Observability and performance metrics for LLM and RAG systems

Project description
LangMet

Observability and drift intelligence for LLM and RAG systems.
LangMet provides a reusable analytics layer for monitoring operational performance, retrieval quality, and evidence coverage in AI systems.
It separates analytical computation from data access, allowing teams to compute metrics from any telemetry source — SQL databases, log streams, data warehouses, or custom repositories.
Designed for production AI environments.
LangMet separates analytical intelligence from data access so you can compute metrics from any source: SQL databases, log streams, files, or custom repositories.
Why LangMet?
Most LLM metrics pipelines are tightly coupled to infrastructure.
Benefits of LangMet:
- isolates analytics from storage
- provides percentile-based latency monitoring
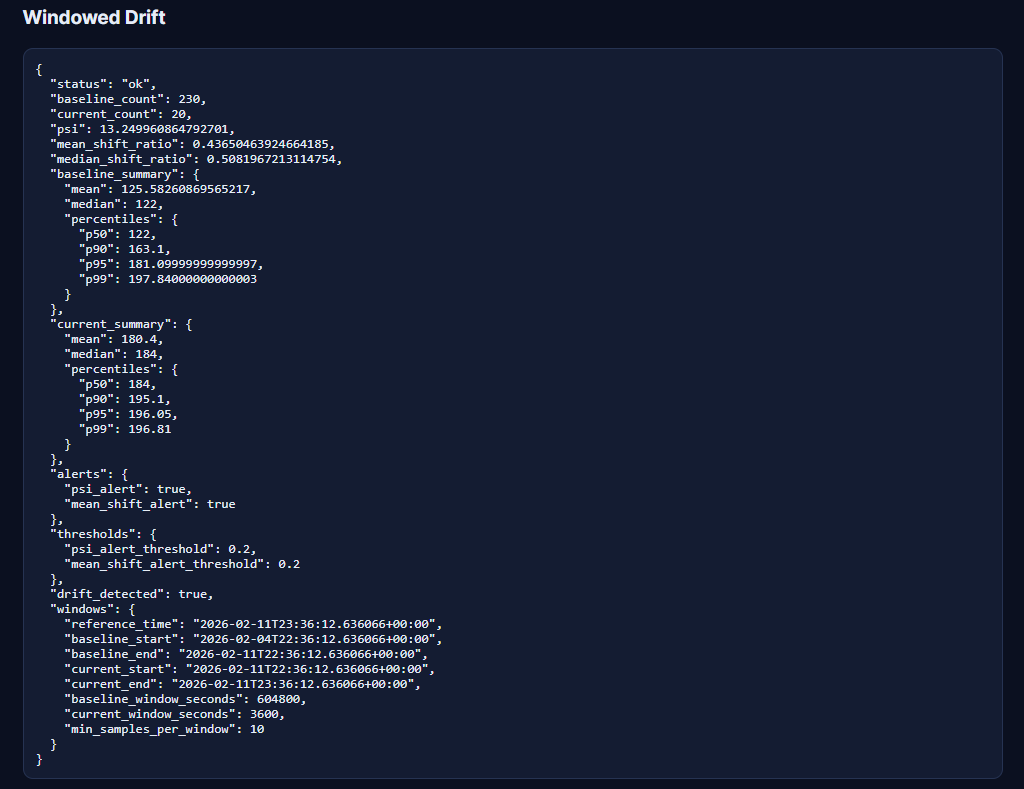
- supports windowed drift detection (short-term vs long-term baselines)
- enables evidence coverage analysis for RAG systems
- works with any data source via repository interfaces
This makes it suitable for:
- production monitoring
- research evaluation
- safety-critical AI systems
- regulated environments
Features
- Pure analytics functions for:
- Operational LLM metrics
- RAG performance metrics
- Citation coverage metrics
- RAGAS evaluation metrics (faithfulness, answer relevancy, context precision, context recall, context relevancy, answer correctness, answer similarity)
- Built-in latency percentiles (
p50,p90,p95,p99) for SLO monitoring - Drift detection for numeric and categorical signals (PSI + TVD based)
