Finds the lemma of Uzbek words


Project description
Authors
Author1: Maksud Sharipov
Author2: Dasturbek
Lemma & Lemmatization
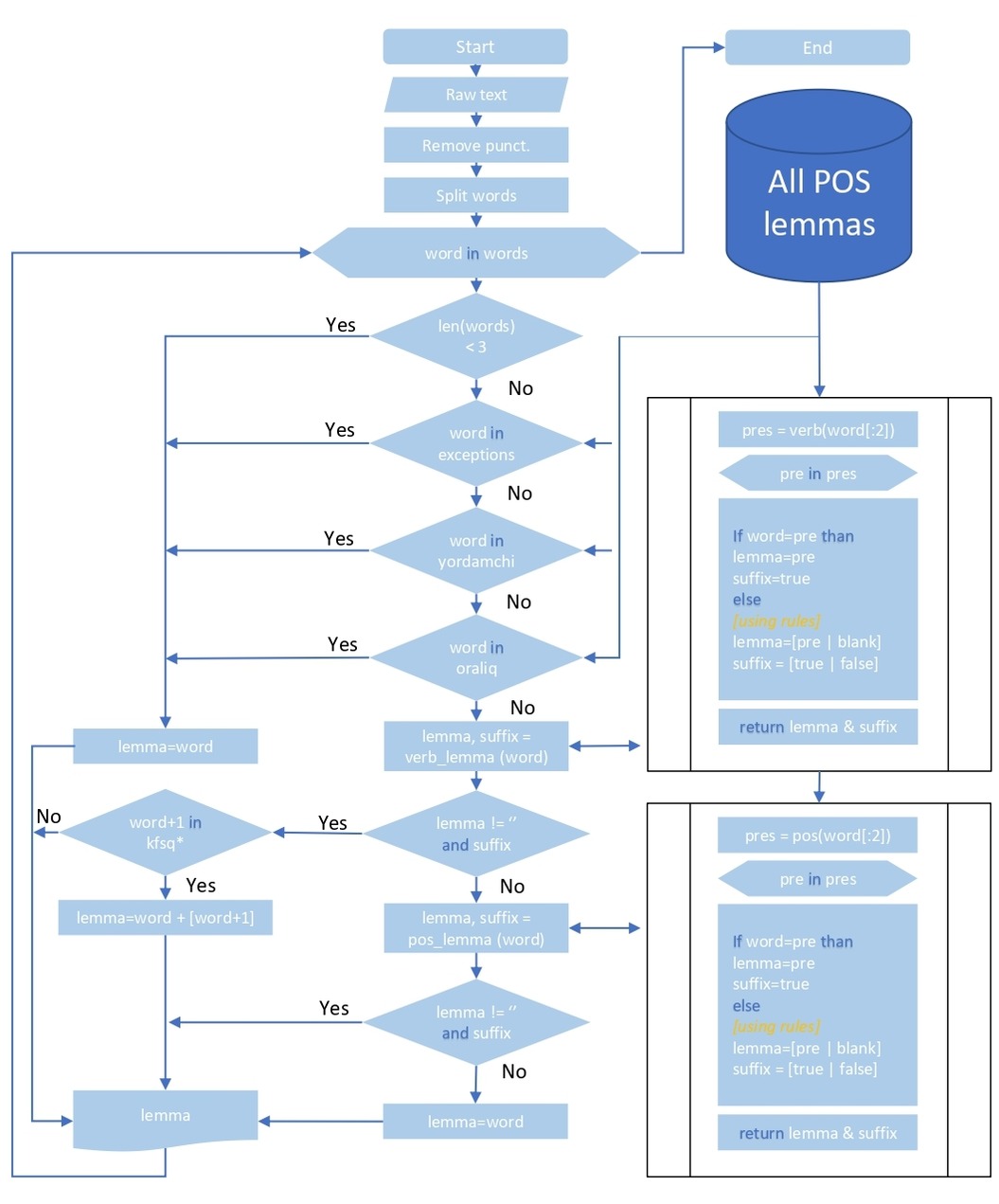
The package finds lemmas of Uzbek words based on the dictionary.
The process of finding a lemma is called lemmatization.
There are 4 different ways of lemmatization: rule, dictionary, model, hybrid.
It is dictionary-based lemmatization algorithm [program, package].
Install & Clone
pip install UzbekLemma
git clone https://github.com/ddasturbek/UzbekLemma.git
Usage
import UzbekLemma as UL
print(UL.lemmatize("kelganlar")) #kelmoq
The algorithm flowchart
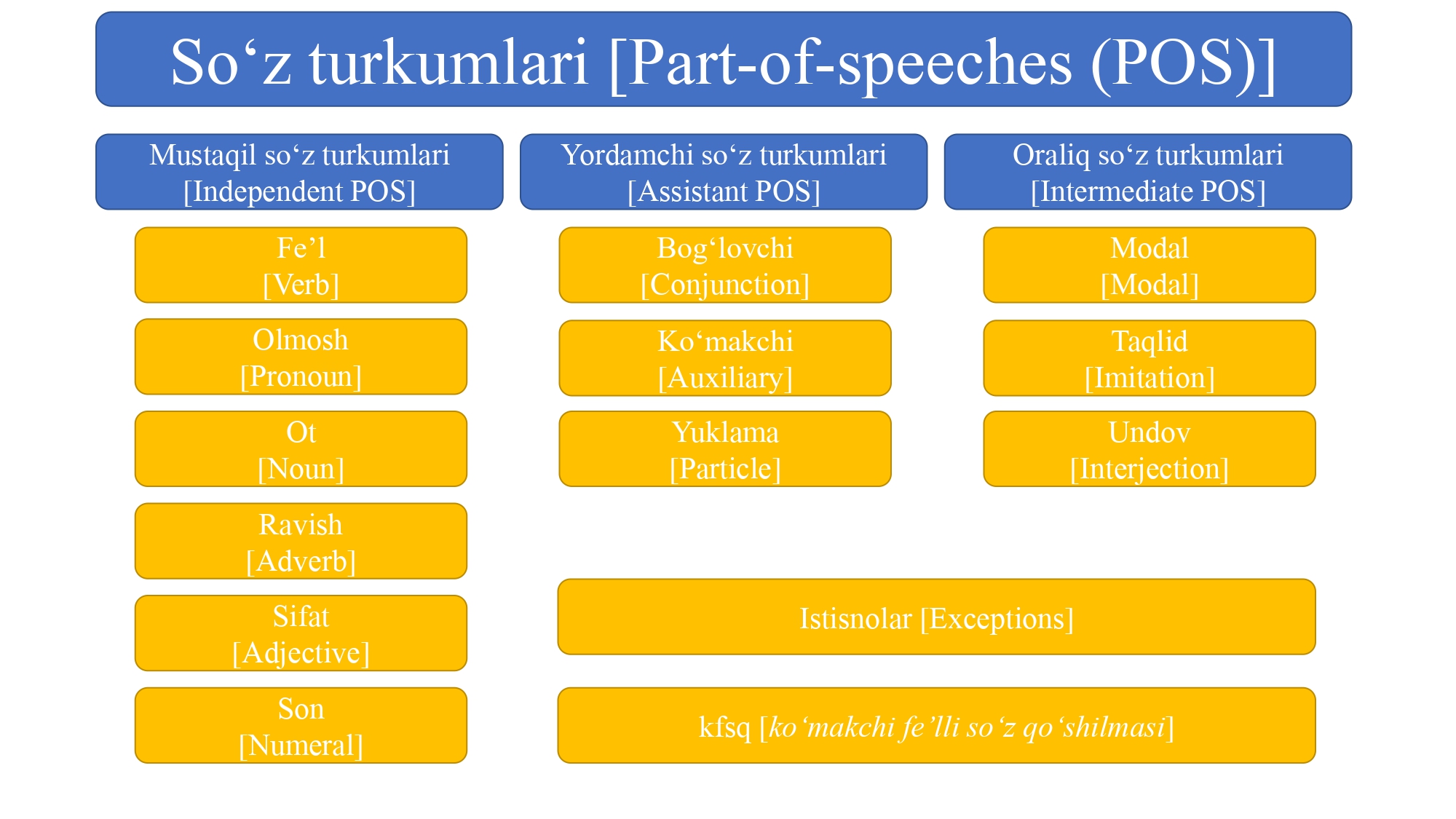
The dictionary structure
Scientific field

Patent

Some results of the program

Corpus & Results
We collected an equal number of texts from 23 different fields and stored them as a corpus.
We tested all the files (i.e. corpora) in the program and got these results.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file uzbeklemma-1.2.tar.gz.
File metadata
- Download URL: uzbeklemma-1.2.tar.gz
- Upload date:
- Size: 223.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
848a0035f38de098ecdba0ac9d81f4cc944d1a22a6eae511347e3cd9269acca3
|
|
| MD5 |
744779cba49a0795fadabcfc8cd6976b
|
|
| BLAKE2b-256 |
4c517a0ac09c1b78e2d43c60cb920b7b7381f742d9368a5899f3b17d966c04b4
|
File details
Details for the file UzbekLemma-1.2-py3-none-any.whl.
File metadata
- Download URL: UzbekLemma-1.2-py3-none-any.whl
- Upload date:
- Size: 222.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
957a48ab4c836d5e29a9b4ebdec513c8d7c1e7eb513beaa9f6e4a93fb2cda2b3
|
|
| MD5 |
9c568d03e199fe775c504fd4b7f1b909
|
|
| BLAKE2b-256 |
5f3a5d58ef3b9e58a3b92ea95a0ec874013b71979a07066b69483700faf6ef7a
|







