a spider admin based scrapyd api and APScheduler

Project description
SpiderAdmin




功能介绍
-
对Scrapyd 接口进行可视化封装,对Scrapy爬虫项目进行删除 和 查看
-
并没有实现修改,添加功能, 部署推荐使用
$ scrapyd-deploy -a
- 对爬虫设置定时任务,支持apscheduler 的3中方式和随机延时,共计4中方式
- 单次运行 date
- 周期运行 corn
- 间隔运行 interval
- 随机运行 random
- 基于Flask-BasicAuth 做了简单的权限校验
启动运行
$ pip3 install -U spideradmin
$ spideradmin init # 初始化,可选配置,也可以使用默认配置
$ spideradmin # 启动服务
开启站点认证
修改启动目录下配置文件config.py
# 如果为 True 整个站点都验证, 默认不验证
BASIC_AUTH_FORCE = True
页面截图
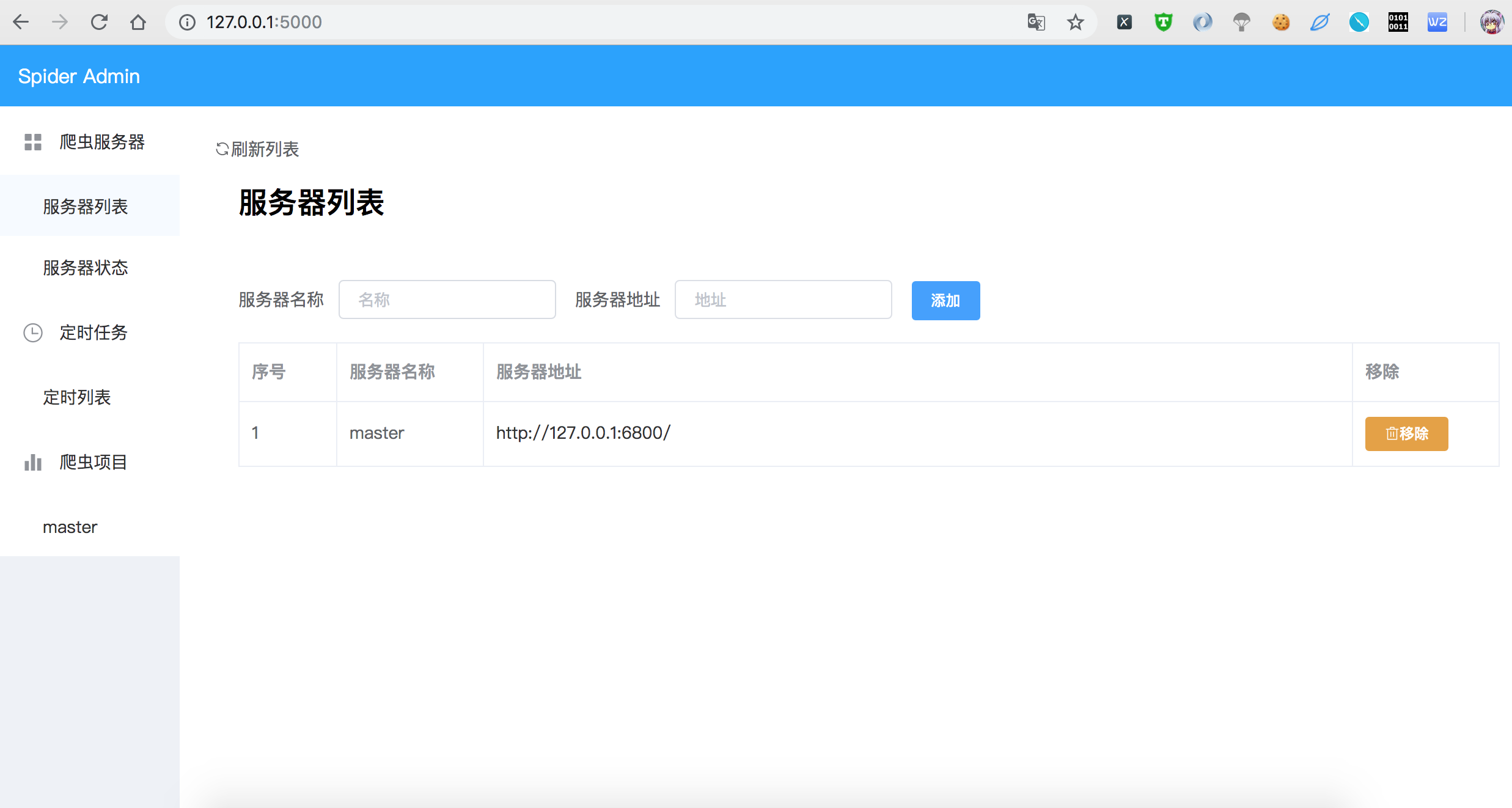
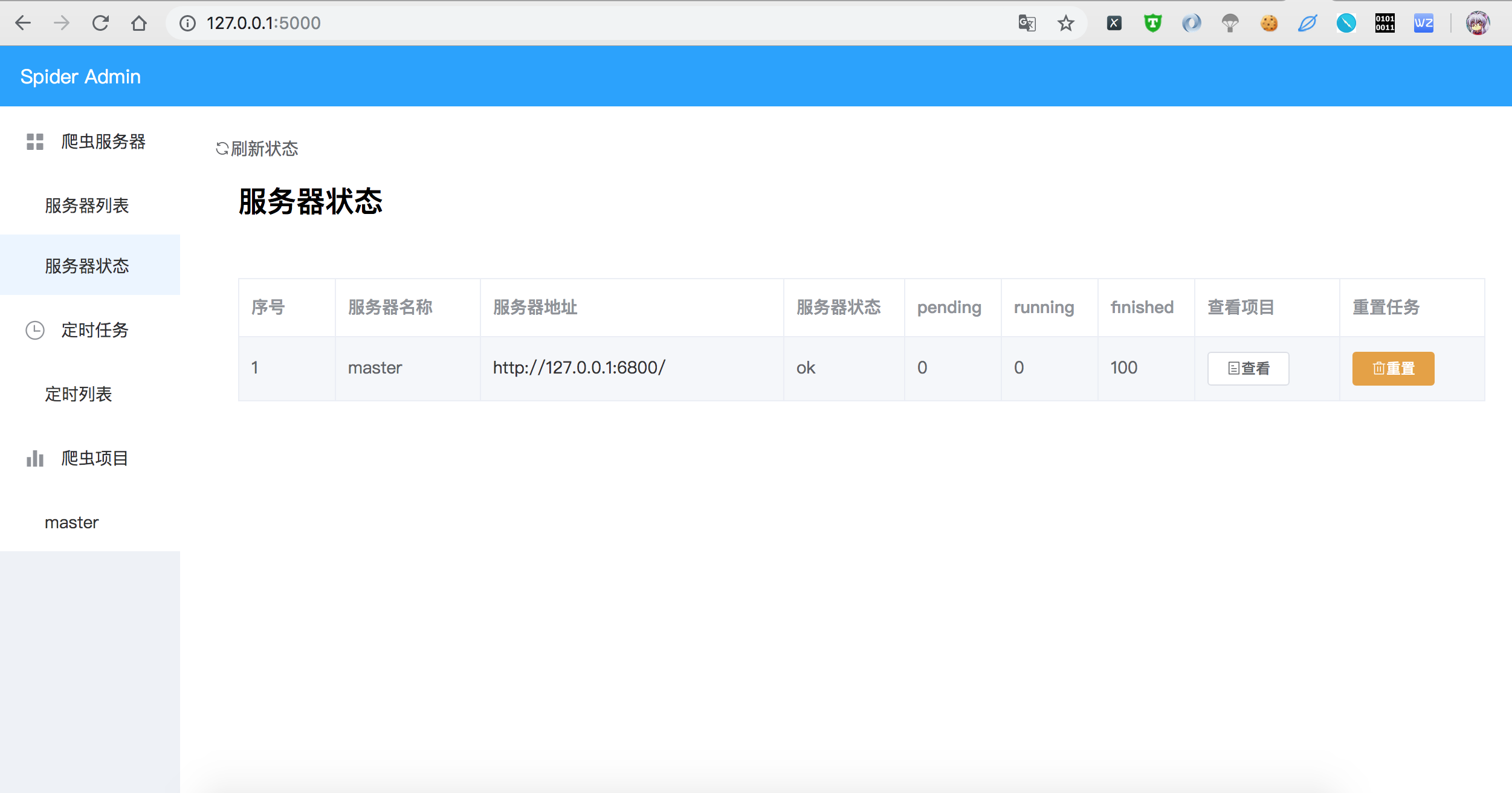
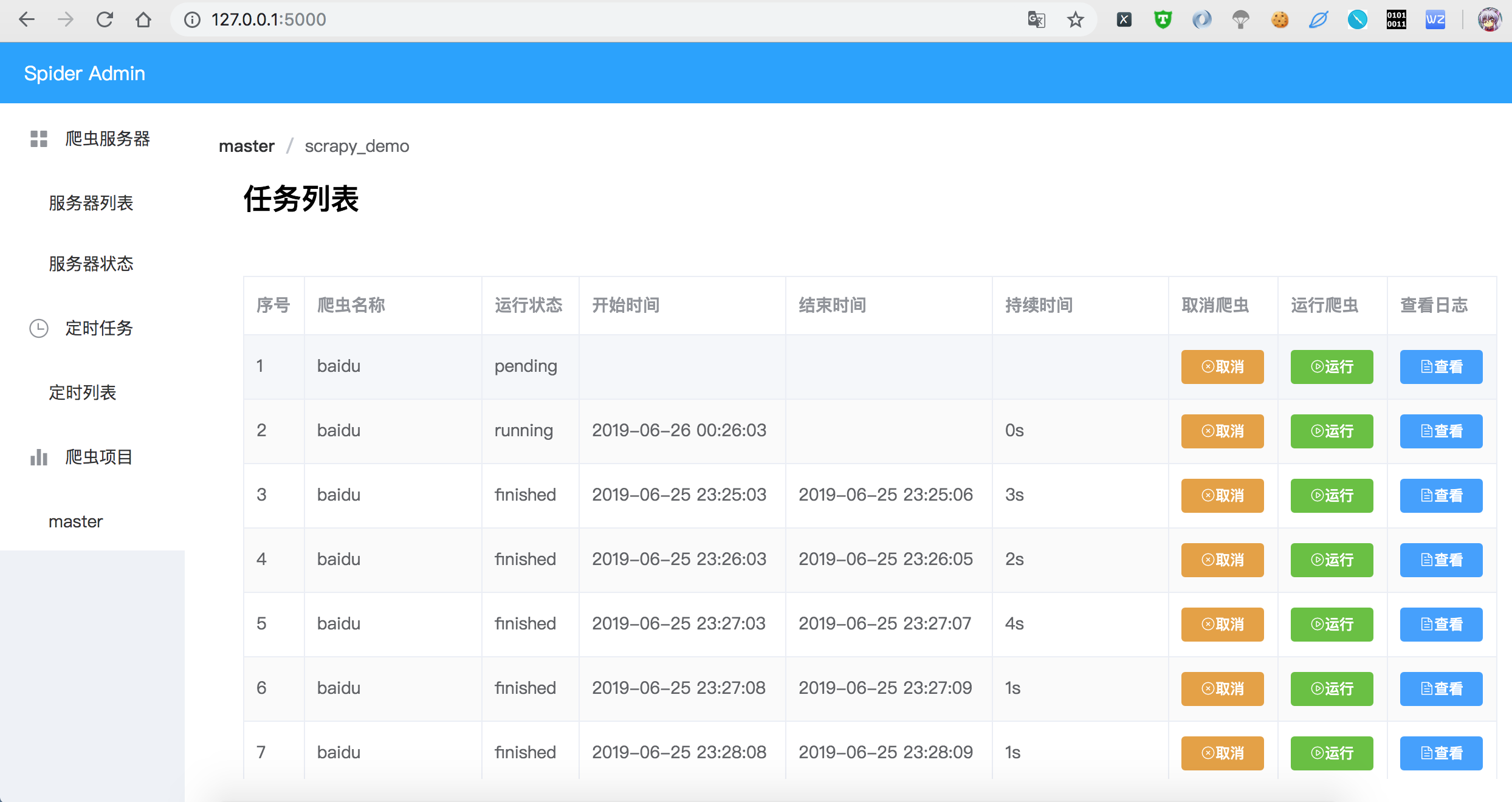
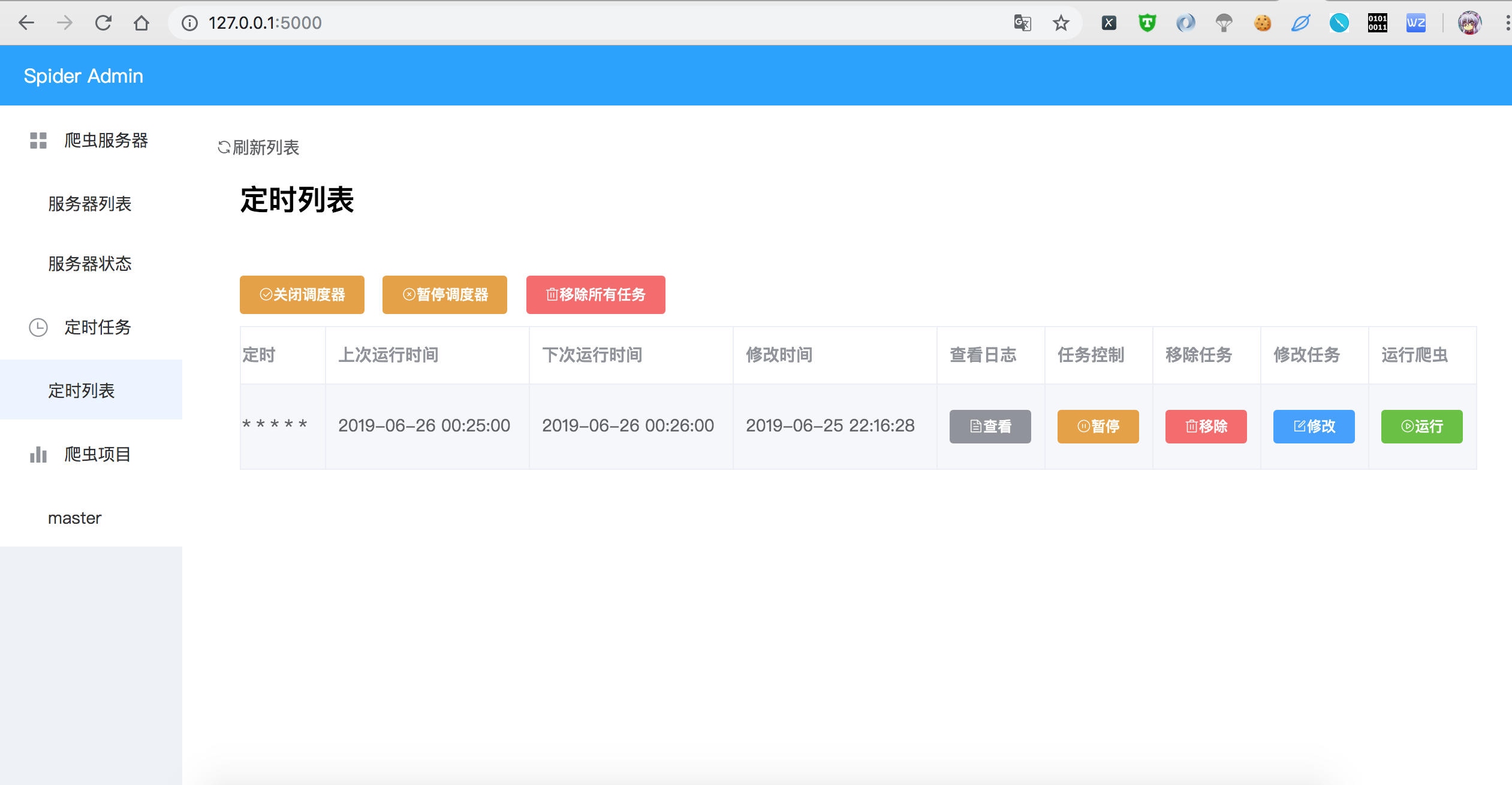
TODO
增加登录页面做权限校验增加定时设置的多样性增加定时随机运行
部署Scrapyd注意版本问题
- Scrapyd==1.2.0
- Scrapy==1.6.0
- Twisted==18.9.0
启用执行结果扩展
安装依赖
pip install PureMySQL
新建数据表