- Windowed drift baselines (compare last 1h vs trailing 7d automatically)
- Repository interface (
MetricsRepository) for pluggable data access - SQLAlchemy adapter for existing relational schemas
- Framework-agnostic service layer
[[Install]]
pip install langmet
or with git cli&pip
pip install git+https://github.com/mabrouka-abuhmida/Langmet.gi
With SQLAlchemy adapter support:
pip install "langmet[sqlalchemy]"
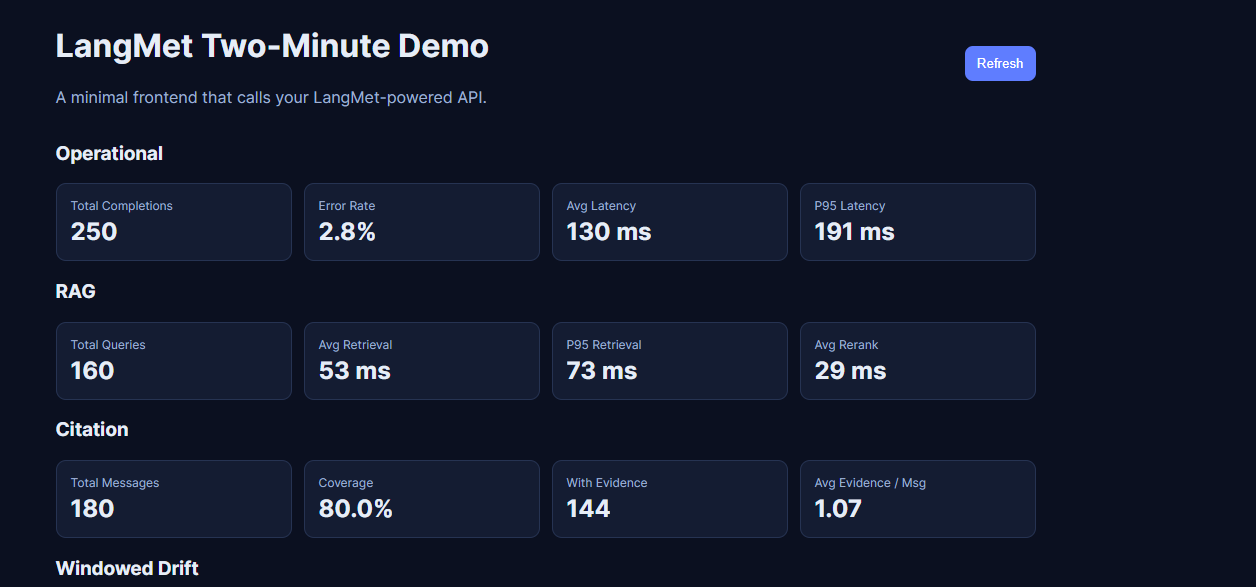
2-Minute Demo
Most engineers want proof it works before reading internals. A runnable backend + frontend demo is included:
examples/two-minute-demo/README.md
Quick run:
python -m pip install -e ".[fastapi]"
python -m pip install uvicorn
uvicorn app:app --app-dir examples/two-minute-demo --reload
Open http://127.0.0.1:8000/.
Example UI Demo
[[Quickstart]] (Pure Functions)
from datetime import datetime
from langmet.models import CompletionEvent
from langmet.analytics import compute_operational_metrics
events = [
CompletionEvent(
provider="openai",
model="gpt-4o-mini",
latency_ms=320,
tokens_total=850,
error_message=None,
created_at=datetime.utcnow(),
)
]
metrics = compute_operational_metrics(events)
print(metrics["overview"]["avg_latency_ms"])
RAGAS quality scoring (per-query, no external dependencies):
from langmet.analytics import (
score_faithfulness,
score_answer_relevancy,
score_context_precision,
score_context_recall,
score_context_relevancy,
score_answer_correctness,
score_answer_similarity,
)
question = "What is the capital of France?"
answer = "Paris is the capital of France."
contexts = ["Paris is the capital and largest city of France."]
ground_truth = "Paris is the capital of France."
