid load key, '<' --> Neuspell model was not downloaded correctly. Try re-downloading it.
- manually open /Users/yourusername/.local/share/virtualenvs/vid2cleantxt-vMRD7uCV/lib/python3.8/site-packages/neuspell/../data
- download the model from https://github.com/neuspell/neuspell#Download-Checkpoints
- import neuspell
- neuspell.seq_modeling.downloads.download_pretrained_model("scrnnelmo-probwordnoise")
Examples
- two examples are evailable in the
examples/directory. One example is a single video (another speech) and the other is multiple videos (MIT OpenCourseWare). Citations are in the respective folders. - Note that the videos first need to be downloaded video the respective scripts in each folder first, i.e. run:
python examples/TEST_singlefile/dl_src_video.py
Future Work, Collaboration, & Citations
Project Updates
A rough timeline of what has been going on in the repo:
- Feb 2022 - Add backup functions for spell correction in case of NeuSpell failure (which at the time of writing is a known issue).
- Jan 2022 - add huBERT support, abstract the boilerplate out of Colab Notebooks. Starting work on the PDF generation w/ results.
- Dec 2021 - greatly improved runtime of the script, and added more features (command line, docstring, etc.)
- Sept-Oct 2021: Fixing bugs, formatting code.
- July 12, 2021 - sync work from Colab notebooks: add CUDA support for pytorch in the
.pyversions, added Neuspell as a spell checker. General organization and formatting improvements. - July 8, 2021 - python scripts cleaned and updated.
- April - June: Work done mostly on Colab improving saving, grammar correction, etc.
- March 2021: public repository added
Future Work
-
syncing improvements currently in the existing Google Colab notebooks (links) above such as NeuSpellthis will include support for CUDA automatically when running the code (currently just on Colab)
-
clean up the code, add more features, and make it more robust. -
publish as a python package to streamline process / reduce overhead, making it easier to use + adopt.
-
add script to convert
.txtfiles to a clean PDF report, example here -
add summarization script / module
-
convert groups of functions to a class object. re-organize code to make it easier to read and understand.
I've found x repo / script / concept that I think you should incorporate or collaborate with the author
Send me a message / start a discussion! Always looking to improve. Or create an issue, that works too.
Citations
wav2vec2 (fairseq)
Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of NAACL-HLT 2019: Demonstrations, 2019.
- repo link
HuBERT (fairseq)
@article{Hsu2021,
author = {Wei Ning Hsu and Benjamin Bolte and Yao Hung Hubert Tsai and Kushal Lakhotia and Ruslan Salakhutdinov and Abdelrahman Mohamed},
doi = {10.1109/TASLP.2021.3122291},
issn = {23299304},
journal = {IEEE/ACM Transactions on Audio Speech and Language Processing},
keywords = {BERT,Self-supervised learning},
month = {6},
pages = {3451-3460},
publisher = {Institute of Electrical and Electronics Engineers Inc.},
title = {HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units},
volume = {29},
url = {<https://arxiv.org/abs/2106.07447v1>},
year = {2021},
}
MoviePy
- link to repo as no citation info given
symspellpy / symspell
- repo link
- copyright:
Copyright (c) 2020 Wolf Garbe Version: 6.7 Author: Wolf Garbe mailto:wolf.garbe@seekstorm.com Maintainer: Wolf Garbe mailto:wolf.garbe@seekstorm.com URL: https://github.com/wolfgarbe/symspell Description: https://medium.com/@wolfgarbe/1000x-faster-spelling-correction-algorithm-2012-8701fcd87a5f
MIT License
Copyright (c) 2020 Wolf Garbe
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
YAKE (yet another keyword extractor)
- repo link
- relevant citations:
In-depth journal paper at Information Sciences Journal
Campos, R., Mangaravite, V., Pasquali, A., Jatowt, A., Jorge, A., Nunes, C. and Jatowt, A. (2020). YAKE! Keyword Extraction from Single Documents using Multiple Local Features. In Information Sciences Journal. Elsevier, Vol 509, pp 257-289. pdf
ECIR'18 Best Short Paper
Campos R., Mangaravite V., Pasquali A., Jorge A.M., Nunes C., and Jatowt A. (2018). A Text Feature Based Automatic Keyword Extraction Method for Single Documents. In: Pasi G., Piwowarski B., Azzopardi L., Hanbury A. (eds). Advances in Information Retrieval. ECIR 2018 (Grenoble, France. March 26 – 29). Lecture Notes in Computer Science, vol 10772, pp. 684 - 691. pdf
Campos R., Mangaravite V., Pasquali A., Jorge A.M., Nunes C., and Jatowt A. (2018). YAKE! Collection-independent Automatic Keyword Extractor. In: Pasi G., Piwowarski B., Azzopardi L., Hanbury A. (eds). Advances in Information Retrieval. ECIR 2018 (Grenoble, France. March 26 – 29). Lecture Notes in Computer Science, vol 10772, pp. 806 - 810. pdf
Video Citations
-
President Kennedy’s 1962 Speech on the US Space Program | C-SPAN Classroom. (n.d.). Retrieved January 28, 2022, from https://www.c-span.org/classroom/document/?7986
-
Note: example videos are cited in respective
Examples/directories
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vid2cleantxt-0.0.2.tar.gz.
File metadata
- Download URL: vid2cleantxt-0.0.2.tar.gz
- Upload date:
- Size: 41.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.43.0 importlib-metadata/4.11.1 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
89b5923ddc726bc651c25658269dbb4cb4d6841b11fe5ef9138596fc8a935022
|
|
| MD5 |
8416f1a13e011eece251eefc1e397a06
|
|
| BLAKE2b-256 |
9e9424ad70e069c7da07affa9e39dc59f9c3dd1f6bdbf01ffc0674d19f255a27
|
File details
Details for the file vid2cleantxt-0.0.2-py3-none-any.whl.
File metadata
- Download URL: vid2cleantxt-0.0.2-py3-none-any.whl
- Upload date:
- Size: 48.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.43.0 importlib-metadata/4.11.1 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d25c416e392e5b1c64d01df55f6c3931439c21e3fa51f86b30ad68ca27ac84ca
|
|
| MD5 |
42faad575ee4bb90ed0e3d7778e0ef71
|
|
| BLAKE2b-256 |
9faab56d733ca0430b0fe67937cff0d04084392737ebe0419a3a05c8d676bc2b
|