CREATE TABLE `log_spider` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`spider_name` varchar(50) DEFAULT NULL,
`item_count` int(11) DEFAULT NULL,
`duration` int(11) DEFAULT NULL,
`log_error` int(11) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='爬虫执行结果统计'
1、在scrapy项目中添加数据收集扩展文件
item_count_extension.py
# -*- coding: utf-8 -*-
import logging
from scrapy import signals
from puremysql import PureMysql
from datetime import datetime
class SpiderItemCountExtension(object):
# 设置为数据库链接url eg: mysql://root:123456@127.0.0.1:3306/mydata
ITEM_LOG_DATABASE_URL = None
# 设置数据表
ITEM_LOG_TABLE = "log_spider"
@classmethod
def from_crawler(cls, crawler):
ext = cls()
crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed)
return ext
def spider_closed(self, spider, reason):
stats = spider.crawler.stats.get_stats()
scraped_count = stats.get("item_scraped_count", 0)
dropped_count = stats.get("item_dropped_count", 0)
log_error = stats.get("log_count/ERROR", 0)
start_time = stats.get("start_time")
finish_time = stats.get("finish_time")
duration = (finish_time - start_time).seconds
count = scraped_count + dropped_count
logging.debug("*" * 50)
logging.debug("* {}".format(spider.name))
logging.debug("* item count: {}".format(count))
logging.debug("*" * 50)
item = {
"spider_name": spider.name,
"item_count": count,
"duration": duration,
"log_error": log_error,
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
mysql = PureMysql(db_url=self.ITEM_LOG_DATABASE_URL)
table = mysql.table(self.ITEM_LOG_TABLE)
table.insert(item)
mysql.close()
2、scrapy项目启用扩展 settings.py
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
"item_count_extension.SpiderItemCountExtension": 100
}
3、配置相同的db_url default_config.py
ITEM_LOG_DATABASE_URL = "mysql://root:123456@127.0.0.1:3306/mydata"
ITEM_LOG_TABLE = "log_spider"
更新日志
| 版本 | 日期 | 描述 |
|---|---|---|
| 0.0.17 | 2019-07-02 | 优化文件,优化随机调度,增加调度历史统计和可视化 |
| 0.0.20 | 2019-10-08 | 增加执行结果统计 |
| 0.0.29 | 2020-03-25 | 优化刷新显示,停留在当前页面下 |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
SpiderAdmin-0.0.32.tar.gz
(1.7 MB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
SpiderAdmin-0.0.32-py3-none-any.whl
(661.0 kB
view details)
File details
Details for the file SpiderAdmin-0.0.32.tar.gz.
File metadata
- Download URL: SpiderAdmin-0.0.32.tar.gz
- Upload date:
- Size: 1.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.0 pkginfo/1.5.0.1 requests/2.23.0 setuptools/42.0.2 requests-toolbelt/0.9.1 tqdm/4.40.0 CPython/3.7.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bbe9073ba9fde03934e36d41380cba0a1e77220c6b8a856dce2d14d567373534
|
|
| MD5 |
18974a9bd72009dd21be4b2c2e1a4886
|
|
| BLAKE2b-256 |
74d1da7c1225c9529dce20e296c63640e91ce3dfc4a10c3dec537b8eb7308d33
|
File details
Details for the file SpiderAdmin-0.0.32-py3-none-any.whl.
File metadata
- Download URL: SpiderAdmin-0.0.32-py3-none-any.whl
- Upload date:
- Size: 661.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.0 pkginfo/1.5.0.1 requests/2.23.0 setuptools/42.0.2 requests-toolbelt/0.9.1 tqdm/4.40.0 CPython/3.7.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
11eb635e396ad05d8a5a3bac683f21f00874b70272019f215e6781e36b1e5b7f
|
|
| MD5 |
e324bd1d0ed182886fccd2d34d95053a
|
|
| BLAKE2b-256 |
aaa994c125d37ebeb7eb07b15b66b4ee801ef23537dbdb0f8f7ba38d431ca611
|