faithfulness = score_faithfulness(answer, contexts)
ans_relevancy = score_answer_relevancy(question, answer)
ctx_precision = score_context_precision(contexts, ground_truth)
ctx_recall = score_context_recall(contexts, ground_truth)
ctx_relevancy = score_context_relevancy(question, contexts)
ans_correctness = score_answer_correctness(answer, ground_truth)
ans_similarity = score_answer_similarity(answer, ground_truth)
Aggregate RAGAS scores over many queries:
from datetime import datetime
from langmet.models import RagaEvaluationEvent
from langmet.analytics import compute_raga_metrics
events = [
RagaEvaluationEvent(
query_id="q1",
faithfulness=0.92,
answer_relevancy=0.88,
context_precision=0.80,
context_recall=0.85,
context_relevancy=0.79,
answer_correctness=0.83,
answer_similarity=0.86,
created_at=datetime.utcnow(),
),
# ... more events
]
raga = compute_raga_metrics(events)
print(raga["overview"]["overall_score"])
print(raga["scores"]["faithfulness"])
Drift detection:
from datetime import datetime, timedelta
from langmet.analytics import (
detect_numeric_drift,
detect_categorical_drift,
detect_numeric_drift_windowed,
)
latency_drift = detect_numeric_drift(
baseline_values=[120, 130, 115, 125],
current_values=[210, 220, 205, 215],
)
provider_drift = detect_categorical_drift(
baseline_labels=["openai", "openai", "anthropic"],
current_labels=["anthropic", "anthropic", "openai"],
)
# Automatic window split: last 1h vs trailing 7d.
ref = datetime.utcnow()
observations = [
(ref - timedelta(hours=2), 120.0),
(ref - timedelta(minutes=40), 220.0),
]
windowed_drift = detect_numeric_drift_windowed(
observations=observations,
reference_time=ref,
)
Quickstart (SQL Repository + Service)
from datetime import datetime, timedelta
from langmet.service import AnalyticsService
from langmet.adapters.sqlalchemy_repo import SQLAlchemyMetricsRepository
repo = SQLAlchemyMetricsRepository(db_session)
service = AnalyticsService(repo)
start = datetime.utcnow() - timedelta(days=7)
end = datetime.utcnow()
all_operational = service.get_operational_metrics(start, end)
all_rag = service.get_rag_metrics(start, end)
citation = service.get_citation_coverage(start, end)
Production Integration Guide
Use this path when wiring LangMet to a real service.
-
1) Capture telemetry events in your app
For each request or pipeline run, emit these fields:
-
Completion events:
provider,model,latency_ms,tokens_total,error_message,created_at -
RAG events:
top_k,top_n,retrieval_scores,rerank_scores,retrieval_latency_ms,rerank_latency_ms,created_at -
Citation events:
message_id,evidence_count,created_at -
RAGAS evaluation events:
query_id,faithfulness,answer_relevancy,context_precision,context_recall,context_relevancy,answer_correctness,answer_similarity,created_at(all score fields are optional floats in[0, 1]) -
2) Example SQL schema (PostgreSQL)
CREATE TABLE completion_logs (
id BIGSERIAL PRIMARY KEY,
provider TEXT NOT NULL,
model TEXT,
latency_ms DOUBLE PRECISION,
tokens_total INTEGER,
error_message TEXT,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE TABLE rag_logs (
id BIGSERIAL PRIMARY KEY,
top_k INTEGER,
top_n INTEGER,
retrieval_scores JSONB,
rerank_scores JSONB,
retrieval_latency_ms DOUBLE PRECISION,
rerank_latency_ms DOUBLE PRECISION,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE TABLE citation_events (
id BIGSERIAL PRIMARY KEY,
message_id TEXT NOT NULL,
evidence_count INTEGER NOT NULL DEFAULT 0,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE TABLE raga_evaluations (
id BIGSERIAL PRIMARY KEY,
query_id TEXT NOT NULL,
faithfulness DOUBLE PRECISION,
answer_relevancy DOUBLE PRECISION,
context_precision DOUBLE PRECISION,
context_recall DOUBLE PRECISION,
context_relevancy DOUBLE PRECISION,
answer_correctness DOUBLE PRECISION,
answer_similarity DOUBLE PRECISION,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE INDEX idx_completion_logs_created_at ON completion_logs (created_at);
CREATE INDEX idx_rag_logs_created_at ON rag_logs (created_at);
CREATE INDEX idx_citation_events_created_at ON citation_events (created_at);
CREATE INDEX idx_raga_evaluations_created_at ON raga_evaluations (created_at);
3) Wire repository and service
from datetime import datetime, timedelta
from sqlalchemy.orm import Session
from langmet.adapters.sqlalchemy_repo import SQLAlchemyMetricsRepository
from langmet.service import AnalyticsService
def get_metrics_payload(db: Session) -> dict:
repo = SQLAlchemyMetricsRepository(db)
svc = AnalyticsService(repo)
start = datetime.utcnow() - timedelta(days=7)
end = datetime.utcnow()
return {
"operational": svc.get_operational_metrics(start, end),
"rag": svc.get_rag_metrics(start, end),
"citation_coverage": svc.get_citation_coverage(start, end),
"raga": svc.get_raga_metrics(start, end),
}
4) Expose in API
from fastapi import FastAPI
app = FastAPI()
@app.get("/api/metrics")
def metrics():
# replace with your Session management
payload = get_metrics_payload(db_session)
return payload
5) Add drift monitoring
from datetime import timedelta
from langmet.analytics import detect_numeric_drift_windowed
drift = detect_numeric_drift_windowed(
observations=latency_observations, # list[(timestamp, latency_ms)]
current_window=timedelta(hours=1),
baseline_window=timedelta(days=7),
min_samples_per_window=20,
)
6) Frontend contract
Your UI only needs:
GET /api/metricsfor overview cards and tablesGET /api/drift(or drift in same payload) for alerts
Keep response keys stable:
operational.overviewrag.overviewcitation_coverageraga.overview,raga.scores,raga.evaluation_counts
7) Production checklist
- Store timestamps in UTC (
TIMESTAMPTZ) - Index
created_aton telemetry tables - Add cache TTL for dashboard polling endpoints
- Define alert thresholds for:
- latency percentiles (
p95,p99) - error rate
- drift (
psi,tvd)
- latency percentiles (
- Add data retention policy (for example 30–90 days hot storage)
Core Concepts
langmet.models: event contracts used by analyticslangmet.analytics: pure computation functionslangmet.ports: repository protocol your project can implementlangmet.service: orchestration facadelangmet.adapters: optional infrastructure adapters
Development
pip install -e ".[dev,sqlalchemy]"
ruff check .
pytest
python -m build
twine check dist/*
License
MIT


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file langmet-0.2.0.tar.gz.
File metadata
- Download URL: langmet-0.2.0.tar.gz
- Upload date:
- Size: 17.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4c42b3fd600608ed6fbca6dc6545fb34a46793cb50060f75327e36ddf9c6472f
|
|
| MD5 |
09a381803d5fc8badaefcb01385fa945
|
|
| BLAKE2b-256 |
d285b856ebeba4e8f1b4150775d8920e703feeed99b201f487a1795abc6e7e50
|
Provenance
The following attestation bundles were made for langmet-0.2.0.tar.gz:
Publisher:
publish.yml on mabrouka-abuhmida/LangMet
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
langmet-0.2.0.tar.gz -
Subject digest:
4c42b3fd600608ed6fbca6dc6545fb34a46793cb50060f75327e36ddf9c6472f - Sigstore transparency entry: 1703441693
- Sigstore integration time:
-
Permalink:
mabrouka-abuhmida/LangMet@a08377c4ebd17a925aff1d3888209383f77f73d8 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/mabrouka-abuhmida
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@a08377c4ebd17a925aff1d3888209383f77f73d8 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file langmet-0.2.0-py3-none-any.whl.
File metadata
- Download URL: langmet-0.2.0-py3-none-any.whl
- Upload date:
- Size: 16.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
36e758518243cbcc0b5afc3bd55f2d259810d9a0f73692ebf8c52a9c0aa7e048
|
|
| MD5 |
43e6543bc40ac9c3b249e10e06334590
|
|
| BLAKE2b-256 |
a7df8393437dae7dedc3a6a9cbe1b09dc050bce85bfb0330ef8cec5a380265af
|
Provenance
The following attestation bundles were made for langmet-0.2.0-py3-none-any.whl:
Publisher:
publish.yml on mabrouka-abuhmida/LangMet
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
langmet-0.2.0-py3-none-any.whl -
Subject digest:
36e758518243cbcc0b5afc3bd55f2d259810d9a0f73692ebf8c52a9c0aa7e048 - Sigstore transparency entry: 1703441732
- Sigstore integration time:
-
Permalink:
mabrouka-abuhmida/LangMet@a08377c4ebd17a925aff1d3888209383f77f73d8 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/mabrouka-abuhmida
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@a08377c4ebd17a925aff1d3888209383f77f73d8 -
Trigger Event:
workflow_dispatch
-
Statement type:







