CompStats implements an evaluation methodology for statistically analyzing competition results and competition

Project description








Collaborative competitions have gained popularity in the scientific and technological fields. These competitions involve defining tasks, selecting evaluation scores, and devising result verification methods. In the standard scenario, participants receive a training set and are expected to provide a solution for a held-out dataset kept by organizers. An essential challenge for organizers arises when comparing algorithms’ performance, assessing multiple participants, and ranking them. Statistical tools are often used for this purpose; however, traditional statistical methods often fail to capture decisive differences between systems’ performance. CompStats implements an evaluation methodology for statistically analyzing competition results and competition. CompStats offers several advantages, including off-the-shell comparisons with correction mechanisms and the inclusion of confidence intervals.
To illustrate the use of CompStats, the following snippets show an example. The instructions load the necessary libraries, including the one to obtain the problem (e.g., digits), four different classifiers, and the last line is the score used to measure the performance and compare the algorithm.
>>> from sklearn.svm import LinearSVC >>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.datasets import load_digits >>> from sklearn.model_selection import train_test_split >>> from sklearn.base import clone >>> from CompStats.metrics import f1_score
The first step is to load the digits problem and split the dataset into training and validation sets. The second step is to estimate the parameters of a linear Support Vector Machine and predict the validation set’s classes. The predictions are stored in the variable hy.
>>> X, y = load_digits(return_X_y=True) >>> _ = train_test_split(X, y, test_size=0.3) >>> X_train, X_val, y_train, y_val = _ >>> m = LinearSVC().fit(X_train, y_train) >>> hy = m.predict(X_val)
Once the predictions are available, it is time to measure the algorithm’s performance, as seen in the following code. It is essential to note that the API used in sklearn.metrics is followed; the difference is that the function returns an instance with different methods that can be used to estimate different performance statistics and compare algorithms.
>>> score = f1_score(y_val, hy, average='macro') >>> score <Perf(score_func=f1_score, statistic=0.9435, se=0.0099)>
The previous code shows the macro-f1 score and its standard error. The actual performance value is stored in the attributes statistic function, and se
>>> score.statistic, score.se (0.9521479775366307, 0.009717884979482313)
Continuing with the example, let us assume that one wants to test another classifier on the same problem, in this case, a random forest, as can be seen in the following two lines. The second line predicts the validation set and sets it to the analysis.
>>> ens = RandomForestClassifier().fit(X_train, y_train) >>> score(ens.predict(X_val), name='Random Forest') <Perf(score_func=f1_score)> Statistic with its standard error (se) statistic (se) 0.9720 (0.0076) <= Random Forest 0.9521 (0.0097) <= alg-1
Let us incorporate another predictions, now with Naive Bayes classifier, and Histogram Gradient Boosting as seen below.
>>> nb = GaussianNB().fit(X_train, y_train) >>> score(nb.predict(X_val), name='Naive Bayes') >>> hist = HistGradientBoostingClassifier().fit(X_train, y_train) >>> score(hist.predict(X_val), name='Hist. Grad. Boost. Tree') <Perf(score_func=f1_score)> Statistic with its standard error (se) statistic (se) 0.9759 (0.0068) <= Hist. Grad. Boost. Tree 0.9720 (0.0076) <= Random Forest 0.9521 (0.0097) <= alg-1 0.8266 (0.0159) <= Naive Bayes
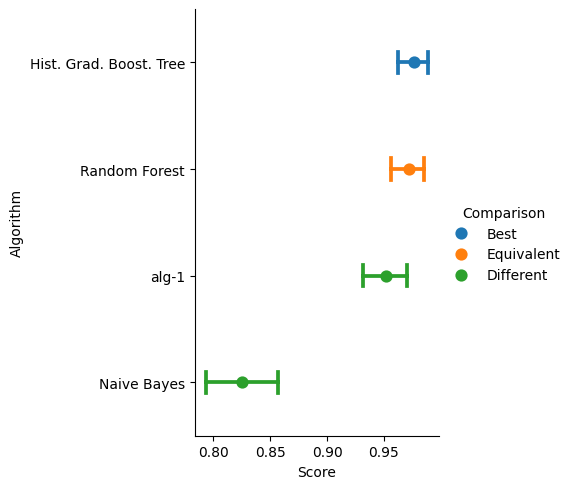
The performance, its confidence interval (5%), and a statistical comparison (5%) between the best performing system with the rest of the algorithms is depicted in the following figure.
>>> score.plot()
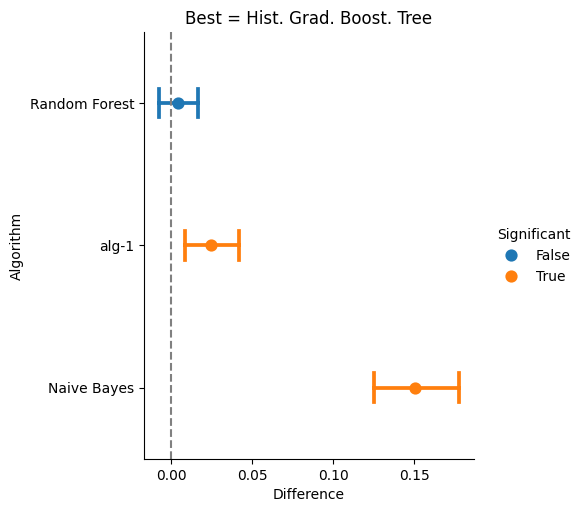
The final step is to compare the performance of the four classifiers, which can be done with the difference method, as seen next.
>>> diff = score.difference() >>> diff <Difference> difference p-values w.r.t Hist. Grad. Boost. Tree 0.0000 <= Naive Bayes 0.0100 <= alg-1 0.3240 <= Random Forest
The class Difference has the plot method that can be used to depict the difference with respect to the best.
>>> diff.plot()
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file compstats-0.1.15.tar.gz.
File metadata
- Download URL: compstats-0.1.15.tar.gz
- Upload date:
- Size: 37.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6cd68f5e8ff794ee48fc5e3a22724babc7ac586c6c2eae9a641ad811de320d68
|
|
| MD5 |
248c610d816949d487409cf466a65d82
|
|
| BLAKE2b-256 |
ac0fdd26d91d72f3ddeea8766a4ee22b7f6db6b67c8e03a0bab31a06841a03da
|
File details
Details for the file compstats-0.1.15-py3-none-any.whl.
File metadata
- Download URL: compstats-0.1.15-py3-none-any.whl
- Upload date:
- Size: 43.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.23
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e9ec266631bc1df430e829db88948568f2373a547345792cbfa464efaacd465d
|
|
| MD5 |
a7436e355136ef41c8f8dedc1e686d2e
|
|
| BLAKE2b-256 |
c1b5a1236a5a6f1d48a62f56c16d59791ba9d5dba4ea4f03cf2dc3ad78d38e05
|







