OOMMFTools is a set of drag-and-drop GUI utilities to assist in OOMMF postprocessing, including imageconversion and vector file manipulation.

Project description
OOMMFTools
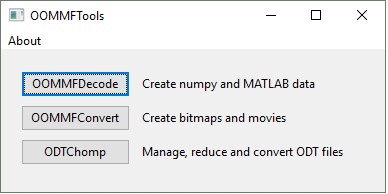
Introduction
OOMMFTools is a set of utilities designed to assist OOMMF postprocessing with an intuitive, graphical interface. It includes the following subcomponents:
-OOMMFDecode : Converts OOMMF vector files into numpy arrays and/or MATLAB data files
-OOMMFConvert: Converts OOMMF vector files into bitmaps and movies
-ODTChomp : Converts ODT files or subsets thereof into normally-delimited text files
OOMMFTools was original developed by Mark Mascaro. The version hosted here incorporates some additional code and compatability with recent libraries.
Bug reports and feature requests should logged on github.
Installation
Clone this repository to get the latest code:
>>> git clone https://github.com/deparkes/OOMMFTools.gitThe easiest way to install the modules needed for OOMMFTools is to use the Anaconda Distribution. The OOMMFTools repository contains an environment yaml file with the dependencies it needs.
>>> conda env create -f environment.yml
>>> python oommftools/oommftools.pyInstall Dependencies
OOMMFTools has the following dependencies:
Python 2.7
wxPython 4.x
numpy
scipy
FFmpeg - needed for OOMMFConvert
OOMMF - needed for OOMMFConvert
Tcl/Tk - needed for OOMMFConvert
OOMMFDecode
OOMMFDecode batch-processes vector files (omf, ovf, oef, ohf) into numpy arrays. These can then be pickled, for python users, or saved into MATLAB data files, for MATLAB users.
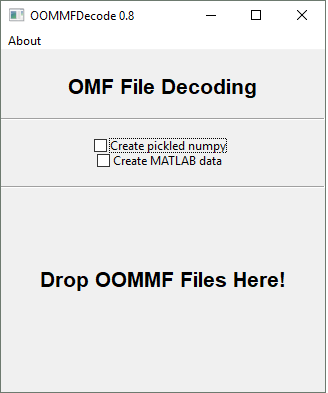
1. UTILIZATION
The GUI is very simple. Two checkboxes are offered - for making numpy data and for making MATLAB data. Simply check the options for the types of data you want to save and drag one or more OMF files onto the application. The data format (text, binary 4, binary 8) is automatically detected. When the import is finished, you’ll be prompted to save the data for each format you selected.
Dropping a batch of OMF files is primarily designed to automate aggregation of data from various states of a single simulation. The program assumes all files you drop at a time are “similar” - that is, they have the same grid size and other header data. Please be mindful of this constraint, and if you wish to convert files from several disparate simulations do so in different drop operations.
Some files (such as energy densities) contain only a single value, not a vector. In OOMMF, these outputs are still vector files. The relevant quantity is stored in the X coordinate.
A. MATLAB Data
The output .MAT file contains several variables.
First, a 3-element vector GridSize, which contains the X, Y, and Z span of each cell. This is imported from the OMF file headers, specifically from the first file on the list of dropped files (again, it is assumed all files in one batch are similar).
Second, a vector SimTime, which contains the simulation time associated with each OMF file, if any. The input files are sorted based on SimTime if and only if times are available for all files.
Third and fourth, the vectors Iteration and Stage, which contain the iteration and stage number associated with each OMF file, if any. This is the total iteration number, not the stage iteration number.
The final variable is a 5-D matrix OOMMFData, which can be understood as follows.
OOMMFData(A,B,C,D,E):
The index of the OMF file, in simulation time order. If simtime data is not available, the files are in the same order as they were dropped on the program, which is generally the operating system sort order.
X coordinate in first-octant coordinates.
Y coordinate in first-octant coordinates.
Z coordinate in first-octant coordinates.
(1,2,3) are the x,y,z components of the vector.
Note that everything is indexed in the OOMMF (first-octant) coordinate system, but row-column matrix notation is fourth-quadrant. Depending on what you’re trying to do, it may be necessary to transform the data accordingly. When in doubt, remember that indices into matrices generated by this program match OOMMF’s own numbers!
B. numpy Data
The output .PNP file can be unpickled into a tuple containing two items: first, a 5-D matrix as documented above; second, a dictionary of header values extracted from the OMF file header data. This latter data is useful for looking up the scale of each cell or the simulation time of a particular file.
OOMMFConvert
OOMMFConvert is meant to ease converting OOMMF simulation results into bitmaps and movies, especially for Windows users for whom the console is more unfamiliar or difficult. It uses the existing avf2ppm capability of OOMMF, along with the open-source utility FFmpeg for movie conversion.
