Oblique decision tree with svm nodes.

Project description
STree








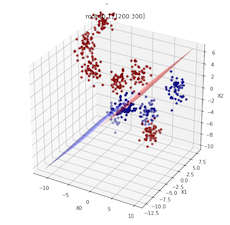
Oblique Tree classifier based on SVM nodes. The nodes are built and splitted with sklearn SVC models. Stree is a sklearn estimator and can be integrated in pipelines, grid searches, etc.
Installation
pip install Stree
Documentation
Can be found in stree.readthedocs.io
Examples
Jupyter notebooks
-
Benchmark
-
-
-
Hyperparameters
| Hyperparameter | Type/Values | Default | Meaning | |
|---|---|---|---|---|
| * | C | <float> | 1.0 | Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. |
| * | kernel | {"liblinear", "linear", "poly", "rbf", "sigmoid"} | linear | Specifies the kernel type to be used in the algorithm. It must be one of ‘liblinear’, ‘linear’, ‘poly’ or ‘rbf’. liblinear uses liblinear library and the rest uses libsvm library through scikit-learn library |
| * | max_iter | <int> | 1e5 | Hard limit on iterations within solver, or -1 for no limit. |
| * | random_state | <int> | None | Controls the pseudo random number generation for shuffling the data for probability estimates. Ignored when probability is False. Pass an int for reproducible output across multiple function calls |
| max_depth | <int> | None | Specifies the maximum depth of the tree | |
| * | tol | <float> | 1e-4 | Tolerance for stopping criterion. |
| * | degree | <int> | 3 | Degree of the polynomial kernel function (‘poly’). Ignored by all other kernels. |
| * | gamma | {"scale", "auto"} or <float> | scale | Kernel coefficient for ‘rbf’, ‘poly’ and ‘sigmoid’. if gamma='scale' (default) is passed then it uses 1 / (n_features * X.var()) as value of gamma, if ‘auto’, uses 1 / n_features. |
| split_criteria | {"impurity", "max_samples"} | impurity | Decides (just in case of a multi class classification) which column (class) use to split the dataset in a node**. max_samples is incompatible with 'ovo' multiclass_strategy | |
| criterion | {“gini”, “entropy”} | entropy | The function to measure the quality of a split (only used if max_features != num_features). Supported criteria are “gini” for the Gini impurity and “entropy” for the information gain. |
|
| min_samples_split | <int> | 0 | The minimum number of samples required to split an internal node. 0 (default) for any | |
| max_features | <int>, <float> or {“auto”, “sqrt”, “log2”} |
None | The number of features to consider when looking for the split: If int, then consider max_features features at each split. If float, then max_features is a fraction and int(max_features * n_features) features are considered at each split. If “auto”, then max_features=sqrt(n_features). If “sqrt”, then max_features=sqrt(n_features). If “log2”, then max_features=log2(n_features). If None, then max_features=n_features. |
|
| splitter | {"best", "random", "trandom", "mutual", "cfs", "fcbf", "iwss"} | "random" | The strategy used to choose the feature set at each node (only used if max_features < num_features). | |
| Supported strategies are: “best”: sklearn SelectKBest algorithm is used in every node to choose the max_features best features. “random”: The algorithm generates 5 candidates and choose the best (max. info. gain) of them. “trandom”: The algorithm generates only one random combination. "mutual": Chooses the best features w.r.t. their mutual info with the label. "cfs": Apply Correlation-based Feature Selection. "fcbf": Apply Fast Correlation-Based Filter. "iwss": IWSS based algorithm | ||||
| normalize | <bool> | False | If standardization of features should be applied on each node with the samples that reach it | |
| * | multiclass_strategy | {"ovo", "ovr"} | "ovo" | Strategy to use with multiclass datasets, "ovo": one versus one. "ovr": one versus rest |
* Hyperparameter used by the support vector classifier of every node
** Splitting in a STree node
The decision function is applied to the dataset and distances from samples to hyperplanes are computed in a matrix. This matrix has as many columns as classes the samples belongs to (if more than two, i.e. multiclass classification) or 1 column if it's a binary class dataset. In binary classification only one hyperplane is computed and therefore only one column is needed to store the distances of the samples to it. If three or more classes are present in the dataset we need as many hyperplanes as classes are there, and therefore one column per hyperplane is needed.
In case of multiclass classification we have to decide which column take into account to make the split, that depends on hyperparameter split_criteria, if "impurity" is chosen then STree computes information gain of every split candidate using each column and chooses the one that maximize the information gain, otherwise STree choses the column with more samples with a predicted class (the column with more positive numbers in it).
Once we have the column to take into account for the split, the algorithm splits samples with positive distances to hyperplane from the rest.
Tests
python -m unittest -v stree.tests
License
STree is MIT licensed
Reference
R. Montañana, J. A. Gámez, J. M. Puerta, "STree: a single multi-class oblique decision tree based on support vector machines.", 2021 LNAI 12882, pg. 54-64
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stree-1.4.2.tar.gz.
File metadata
- Download URL: stree-1.4.2.tar.gz
- Upload date:
- Size: 24.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f8a617b99fb6a5593c7dd42fb4c4895a08a7e287792617c745a15eafeabe253a
|
|
| MD5 |
1988e806bff119f5ead511834fd4a0ea
|
|
| BLAKE2b-256 |
eb1f5d50c7838ddbe4fbcc45ca6cca35116fc7875cc86a5736e601410627c8ea
|
File details
Details for the file stree-1.4.2-py3-none-any.whl.
File metadata
- Download URL: stree-1.4.2-py3-none-any.whl
- Upload date:
- Size: 27.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b71c48816f8d6d892fd5c38979512f36df804dc48ab3fad8900c836bfd1e6307
|
|
| MD5 |
4f8f86486a6468ede78797534def09b2
|
|
| BLAKE2b-256 |
6af35c8aa1d5de54aaff68f4dcb3690bc8f8e934965a1f74877721d977b9f417
|







