Automated local WhatsApp voice note transcriber
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
🎙️ WhatsApp Auto-Transcriber
A lightning-fast, privacy-focused tool that automatically transcribes incoming WhatsApp voice notes on macOS and Windows.
Why? WhatsApp's native transcription is often unavailable or slow. This tool provides a superior, 100% local alternative that works instantly the moment a voice note is downloaded, leveraging your hardware (GPU/NPU) for maximum speed.
[!IMPORTANT] Desktop Only: This tool requires the official WhatsApp Desktop App (Store Version). It monitors the internal file system for new
.opusfiles.






✨ Features
-
⚡️ Hardware Accelerated:
- macOS: Native Metal Performance Shaders (MPS) for M1/M2/M3/M4 chips.
- Windows: Native NVIDIA CUDA support for GeForce RTX cards.
-
📂 Intelligent Monitoring: Uses a threaded
Watchdogobserver to detect voice notes instantly without locking your system. -
🏥 System Health Check: Includes a utility to analyze your RAM/VRAM and suggest the optimal AI model size to prevent crashes.
-
Smart Maintenance: Automatically cleans up AI models that haven't been used in 3 days (configurable) to save disk space.
-
Startup Backfill: Scans for missed voice notes from the last hour upon launch to ensure nothing is lost.
-
📋 Auto-Clipboard & Logging:
- Text is copied to clipboard (
Cmd+V/Ctrl+V). - Transcripts are saved to daily logs (e.g.,
2026-01-27_daily.log).
- Text is copied to clipboard (
🚀 Prerequisites
1. Install FFmpeg
Whisper relies on FFmpeg for audio processing.
- macOS:
brew install ffmpeg - Windows:
choco install ffmpeg(or download binaries from ffmpeg.org and add to PATH).
2. Python 3.10+
Ensure you have a modern Python version installed. You can download it from python.org.
🛠️ Installation
From PyPI (recommended)
Install the latest release with pip (use a venv if you like):
pip install wa-transcriber
Or install as an isolated CLI with uv:
uv tool install wa-transcriber
The package is published on PyPI. Dependencies include PyTorch and Whisper, so the first install may take a while and use significant disk space.
From source
Clone the repository and install from the checkout (for development or unreleased changes). Use a venv if you prefer.
git clone https://github.com/jpxoi/wa-transcriber.git
cd wa-transcriber
pip install .
For an editable install while hacking on the code: pip install -e .
If you use uv in the repo:
git clone https://github.com/jpxoi/wa-transcriber.git
cd wa-transcriber
uv sync
Run CLI commands with uv run wa-transcriber ... (for example uv run wa-transcriber health).
For day-to-day use of a stable build, prefer From PyPI above.
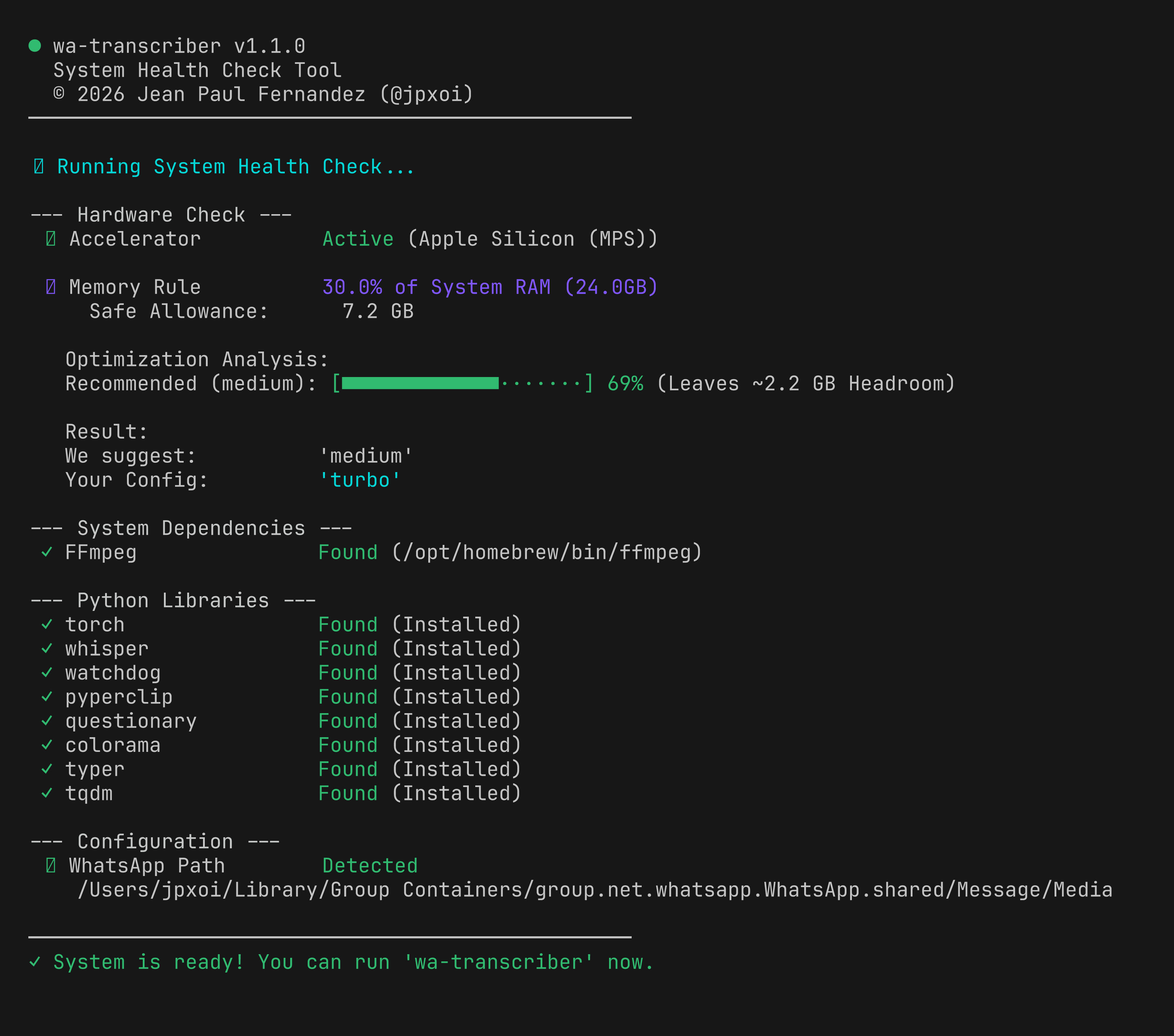
Run the Health Check (Crucial)
Before running the main program, run the included health check tool. This script analyzes your System RAM (CPU/MPS) or VRAM (NVIDIA) and calculates exactly which Whisper model your computer can handle safely.
wa-transcriber health
- ✅ Verifies FFmpeg installation.
- ✅ Detects Hardware Acceleration (CUDA vs MPS vs CPU).
- ✅ Calculates memory overhead and suggests the best
MODEL_SIZE.
⚙️ Configuration
Run the interactive setup wizard to configure the application:
wa-transcriber setup
This will guide you through:
- Model Selection: choosing the appropriate Whisper model size.
- Language: setting a preferred language or using auto-detection.
- WhatsApp Path: automatically detecting or manually specifying the WhatsApp Media folder.
- Hardware Limits: configuring RAM and VRAM usage limits.
To view your current configuration at any time, run:
wa-transcriber config
Configuration is stored in config.json in ~/.wa-transcriber/.
Model Selection Reference
The setup wizard will suggest a model based on your hardware, but you can choose any of the following:
| Model | VRAM/RAM Req | Speed | Accuracy | Best For |
|---|---|---|---|---|
tiny |
~1 GB | ⚡️ Instant | Low | Older laptops |
base |
~1 GB | 🚀 Very Fast | Decent | Quick snippets |
small |
~2 GB | 🏃 Fast | Good | General usage |
medium |
~5 GB | ⚖️ Balanced | Great | Professional use |
turbo |
~6 GB | 🏎️ Optimized | Excellent | M1/M2/M3 & RTX 3060+ |
large-v3 |
~10 GB | 🐌 Slow | Perfect | Heavy accents / Noisy audio |
Advanced Settings
The following settings can be fine-tuned via the setup wizard or by manually editing config.json:
- Scan Lookback: Number of hours to check for missed files on startup.
- Model Cleanup: Automatically delete models unused for a set number of days.
- Memory Limits: Adjust how aggressively the script uses System RAM or GPU VRAM.
🏃 Usage
Run the main script. It will initialize the model and start watching the folder.
wa-transcriber
Workflow:
- Script loads (shows a progress bar for model loading).
- Startup Scan: Checks for missed files from the last hour.
- "👀 Watching Folder" message appears.
- Receive a voice note in WhatsApp Desktop.
- Instant Result:
- Console shows:
⚡️ [WORKING] Processing: audio_file.opus - Then:
✅ [DONE] Transcript: Hello world... - Clipboard: Updated automatically.
🛠️ CLI Reference
| Command | Description |
|---|---|
wa-transcriber |
Starts the main transcription service. |
wa-transcriber setup |
Runs the interactive configuration wizard. |
wa-transcriber health |
Runs system diagnostics and hardware checks. |
wa-transcriber config |
Displays the current configuration. |
wa-transcriber reset |
Resets the application by removing all user data and configuration. |
wa-transcriber logs audio |
Shows the last 50 lines of transcribed audio logs. |
wa-transcriber logs app |
Shows the last 50 lines of application logs. |
❓ Troubleshooting
- "Clipboard unavailable": On Linux, you may need
xcliporxsel. On Windows/Mac, this usually works out of the box. - "CUDA out of memory": Run
wa-transcriber healthand switch to a smaller model (e.g., fromlargetomedium). - Script doesn't trigger: Ensure "Media Auto-Download" is ON in WhatsApp settings, or manually click the download arrow on the voice note.
🤝 Contributing
Pull requests are welcome. For major changes, please open an issue first.
📄 License
© 2026 Jean Paul Fernandez. Licensed under GPLv3.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file wa_transcriber-1.3.5.tar.gz.
File metadata
- Download URL: wa_transcriber-1.3.5.tar.gz
- Upload date:
- Size: 51.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
69b942df2aa0b84c4c928d39ee775c3d60487c48491dd6a882e2e0e46c1ab6a5
|
|
| MD5 |
e0b78024492b9b7b6e2874aec12e25f2
|
|
| BLAKE2b-256 |
37ab7f13af0ea666c95034e898bec6b7ceb5503cccc9072d778a76cfbbce9f96
|
Provenance
The following attestation bundles were made for wa_transcriber-1.3.5.tar.gz:
Publisher:
publish.yml on jpxoi/wa-transcriber
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
wa_transcriber-1.3.5.tar.gz -
Subject digest:
69b942df2aa0b84c4c928d39ee775c3d60487c48491dd6a882e2e0e46c1ab6a5 - Sigstore transparency entry: 1258408423
- Sigstore integration time:
-
Permalink:
jpxoi/wa-transcriber@5b9e93c5e760d55d523ccb174129fd088add7687 -
Branch / Tag:
refs/tags/v1.3.5 - Owner: https://github.com/jpxoi
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@5b9e93c5e760d55d523ccb174129fd088add7687 -
Trigger Event:
push
-
Statement type:
File details
Details for the file wa_transcriber-1.3.5-py3-none-any.whl.
File metadata
- Download URL: wa_transcriber-1.3.5-py3-none-any.whl
- Upload date:
- Size: 43.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6eda75d3a4f1055bd2cfe6dfd2511307ad8be21216bef128e264edc18f21955f
|
|
| MD5 |
d3d9cd4c897ca1d4d82bdc396444eb9f
|
|
| BLAKE2b-256 |
f178cb9511cc40eee442f0f01359558d40b5c7c534cd7c38d209dbc2efaca662
|
Provenance
The following attestation bundles were made for wa_transcriber-1.3.5-py3-none-any.whl:
Publisher:
publish.yml on jpxoi/wa-transcriber
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
wa_transcriber-1.3.5-py3-none-any.whl -
Subject digest:
6eda75d3a4f1055bd2cfe6dfd2511307ad8be21216bef128e264edc18f21955f - Sigstore transparency entry: 1258408504
- Sigstore integration time:
-
Permalink:
jpxoi/wa-transcriber@5b9e93c5e760d55d523ccb174129fd088add7687 -
Branch / Tag:
refs/tags/v1.3.5 - Owner: https://github.com/jpxoi
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@5b9e93c5e760d55d523ccb174129fd088add7687 -
Trigger Event:
push
-
Statement type:







