An ETL pipeline to transform your EMP data to OMOP.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

Rabbit in a Blender (RiaB) is an ETL pipeline CLI to transform your EMR data to OMOP.
Why the name 'Rabbit in a Blender'? It stays in the rabbit theme of the OHDSI tools, and an ETL pipeline is like putting all your data in a blender.
No rabbits were harmed during the development of this tool!
Introduction
Extract-Transform-Load (ETL) processes are very complex and are mainly crafted by highly skilled data engineers. The process of transforming the electronic medical record (EMR) data into the observational medical outcomes partnership (OMOP) common data model (CDM) is no exception. The mapping process of the source values to standard concepts is mostly done by subject matter experts, who lack the knowledge of programming the ETL process. Wouldn’t it be nice if we could drastically simplify the ETL process, so that you don’t need seasoned data engineers to start the OMOP CDM journey. Imagine that you just save your queries, Usagi comma separated value (CSV) text files and custom concept CSV’s on disk, and run a command line interface (CLI) tool that does all the ETL magic automatically.
Currently, our ETL process is supported by BigQuery and SQL Server (both on-premise and in Azure). We're open to exploring additional database technologies to serve as backends for our ETL process.
Concept
The main strength of the CDM is its simplified scheme. This scheme is a relational data model, where each table has a primary key and can have foreign keys to other tables. Because of the relational data model, we can extract the dependencies of the tables from the scheme. For example, the provider table is dependent on the care_site table, which is in its turn dependent on the location table. If we flatten that dependency graph, we have a sequence of ETL steps that we need to follow to have consistent data in our OMOP CDM.
These ETL steps can be automated, so a hospital can focus its resources on the queries and the mapping of the concepts. The automated ETL consists of multiple tasks. It needs to execute queries, add custom concepts, apply the Usagi source to concept mapping, and do a lot of housekeeping. An example of that housekeeping is the autonumbering of the OMOP CDM primary keys, for which the ETL process needs to maintain a swap table that holds the key of the source table and the generated sequential number of the CDM table’s primary key. Another example of the housekeeping is the upload and processing of the Usagi CSV’s and also the upload and parsing of the custom concept CSV’s.
In an ETL process data is divided in zones (cfr. the zones in a data lake). The raw zone holds the source data (for example the data from the EMR), the work zone holds all the house keeping tables of the ETL process and the gold zone holds our final OMOP CDM.
After designing the architecture, the implementation needs to be developed. We have two options to choose from: configuration and convention as design paradigm. We choose convention over configuration, because it decreases the number of decisions the user has to make and eliminates the complexity. As convention a specific folder structure is adopted (see our mappings as example). A folder is created for each OMOP CDM table, where the SQL queries are stored to fill up the specific CDM table. In the table folders we also have for each concept column a sub folder. Those concept column sub folders hold our Usagi CSV’s (files ending with _usagi.csv). We also have a custom folder in the concept column sub folder, that holds the custom concept CSV’s (files ending with _concept.csv). With this convention in place, our ETL CLI tool has everything it needs to do its magic.
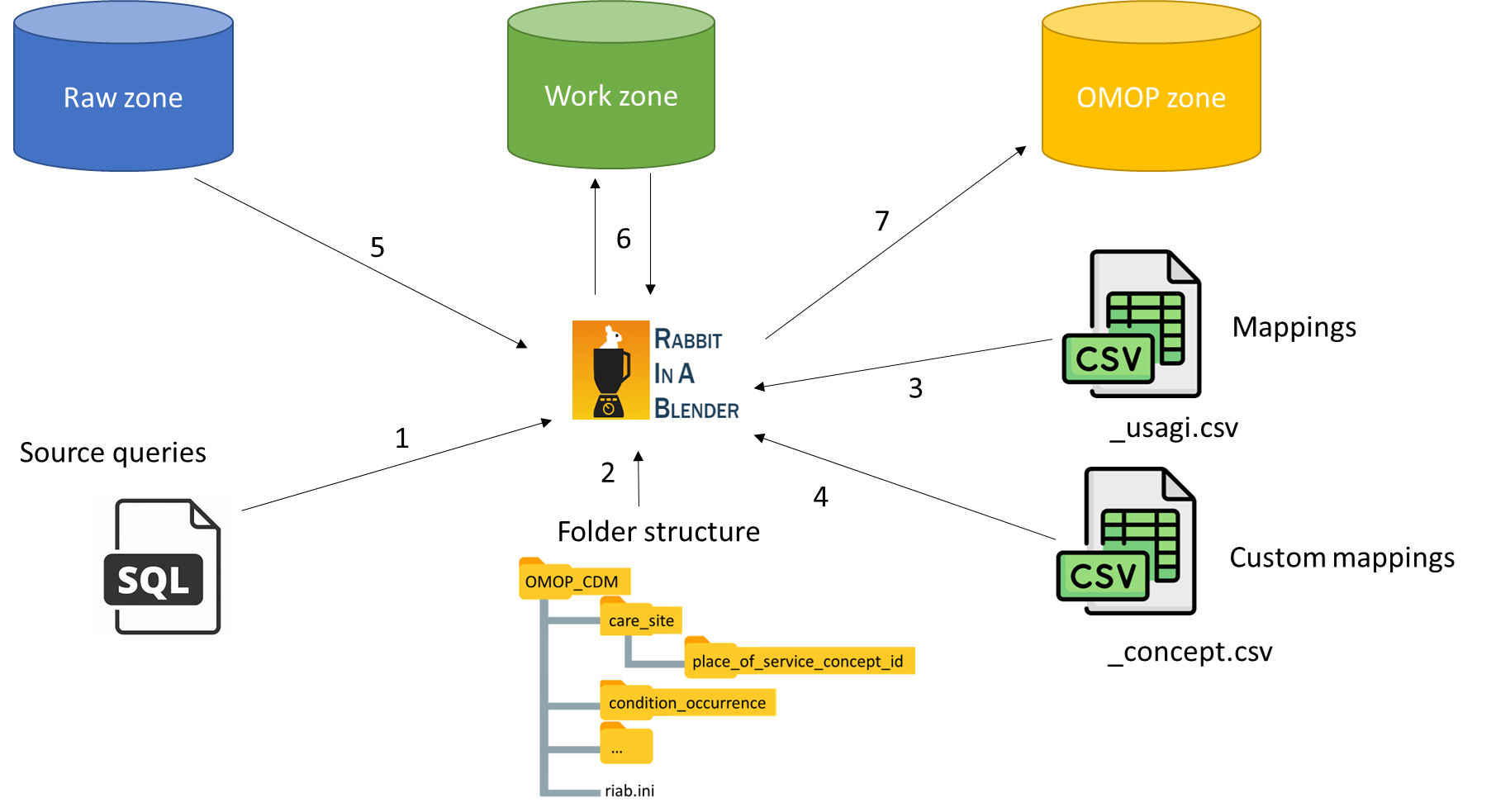
One final requirement we want to build in the ETL CLI tool, is that each ETL step is an atomic operation, it either fails or succeeds, so that there is no possibility to corrupt the final OMOP CDM data.
ETL flow
The ETL flow is like a two-stage rocket. You have a first stage and a second stage in the ETL process.

First stage:
Most CDM tables have foreign keys (FKs) to other tables. Some tables can be processed in parallel by the ETL engine, because they have no FKs dependencies between them, others have to be processed in a specific order.
The ETL flow for v5.4 is as follows:
└──vocabulary
├──cdm_source
├──metadata
├──cost
├──fact_relationship
└──location
└──care_site
└──provider
└──person
├──condition_era
├──death
├──dose_era
├──drug_era
├──episode
├──observation_period
├──payer_plan_period
├──specimen
└──visit_occurrence
├──episode_event
└──visit_detail
├──condition_occurrence
├──device_exposure
├──drug_exposure
├──measurement
├──note
├──observation
└──procedure_occurrence
└──note_nlp
Second stage: will process all the event foreign key columns (e.g. observation_event_id, cost_event_id, measurement_event_id, etc.). Because those columns can point to almost any table, and the auto generated _id's of those table, are only available after the first stage.
RiaB also performs like a rocket especially in combination with BigQuery. A full ETL resulting in 8 billion CDM records takes about 20 min.
Getting started
see getting started
CLI Usage
see CLI commands
Authors
License
Copyright © 2024, RADar-AZDelta. Released under the GNU General Public License v3.0.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rabbit_in_a_blender-0.0.74.tar.gz.
File metadata
- Download URL: rabbit_in_a_blender-0.0.74.tar.gz
- Upload date:
- Size: 515.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eed59b60c1a8cbb9e175fdf508946d941beb7b4cd4e8f668dd1f6488c40115c3
|
|
| MD5 |
7e5a459d50563209333d253d3eeb7a90
|
|
| BLAKE2b-256 |
410960e60cec9b04d34910154611bdf56492b1761e0d964c14ebf4196dc84d2a
|
Provenance
The following attestation bundles were made for rabbit_in_a_blender-0.0.74.tar.gz:
Publisher:
publish_to_pypi_and_build_container.yml on RADar-AZDelta/Rabbit-in-a-Blender
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
rabbit_in_a_blender-0.0.74.tar.gz -
Subject digest:
eed59b60c1a8cbb9e175fdf508946d941beb7b4cd4e8f668dd1f6488c40115c3 - Sigstore transparency entry: 203561697
- Sigstore integration time:
-
Permalink:
RADar-AZDelta/Rabbit-in-a-Blender@ae946444daed376074db6bbaf3eea6a6977f6338 -
Branch / Tag:
refs/tags/0.0.74 - Owner: https://github.com/RADar-AZDelta
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish_to_pypi_and_build_container.yml@ae946444daed376074db6bbaf3eea6a6977f6338 -
Trigger Event:
push
-
Statement type:
File details
Details for the file rabbit_in_a_blender-0.0.74-py3-none-any.whl.
File metadata
- Download URL: rabbit_in_a_blender-0.0.74-py3-none-any.whl
- Upload date:
- Size: 797.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
273075f3e5dac8f16201ee1f220f8845929260e7fb91da1f5bf4f086cd7f865d
|
|
| MD5 |
dcd02c665d15595cbcd969fa32a04e97
|
|
| BLAKE2b-256 |
8622176dae98ab22aa4e44647a19eb1ea4950310848d3c4bb4663d257f1a7bb7
|
Provenance
The following attestation bundles were made for rabbit_in_a_blender-0.0.74-py3-none-any.whl:
Publisher:
publish_to_pypi_and_build_container.yml on RADar-AZDelta/Rabbit-in-a-Blender
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
rabbit_in_a_blender-0.0.74-py3-none-any.whl -
Subject digest:
273075f3e5dac8f16201ee1f220f8845929260e7fb91da1f5bf4f086cd7f865d - Sigstore transparency entry: 203561702
- Sigstore integration time:
-
Permalink:
RADar-AZDelta/Rabbit-in-a-Blender@ae946444daed376074db6bbaf3eea6a6977f6338 -
Branch / Tag:
refs/tags/0.0.74 - Owner: https://github.com/RADar-AZDelta
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish_to_pypi_and_build_container.yml@ae946444daed376074db6bbaf3eea6a6977f6338 -
Trigger Event:
push
-
Statement type:







