RL4CO: an Extensive Reinforcement Learning for Combinatorial Optimization Benchmark
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers



Project description












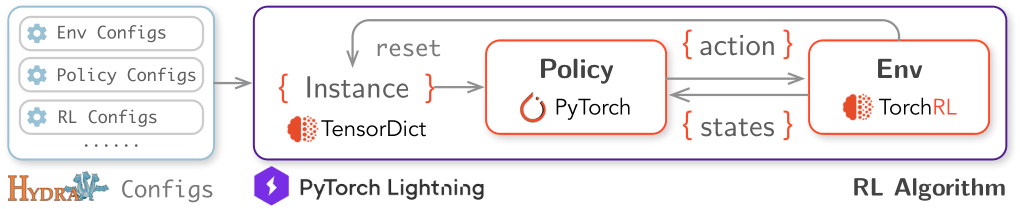
An extensive Reinforcement Learning (RL) for Combinatorial Optimization (CO) benchmark. Our goal is to provide a unified framework for RL-based CO algorithms, and to facilitate reproducible research in this field, decoupling the science from the engineering.
RL4CO is built upon:
- TorchRL: official PyTorch framework for RL algorithms and vectorized environments on GPUs
- TensorDict: a library to easily handle heterogeneous data such as states, actions and rewards
- PyTorch Lightning: a lightweight PyTorch wrapper for high-performance AI research
- Hydra: a framework for elegantly configuring complex applications
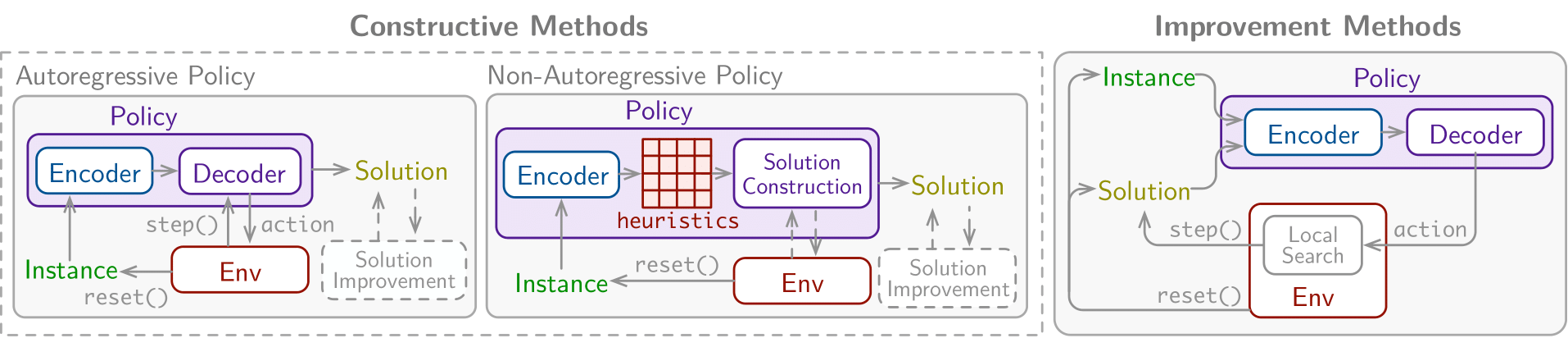
We offer flexible and efficient implementations of the following policies:
- Constructive: learn to construct a solution from scratch
- Autoregressive (AR): construct solutions one step at a time via a decoder
- NonAutoregressive (NAR): learn to predict a heuristic, such as a heatmap, to then construct a solution
- Improvement: learn to improve a pre-existing solution
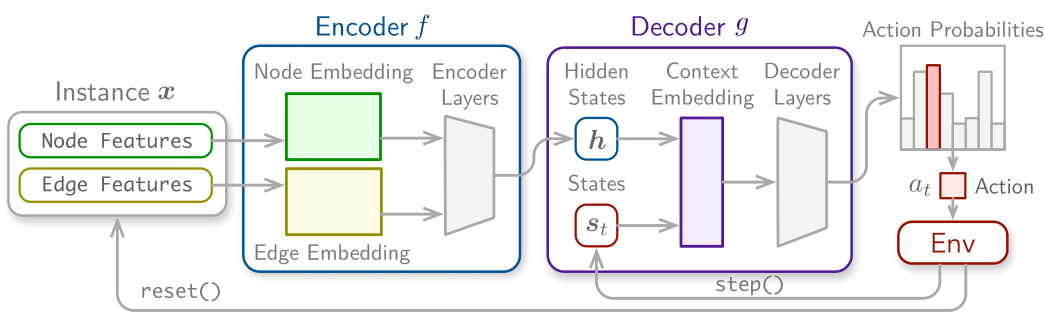
We provide several utilities and modularization. For example, we modularize reusable components such as environment embeddings that can easily be swapped to solve new problems.
Getting started
RL4CO is now available for installation on pip!
pip install rl4co
To get started, we recommend checking out our quickstart notebook or the minimalistic example below.
Install from source
This command installs the bleeding edge main version, useful for staying up-to-date with the latest developments - for instance, if a bug has been fixed since the last official release but a new release hasn’t been rolled out yet:
pip install -U git+https://github.com/ai4co/rl4co.git
Local install and development
We recommend local development with the blazing-fast uv package manager, for instance:
git clone https://github.com/ai4co/rl4co && cd rl4co
uv sync --all-extras
source .venv/bin/activate
This will create a new virtual environment in .venv/ and install all dependencies.
Usage
Train model with default configuration (AM on TSP environment):
python run.py
[!TIP] You may check out this notebook to get started with Hydra!
Change experiment settings
Train model with chosen experiment configuration from configs/experiment/
python run.py experiment=routing/am env=tsp env.num_loc=50 model.optimizer_kwargs.lr=2e-4
Here you may change the environment, e.g. with env=cvrp by command line or by modifying the corresponding experiment e.g. configs/experiment/routing/am.yaml.
Disable logging
python run.py experiment=routing/am logger=none '~callbacks.learning_rate_monitor'
Note that ~ is used to disable a callback that would need a logger.
Create a sweep over hyperparameters (-m for multirun)
python run.py -m experiment=routing/am model.optimizer.lr=1e-3,1e-4,1e-5
Minimalistic Example
Here is a minimalistic example training the Attention Model with greedy rollout baseline on TSP in less than 30 lines of code:
from rl4co.envs.routing import TSPEnv, TSPGenerator
from rl4co.models import AttentionModelPolicy, POMO
from rl4co.utils import RL4COTrainer
# Instantiate generator and environment
generator = TSPGenerator(num_loc=50, loc_distribution="uniform")
env = TSPEnv(generator)
# Create policy and RL model
policy = AttentionModelPolicy(env_name=env.name, num_encoder_layers=6)
model = POMO(env, policy, batch_size=64, optimizer_kwargs={"lr": 1e-4})
# Instantiate Trainer and fit
trainer = RL4COTrainer(max_epochs=10, accelerator="gpu", precision="16-mixed")
trainer.fit(model)
Other examples can be found on our documentation!
Testing
Run tests with pytest from the root directory:
pytest tests
Known Bugs
You may check out the issues and discussions. We will also periodically post updates on the FAQ section.
Contributing
Have a suggestion, request, or found a bug? Feel free to open an issue or submit a pull request. If you would like to contribute, please check out our contribution guidelines here. We welcome and look forward to all contributions to RL4CO!
We are also on Slack if you have any questions or would like to discuss RL4CO with us. We are open to collaborations and would love to hear from you 🚀
Contributors

Citation
If you find RL4CO valuable for your research or applied projects:
@inproceedings{berto2025rl4co,
title={{RL4CO: an Extensive Reinforcement Learning for Combinatorial Optimization Benchmark}},
author={Federico Berto and Chuanbo Hua and Junyoung Park and Laurin Luttmann and Yining Ma and Fanchen Bu and Jiarui Wang and Haoran Ye and Minsu Kim and Sanghyeok Choi and Nayeli Gast Zepeda and Andr\'e Hottung and Jianan Zhou and Jieyi Bi and Yu Hu and Fei Liu and Hyeonah Kim and Jiwoo Son and Haeyeon Kim and Davide Angioni and Wouter Kool and Zhiguang Cao and Jie Zhang and Kijung Shin and Cathy Wu and Sungsoo Ahn and Guojie Song and Changhyun Kwon and Lin Xie and Jinkyoo Park},
booktitle={Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
year={2025},
url={https://github.com/ai4co/rl4co}
}
Note that a previous version of RL4CO was also accepted as an oral presentation at the NeurIPS 2023 GLFrontiers Workshop. Since then, the library has greatly evolved and improved!
Join us
We invite you to join our AI4CO community, an open research group in Artificial Intelligence (AI) for Combinatorial Optimization (CO)!

Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rl4co-0.6.0.tar.gz.
File metadata
- Download URL: rl4co-0.6.0.tar.gz
- Upload date:
- Size: 270.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e2bb3cd7581053c4a34e39baf9c157b4525a19c2bb52cc954d2db90e272788fb
|
|
| MD5 |
f48a81a584b9ccb3fed48d696ff039aa
|
|
| BLAKE2b-256 |
8914fe9e9a766173f73048ab368cb6850d4cbde30958e4187ab86c3bfec0e3dd
|
Provenance
The following attestation bundles were made for rl4co-0.6.0.tar.gz:
Publisher:
publish.yaml on ai4co/rl4co
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
rl4co-0.6.0.tar.gz -
Subject digest:
e2bb3cd7581053c4a34e39baf9c157b4525a19c2bb52cc954d2db90e272788fb - Sigstore transparency entry: 225670138
- Sigstore integration time:
-
Permalink:
ai4co/rl4co@799150e37330201bccbdb994c45eab8c44417e3b -
Branch / Tag:
refs/tags/v0.6.0 - Owner: https://github.com/ai4co
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yaml@799150e37330201bccbdb994c45eab8c44417e3b -
Trigger Event:
release
-
Statement type:
File details
Details for the file rl4co-0.6.0-py3-none-any.whl.
File metadata
- Download URL: rl4co-0.6.0-py3-none-any.whl
- Upload date:
- Size: 401.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6352790e616d418583b92478b2de7582eedee6d661bf576801304360f83ea996
|
|
| MD5 |
0fe671721f7afb015b838e190cf05d88
|
|
| BLAKE2b-256 |
db6e48fbfda61a4f9a898530a58ae5a12be6a8b5ad542fc54beb3028b76a14a5
|
Provenance
The following attestation bundles were made for rl4co-0.6.0-py3-none-any.whl:
Publisher:
publish.yaml on ai4co/rl4co
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
rl4co-0.6.0-py3-none-any.whl -
Subject digest:
6352790e616d418583b92478b2de7582eedee6d661bf576801304360f83ea996 - Sigstore transparency entry: 225670146
- Sigstore integration time:
-
Permalink:
ai4co/rl4co@799150e37330201bccbdb994c45eab8c44417e3b -
Branch / Tag:
refs/tags/v0.6.0 - Owner: https://github.com/ai4co
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yaml@799150e37330201bccbdb994c45eab8c44417e3b -
Trigger Event:
release
-
Statement type:







