A LLM quantization package with user-friendly apis. Based on GPTQ algorithm.

Project description
GPTQModel
Production ready LLM model compression/quantization toolkit with accelerated inference support for both cpu/gpu via HF, vLLM, and SGLang.




News
- 11/26/2024 1.3.0 Zero-Day Hymba model support. Removed
tqdmandroguedependency. - 11/24/2024 1.2.3 HF GLM model support. ClearML logging integration. Use
device-smiand replacegputil+psutildepends. Fixed model unit tests. - 11/11/2024 🚀 1.2.1 Meta MobileLLM model support added.
lm-eval[gptqmodel]integration merged upstream. Intel/IPEX cpu inference merged replacing QBits (deprecated). Auto-fix/patch ChatGLM-3/GLM-4 compat with latest transformers. New.load()and.save()api. - 10/29/2024 🚀 1.1.0 IBM Granite model support. Full auto-buildless wheel install from pypi. Reduce max cpu memory usage by >20% during quantization. 100% CI model/feature coverage.
- 10/12/2024 ✨ 1.0.9 Move AutoRound to optional and fix pip install regression in v1.0.8.
- 10/11/2024 ✨ 1.0.8 Add wheel for python 3.12 and cuda 11.8.
- 10/08/2024 ✨ 1.0.7 Fixed marlin (faster) kernel was not auto-selected for some models.
- 09/26/2024 ✨ 1.0.6 Fixed quantized Llama 3.2 vision quantized loader.
- 09/26/2024 ✨ 1.0.5 Partial Llama 3.2 Vision model support (mllama): only text-layer quantization layers are supported for now.
Archived News:
* 09/26/2024 ✨ [1.0.4](https://github.com/ModelCloud/GPTQModel/releases/tag/v1.0.4) Integrated Liger Kernel support for ~1/2 memory reduction on some models during quantization. Added control toggle disable parallel packing. * 09/18/2024 ✨ [1.0.3](https://github.com/ModelCloud/GPTQModel/releases/tag/v1.0.3) Added Microsoft GRIN-MoE and MiniCPM3 support. * 08/16/2024 ✨ [1.0.2](https://github.com/ModelCloud/GPTQModel/releases/tag/v1.0.2) Support Intel/AutoRound v0.3, pre-built whl packages, and PyPI release. * 08/14/2024 ✨ [1.0.0](https://github.com/ModelCloud/GPTQModel/releases/tag/v1.0.0) 40% faster `packing`, Fixed Python 3.9 compat, added `lm_eval` api. * 08/10/2024 🚀 [0.9.11](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.11) Added LG EXAONE 3.0 model support. New `dynamic` per layer/module flexible quantization where each layer/module may have different bits/params. Added proper sharding support to `backend.BITBLAS`. Auto-heal quantization errors due to small damp values. * 07/31/2024 🚀 [0.9.10](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.10) Ported vllm/nm `gptq_marlin` inference kernel with expanded bits (8bits), group_size (64,32), and desc_act support for all GPTQ models with `FORMAT.GPTQ`. Auto calculate auto-round nsamples/seglen parameters based on calibration dataset. Fixed save_quantized() called on pre-quantized models with non-supported backends. HF transformers depend updated to ensure Llama 3.1 fixes are correctly applied to both quant and inference. * 07/25/2024 🚀 [0.9.9](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.9): Added Llama-3.1 support, Gemma2 27B quant inference support via vLLM, auto pad_token normalization, fixed auto-round quant compat for vLLM/SGLang, and more. * 07/13/2024 🚀 [0.9.8](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.8): Run quantized models directly using GPTQModel using fast `vLLM` or `SGLang` backend! Both vLLM and SGLang are optimized for dyanamic batching inference for maximum `TPS` (check usage under examples). Marlin backend also got full end-to-end in/out features padding to enhance current/future model compatibility. * 07/08/2024 🚀 [0.9.7](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.7): InternLM 2.5 model support added. * 07/08/2024 🚀 [0.9.6](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.6): [Intel/AutoRound](https://github.com/intel/auto-round) QUANT_METHOD support added for a potentially higher quality quantization with `lm_head` module quantization support for even more vram reduction: format export to `FORMAT.GPTQ` for max inference compatibility. * 07/05/2024 🚀 [0.9.5](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.5): Cuda kernels have been fully deprecated in favor of Exllama(v1/v2)/Marlin/Triton. * 07/03/2024 🚀 [0.9.4](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.4): HF Transformers integration added and bug fixed Gemma 2 support. * 07/02/2024 🚀 [0.9.3](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.3): Added Gemma 2 support, faster PPL calculations on gpu, and more code/arg refractor. * 06/30/2024 🚀 [0.9.2](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.2): Added auto-padding of model in/out-features for exllama and exllama v2. Fixed quantization of OPT and DeepSeek V2-Lite models. Fixed inference for DeepSeek V2-Lite. * 06/29/2024 🚀 [0.9.1](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.1): With 3 new models (DeepSeek-V2, DeepSeek-V2-Lite, DBRX Converted), BITBLAS new format/kernel, proper batching of calibration dataset resulting > 50% quantization speedup, security hash check of loaded model weights, tons of refractor/usability improvements, bugs fixes and much more. * 06/20/2924 ✨ [0.9.0](https://github.com/ModelCloud/GPTQModel/releases/tag/v0.9.0): Thanks for all the work from ModelCloud team and the opensource ML community for their contributions!Why should you use GPTQModel?
GPTQModel started out as a major refractor (fork) of AutoGTQP but has now morphed into a full-stand-in replacement with cleaner api, up-to-date model support, faster inference, faster quantization, higher quality quants and a pledge that ModelCloud, together with the open-source ML community, will take every effort to bring the library up-to-date with latest advancements and model support.
Why GPTQ specifically and not the dozens of other low-bit quantizers?
Public tests/papers and ModelCloud's internal tests have shown that GPTQ is on-par and/or exceeds other 4bit quantization methods in terms of both quality recovery and production level inference speed in both token latency and rps. GPTQ has currently the optimal blend of quality and inference speed you would want to use in a real-world production system.
Features
- 🚀 Extensive model support for:
IBM Granite,Llama 3.2 Vision,MiniCPM3,GRIN-Moe,Phi 3.5,EXAONE 3.0,InternLM 2.5,Gemma 2,DeepSeek-V2,DeepSeek-V2-Lite,ChatGLM,MiniCPM,Phi-3,Qwen2MoE,DBRX(Converted),Hymba. - ✨ 100% CI coverage for all supported models including quality/ppl regression.
- 🚀 vLLM inference integration for quantized model where format =
FORMAT.GPTQ - 🚀 SGLang inference integration for quantized model where format =
FORMAT.GPTQ - 🚀 Intel/AutoRound QUANT_METHOD support added for a potentially higher quality quantization with
lm_headmodule quantization support for even more vram reduction: format export toFORMAT.GPTQfor max inference compatibility. - 🚀 Intel/IPEX support added for 4 bit quantization/inference on CPU.
- 🚀 BITBLAS format/inference support from Microsoft
- 🚀
Sym=FalseSupport. AutoGPTQ has unusablesym=false. (Re-quant required) - 🚀
lm_headmodule quant inference support for further VRAM reduction. - 🚀 Faster quantization: More than 50% faster for TinyLlama + 4090 with batching and large calibration dataset.
- 🚀 Better quality quants as measured by PPL. (Test config: defaults +
sym=True+FORMAT.GPTQ, TinyLlama) - 🚀 Model weights sharding support
- 🚀 Security: hash check of model weights on load
- 🚀 Over 50% faster PPL calculations (OPT)
- 🚀 Over 40% faster
packingstage in quantization (Llama 3.1 8B)
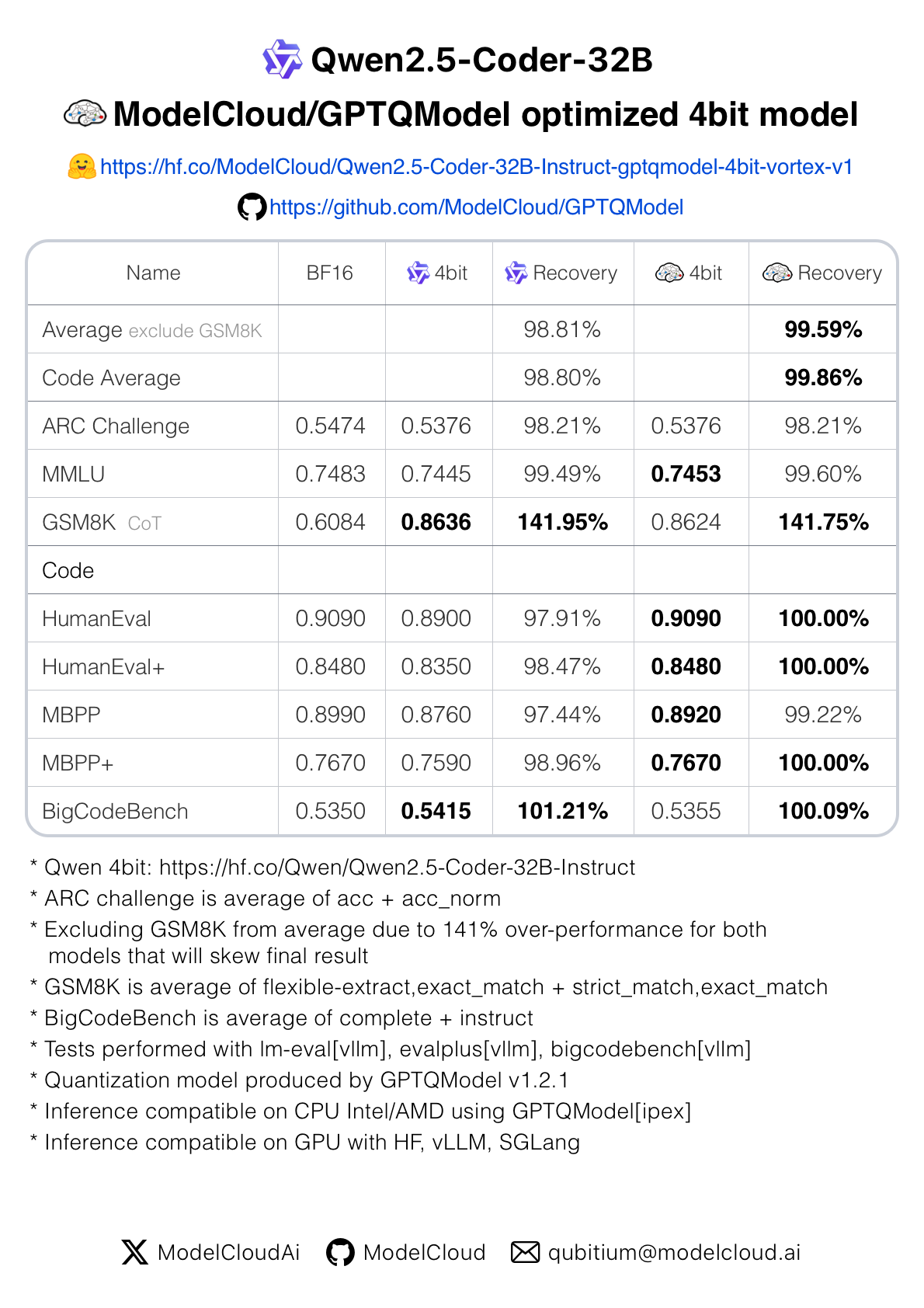
Quality: GPTQModel 4Bit Quantized models can match and sometimes exceed BF16:
🤗 ModelCloud quantized ultra-high recovery vortex-series models on HF
Model Support: 🚀 (Added by GPTQModel)
| Model | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Baichuan | ✅ | Falon | ✅ | Llama 1/2/3 | ✅ | Phi/Phi-3 | 🚀 | |||
| Bloom | ✅ | Gemma 2 | 🚀 | Llama 3.2 Vision | 🚀 | Qwen | ✅ | |||
| ChatGLM | 🚀 | GPTBigCod | ✅ | LongLLaMA | ✅ | Qwen2MoE | 🚀 | |||
| CodeGen | ✅ | GPTNeoX | ✅ | MiniCPM3 | ✅ | RefinedWeb | ✅ | |||
| Cohere | ✅ | GPT-2 | ✅ | Mistral | ✅ | StableLM | ✅ | |||
| DBRX Converted | 🚀 | GPT-J | ✅ | Mixtral | ✅ | StarCoder2 | ✅ | |||
| Deci | ✅ | Granite | 🚀 | MobileLLM | 🚀 | XVERSE | ✅ | |||
| DeepSeek-V2 | 🚀 | GRIN-MoE | 🚀 | MOSS | ✅ | Yi | ✅ | |||
| DeepSeek-V2-Lite | 🚀 | Hymba | 🚀 | MPT | ✅ | |||||
| EXAONE 3.0 | 🚀 | InternLM 1/2.5 | 🚀 | OPT | ✅ |
Platform Requirements
GPTQModel is validated for Linux x86_64 with Nvidia GPUs. Windows WSL2 may work but un-tested.
Install
PIP/UV
# You can install optional modules like autoround, ipex, vllm, sglang, bitblas, and ipex.
# Example: pip install -v --no-build-isolation gptqmodel[vllm,sglang,bitblas,ipex,auto_round]
pip install -v gptqmodel --no-build-isolation
uv pip install -v gptqmodel --no-build-isolation
Install from source
# clone repo
git clone https://github.com/ModelCloud/GPTQModel.git && cd GPTQModel
# pip: compile and install
# You can install optional modules like autoround, ipex, vllm, sglang, bitblas, and ipex.
# Example: pip install -v --no-build-isolation gptqmodel[vllm,sglang,bitblas,ipex,auto_round]
pip install -v . --no-build-isolation
Quantization and Inference
Below is a basic sample using GPTQModel to quantize a llm model and perform post-quantization inference:
from datasets import load_dataset
from transformers import AutoTokenizer
from gptqmodel import GPTQModel, QuantizeConfig
model_id = "meta-llama/Llama-3.2-1B-Instruct"
quant_path = "Llama-3.2-1B-Instruct-gptqmodel-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_id)
calibration_dataset = [
tokenizer(example["text"])
for example in load_dataset(
"allenai/c4",
data_files="en/c4-train.00001-of-01024.json.gz",
split="train"
).select(range(1024))
]
quant_config = QuantizeConfig(bits=4, group_size=128)
model = GPTQModel.load(model_id, quant_config)
model.quantize(calibration_dataset)
model.save(quant_path)
model = GPTQModel.load(quant_path)
result = model.generate(
**tokenizer(
"Uncovering deep insights begins with", return_tensors="pt"
).to(model.device)
)[0]
For more advanced features of model quantization, please reference to this script
How to Add Support for a New Model
Read the gptqmodel/models/llama.py code which explains in detail via comments how the model support is defined. Use it as guide to PR for to new models. Most models follow the same pattern.
Evaluation and Quality Benchmarks
GPTQModel inference is integrated into lm-evaluation-hardness and we highly recommend avoid using PPL and use lm-eval to validate post-quantization model quality.
# currently gptqmodel is merged into lm-eval main but not yet released on pypi
pip install lm-eval[gptqmodel]
Which kernel is used by default?
GPU: Marlin, Exllama v2, Triton kernels in that order for maximum inference performance. Optional Microsoft/BITBLAS kernel can be toggled.CPU: Intel/IPEX kernel
Citation
@misc{gptqmodel,
author = {ModelCloud.ai},
title = {GPTQModel},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/modelcloud/gptqmodel}},
}
@article{frantar-gptq,
title={{GPTQ}: Accurate Post-training Compression for Generative Pretrained Transformers},
author={Elias Frantar and Saleh Ashkboos and Torsten Hoefler and Dan Alistarh},
year={2022},
journal={arXiv preprint arXiv:2210.17323}
}
@article{frantar2024marlin,
title={MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models},
author={Frantar, Elias and Castro, Roberto L and Chen, Jiale and Hoefler, Torsten and Alistarh, Dan},
journal={arXiv preprint arXiv:2408.11743},
year={2024}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file gptqmodel-1.3.0.tar.gz.
File metadata
- Download URL: gptqmodel-1.3.0.tar.gz
- Upload date:
- Size: 179.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bf925b9c5ca9b51583d8791f2810e48b83de4ad2339d3c53b8eb794815f90530
|
|
| MD5 |
95b34bc1905e3e8179bfb51c662ee5ab
|
|
| BLAKE2b-256 |
a32e59cf50045f30f858dc5126fd1a8e809086eb35a2569e25a30d4c01f7f57b
|