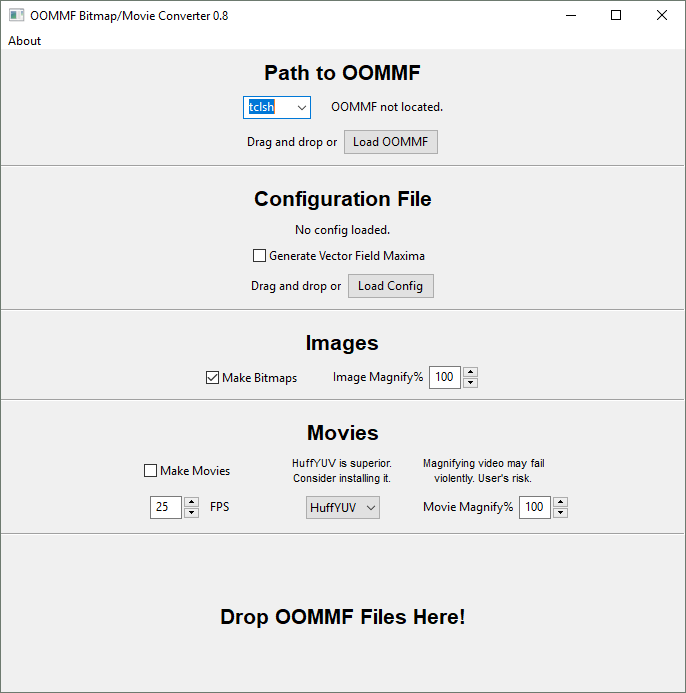
1. Utilization
The GUI is divided into five sections as follows.
A. Path to OOMMF - configures Tcl shell calls
The left dropbox contains the call necessary to involve tcl. This defaults to and should almost always be left on the value “tclsh”. However, some Windows installations of ActiveTcl/Tk use other commands, such as tclsh85 (which is provided as a dropdown option). If necessary, enter a new value here.
The static text field to the right shows the path to the oommf.tcl file in your OOMMF installation. This is the file that will be called to invoke avf2ppm. You can use the “Load OOMMF” button to locate it, or simply drag the oommf.tcl file anywhere over the program window. This path is recorded in the file oommf.path in the program directory, and this configuration step is only necessary once.
B. Configuration File - shows mmDisp configuration file
This section shows which mmDisp configuration file is going to be used in avf2ppm. You can save an mmDisp configuration file from an mmDisp view with the “Write config…” option in the File menu. You can select a configuration file with the “Load Config” button, or by dragging a file with the extension .conf, .config, or .cnf anywhere within the program window. The text shows the absolute path to the currently selected config file. This value is NOT saved between sessions, as it is typically sim-dependent and unique for different groups of OMF files. To clarify, it is saved between file drops, so you can easily use the same configuration file to convert multiple batches of OMF files without closing the program.
For the magnetization, the maximum value of the vector field is fixed (Ms). For other kinds of fields, such as demag, the maximum value of the vector field may fluctuate from file to file. This could result in clipping unless you happened to use the largest-values o?f file to produce your config file. If you’re using a field where the maximum value fluctuates significant, check “generate vector field maxima”. If this is checked, the program will decode the files to be converted and find the maximum vector magnitude among all files. This can add significantly to the runtime, but makes it easy to generate uniformly-scaled pictures for these sorts of fields without clipping.
C. Images - configures bitmap output
This section controls the bitmap file output. If “Make Bitmaps” is unchecked, no images will be created. It defaults on. “Image Magnify%” overrides the parameters in the mmDisp configuration file to increase the output bitmap size. It employs a temporary copy of the configuration file, and the original is not overwritten. The value is in percent of the OOMMF default size, usually around 640x480.
D. Movies - configures movie output
This section controls the output of a movie file based on a collection of input OMF files. A movie will be made from each batch of OMF files if “Make Movies” is checked, but it defaults off.
The leftmost configuration on the bottom row is the FPS of the output movie. You may also consider it “simulation files per second.” Since FFmpeg uses an awkward fixed-framerate form, frames will be duplicated to fill in time when the FPS is reduced. These temporary files are cleaned up automatically. This value can be between 1 and 25 FPS, and defaults to 25.
The middle combo box allows the choice of encoding from a number of codecs built into FFmpeg. The default is HuffYUV, which I find gives the best-quality output files for the common red-white-blue color scheme. MPEG4 has some difficulty with the black-on-blue arrows and gives a visibly worse encoding. The HuffYUV decoder does not come standard on most systems (Windows) but is freely available, and I highly suggest using this codec.
The rightmost control is the movie magnification, which functions similarly to the image magnification. However, many codecs are unstable for large input image sizes (above around 140% over the OOMMF default size) and may fail silently. This is a bug in the encoder and cannot be worked around. Therefore, increasing the movie magnification is done at the user’s risk. The default codec HuffYUV is quite robust, and readily supports use of the movie magnification control.
E. Drop OOMMF Files Here! - a friendly reminder
Drag and drop configuration and vector field files here - or anywhere in the program window, but this section is a friendly reminder. Multiple files can be dropped at a time. OMF files are converted to bitmaps using the oommf command line utility avf2ppm and the supplied mmDisp configuration file. If a movie is being made, the batch of simultaneously dropped OMF files is converted to a single movie with the frames in filename order.
ODTChomp
ODTChomp takes in ODT data tables, simplifies the name scheme to the extent it it possible, and outputs the desired columns into a text file with a given delimeter. The behavior is rather distict from odtcols, which is better at fixed-width rather than fixed-delimitation formatting.
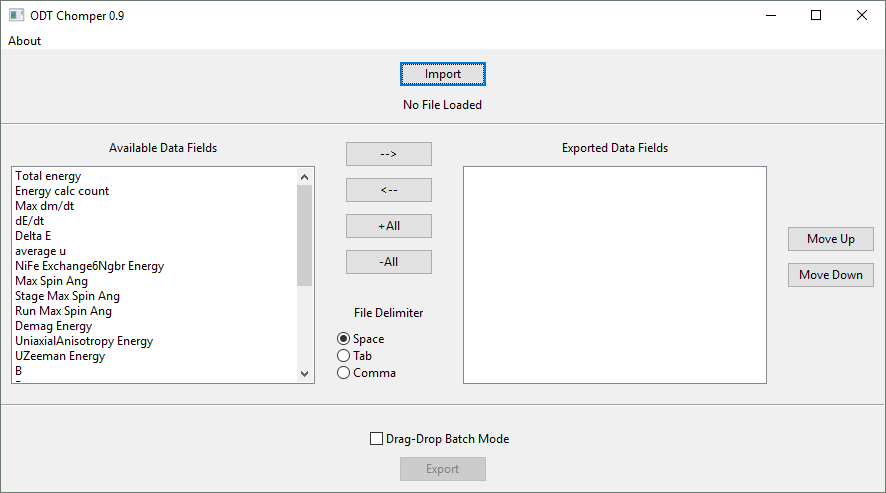
1. Utilization
Begin by loading an ODT file. Drag-and-drop also works. The leftmost panel shows the columns found in the ODT file, using a simplified name scheme that uses the minimum number of uniquely identifying descriptors. The result is generally very human-readable unless the simulation file is extremely complex. The right panel shows which data fields will appear in the output file.
Double-clicking an entry in the left panel, or clicking an entry and then the “–>” button, will mark it for export. Double-clicking an entry in the right panel, or clicking an entry and then the “<–” button, will remove it from the export. The subsequent set of buttons can be used to add or remove all fields from the output file. The “Move Up” and “Move Down” buttons affect the item highlighted in the right panel, and are used to reorder the output columns.
The radio buttons between the two panels choose the delimiting symbol for the values in the output. For example, if you want the comma-separated values commonly used by Excel, choose comma. If you choose space as the delimited, spaces that appear in column names will be replaced by underscores in the output.
Finally, the export button writes the selected columns in the selected order to a plaintext file.
2. Batch Mode
The checkbox just above the Export button enables Batch Mode. Batch Mode is designed to extract the same data fields from a large group of ODT files using drag-and-drop. Batch Mode can only be used once one file has already been loaded and export data has been selected. Even if Batch Mode is checked, if no file has previously been loaded, the first file drop will give non-batch behavior.
Once a file has been loaded and data fields have been chosen, any files dragged and dropped onto ODTChomp with Batch Mode enabled will have the specified fields extracted. The output will be placed in the same folder as the dropped file, with the same filename and the “.txt” extension. Currently, dropping directories is not supported and they will not be recursed.
Development
Running Tests
$pytest - run all tests
$pytest tests/test_odtchomp.py - run test for one file
$pytest tests/test_odtchomp.py::Test_headers_prettify - run specific testRunning pylint
pylint –extension-pkg-whitelist=wx –output-format=colorized oommftools/oommftools.py
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file oommftools-2.0.1.dev20180308.tar.gz.
File metadata
- Download URL: oommftools-2.0.1.dev20180308.tar.gz
- Upload date:
- Size: 22.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1c77b2cff1fa6960f0234e27ceeb9d5f1c5319ae3400ddc5bcbea8465dd94335
|
|
| MD5 |
1fe30c4b3ca4fa38676fe75bf5a03d90
|
|
| BLAKE2b-256 |
624bffd09ae92ee976657f66630aa560b92e216e600338252706740161b598d9
|
File details
Details for the file oommftools-2.0.1.dev20180308-py2-none-any.whl.
File metadata
- Download URL: oommftools-2.0.1.dev20180308-py2-none-any.whl
- Upload date:
- Size: 33.8 kB
- Tags: Python 2
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f4e0b651e594c4c98475e7ab3a99d82f4a345315274e8f8280a19d067a704f5c
|
|
| MD5 |
5b81caaea16c4c57ea3facf9cabb5c94
|
|
| BLAKE2b-256 |
1159776fcf230b520deadb2e41083c3916abf8656c83b41b84410e42d4d66283
|







