All-in-one CLI tool to download and extract content from URLs
Project description
⬇️ abx-dl
A simple all-in-one CLI tool to auto-detect and download everything available from a URL.
uvx abx-dl 'https://example.com'
✨ Ever wish you could yt-dlp, gallery-dl, wget, curl, puppeteer, etc. all in one command?
abx-dl is an all-in-one CLI tool for downloading URLs "by any means necessary".
It's useful for scraping, downloading, OSINT, digital preservation, and more.
abx-dl provides a simpler one-shot CLI interface to the ArchiveBox plugin ecosystem.
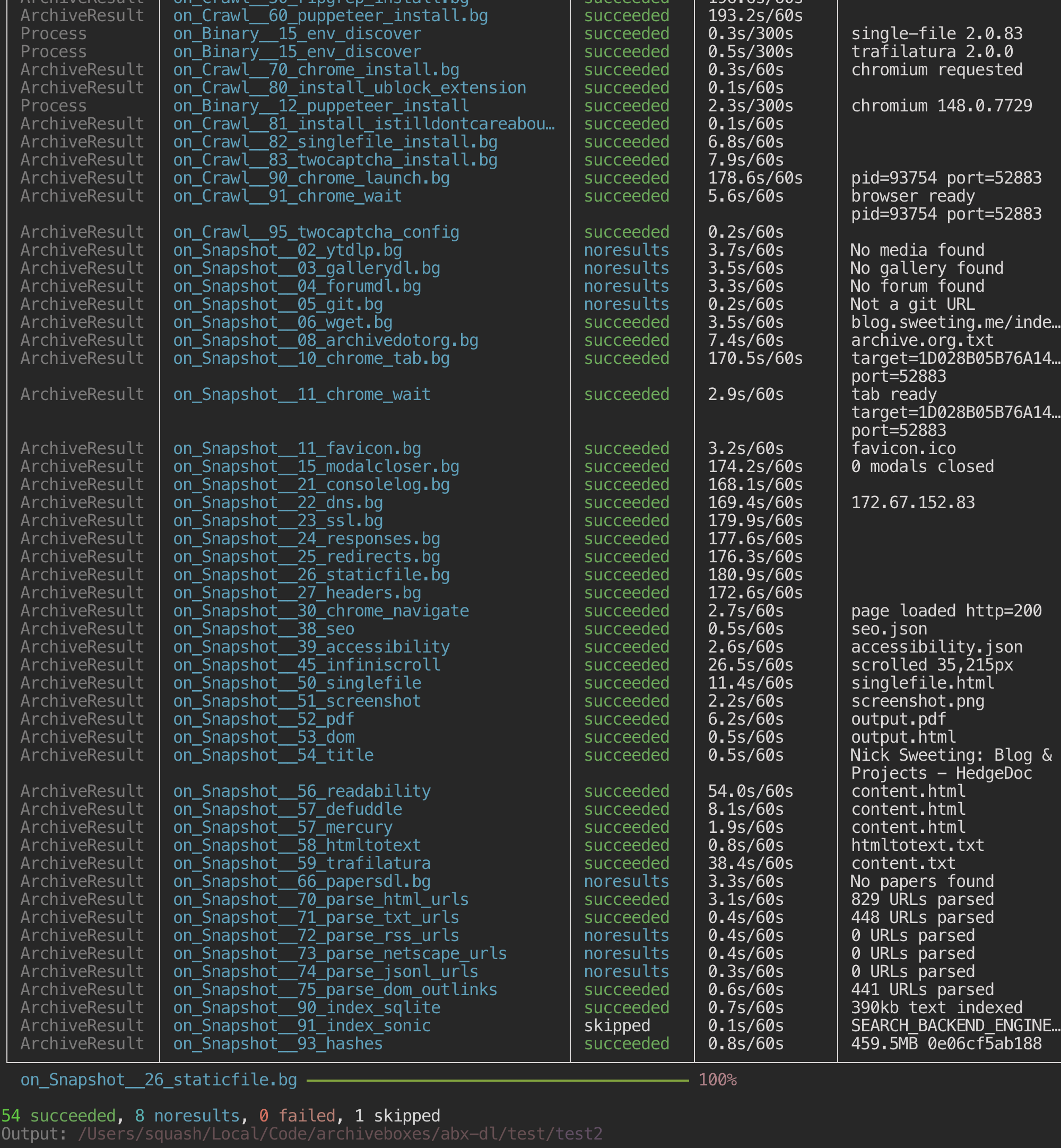
🍜 What does it save?
abx-dl --plugins=wget,title,screenshot,pdf,readability,git 'https://example.com'
abx-dl runs all plugins by default, or you can specify --plugins=... for specific methods:
- HTML, JS, CSS, images, etc. rendered with a headless browser
- title, favicon, headers, outlinks, and other metadata
- audio, video, subtitles, playlists, comments
- snapshot of the page as a PDF, screenshot, and Singlefile HTML
- article text,
gitsource code - and much more...
🧩 How does it work?
abx-dl uses the ABX Plugin Library (shared with ArchiveBox) to run a collection of downloading and scraping tools.
Plugins are loaded from the installed abx-plugins package (or from ABX_PLUGINS_DIR if you override it) and execute hooks in order:
- Crawl hooks run first (setup/install dependencies like Chrome)
- Snapshot hooks run per-URL to extract content
Each plugin can output:
- Files to its output directory
- JSONL records for status reporting
- Config updates that propagate to subsequent plugins
⚙️ Configuration
Configuration is handled via environment variables or persistent config file (~/.config/abx/config.env):
abx-dl config # show all config (global + per-plugin)
abx-dl config --get WGET_TIMEOUT # get a specific value
abx-dl config --set TIMEOUT=120 # set persistently (resolves aliases)
Output is grouped by section:
# GLOBAL
TIMEOUT=60
USER_AGENT="Mozilla/5.0 ..."
...
# plugins/wget
WGET_BINARY="wget"
WGET_TIMEOUT=60
...
# plugins/chrome
CHROME_BINARY="chromium"
...
Common options:
TIMEOUT=60- default timeout for hooksUSER_AGENT- default user agent string{PLUGIN}_BINARY- path to plugin's binary (e.g.WGET_BINARY,CHROME_BINARY){PLUGIN}_ENABLED=true/false- enable/disable specific plugins{PLUGIN}_TIMEOUT=120- per-plugin timeout overrides
Aliases are automatically resolved (e.g. --set USE_WGET=false saves as WGET_ENABLED=false).
One-off tuning is often easiest via env vars or CLI args:
TIMEOUT=120 USER_AGENT='Mozilla/5.0 (abx-dl smoke test)' abx-dl 'https://example.com'
CHROME_BINARY=/usr/bin/chromium LIB_DIR=./.abx/lib abx-dl --plugins=screenshot,pdf 'https://example.com'
abx-dl --output=./runs/example --plugins=wget,title --timeout=90 'https://example.com'
📦 Install
pip install abx-dl
abx-dl 'https://example.com'
# Or run the published CLI without installing it globally
uvx abx-dl 'https://example.com'
# Pre-install dependencies to avoid having to wait for them to install on first-run
uvx abx-dl install
🔠 Usage
# Default command - a bare URL archives with all enabled plugins:
abx-dl 'https://example.com'
# Limit work to a subset of plugins:
abx-dl --plugins=wget,title,screenshot,pdf 'https://example.com'
# Skip auto-installing missing dependencies (emit warnings instead):
abx-dl --no-install 'https://example.com'
# Specify output directory:
abx-dl --output=./downloads 'https://example.com'
# Set timeout:
abx-dl --timeout=120 'https://example.com'
Commands
abx-dl <url> # Download URL (default shorthand)
abx-dl plugins # Check + show info for all plugins
abx-dl plugins wget ytdlp git # Check + show info for specific plugins
abx-dl install wget ytdlp git # Pre-install plugin dependencies
abx-dl config # Show all config values
abx-dl config --get TIMEOUT # Get a specific config value
abx-dl config --set TIMEOUT=120 # Set a config value persistently
Installing Dependencies
Many plugins require external binaries (e.g., wget, chrome, yt-dlp, single-file).
By default, abx-dl lazily auto-installs missing dependencies as needed when you download a URL.
Use --no-install to skip plugins with missing dependencies instead. install runs crawl/install hooks ahead of time without downloading a snapshot:
# Auto-installs missing deps on-the-fly (default behavior)
abx-dl 'https://example.com'
# Skip plugins with missing deps, emit warnings instead
abx-dl --no-install 'https://example.com'
# Install dependencies for specific plugins only
abx-dl install wget singlefile ytdlp
# Check which dependencies are available/missing
abx-dl plugins
Dependencies are installed to ~/.config/abx/lib/{arch}/ using the appropriate package manager:
- pip packages →
~/.config/abx/lib/{arch}/pip/venv/ - npm packages →
~/.config/abx/lib/{arch}/npm/ - brew/apt packages → system locations
You can override the install location with LIB_DIR=/path/to/lib abx-dl install wget.
Output Structure
By default, abx-dl writes results into the current working directory. Each run creates an index.jsonl manifest plus one subdirectory per plugin that produced output. If you want to keep runs isolated, cd into a scratch directory first or pass --output=/path/to/run.
mkdir -p /tmp/abx-run && cd /tmp/abx-run
uvx --from abx-dl abx-dl --plugins=title,wget 'https://example.com'
./
├── index.jsonl # Snapshot metadata and results (JSONL format)
├── title/
│ └── title.txt
├── favicon/
│ └── favicon.ico
├── screenshot/
│ └── screenshot.png
├── pdf/
│ └── output.pdf
├── dom/
│ └── output.html
├── wget/
│ └── example.com/
│ └── index.html
├── singlefile/
│ └── output.html
└── ...
All Outputs
index.jsonl- snapshot metadata and plugin results (JSONL format, ArchiveBox-compatible)title/title.txt- page titlefavicon/favicon.ico- site faviconscreenshot/screenshot.png- full page screenshot (Chrome)pdf/output.pdf- page as PDF (Chrome)dom/output.html- rendered DOM (Chrome)wget/example.com/...- mirrored site filessinglefile/output.html- single-file HTML snapshot- ... and more via plugin library ...
Available Plugins
Generated from the abx-plugins marketplace docs. Each line lists the plugin and the kinds of outputs it can produce.
Snapshot / Extraction Plugins
ytdlp- downloads media plus sidecars: audio, video, images/thumbnails, subtitles (.srt,.vtt), JSON metadata, and text descriptions.gallerydl- downloads gallery/media sets as images, videos, JSON sidecars, text sidecars, and ZIP archives.forumdl- exports forum/thread archives as JSONL, WARC, and mailbox-style message archives.git- clones repository contents including text, binaries, images, audio, video, fonts, and other tracked files.wget- mirrors pages and requisites as HTML, WARC, images, CSS, JavaScript, fonts, audio, and video.archivedotorg- saves a Wayback Machine archive link as plain text.favicon- saves site favicons and touch icons as image files.modalcloser- setup helper only; no direct archive files.consolelog- saves browser console events as JSONL.dns- saves observed DNS activity as JSONL.ssl- saves TLS certificate/connection metadata as JSONL.responses- saves HTTP response metadata as JSONL and can record referenced text, images, audio, video, apps, and fonts.redirects- saves redirect chains as JSONL.staticfile- saves non-HTML direct file responses such as PDF, EPUB, images, audio, video, JSON, XML, CSV, ZIP, and generic binary files.headers- saves main-document HTTP headers as JSON.chrome- manages shared browser state and emits plain-text and JSON runtime metadata.seo- saves SEO metadata such as meta tags and Open Graph fields as JSON.accessibility- saves the browser accessibility tree as JSON.infiniscroll- page-expansion helper only; no direct archive files.claudechrome- saves Claude-computer-use interaction results as JSON plus PNG screenshots.singlefile- saves a full self-contained page snapshot as HTML.screenshot- saves rendered page screenshots as PNG.pdf- saves rendered pages as PDF.dom- saves fully rendered DOM output as HTML.title- saves the final page title as plain text.readability- extracts article HTML, plain text, and JSON metadata.defuddle- extracts cleaned article HTML, plain text, and JSON metadata.mercury- extracts article HTML, plain text, and JSON metadata.claudecodeextract- generates cleaned Markdown from other extractor outputs.htmltotext- converts archived HTML into plain text.trafilatura- extracts article content as plain text, Markdown, HTML, CSV, JSON, and XML/TEI.papersdl- downloads academic papers as PDF.parse_html_urls- emits discovered links from HTML as JSONL records.parse_txt_urls- emits discovered links from text files as JSONL records.parse_rss_urls- emits discovered feed entry URLs from RSS/Atom as JSONL records.parse_netscape_urls- emits discovered bookmark URLs from Netscape bookmark exports as JSONL records.parse_jsonl_urls- emits discovered bookmark URLs from JSONL exports as JSONL records.parse_dom_outlinks- emits crawlable rendered-DOM outlinks as JSONL records.search_backend_sqlite- writes a searchable SQLite FTS index database.search_backend_sonic- pushes content into Sonic search; no local archive files declared.claudecodecleanup- writes cleanup/deduplication results as plain text.hashes- writes file hash manifests as JSON.
Setup / Binary / Utility Plugins
npm- installs npm-provided binaries and exposes Node module paths; no direct archive files.claudecode- runs Claude Code over snapshots and emits JSON results.search_backend_ripgrep- search helper for archived files; no direct archive files.puppeteer- installs/manages Chromium via Puppeteer; no direct archive files.ublock- installs uBlock Origin for cleaner browser captures; no direct archive files.istilldontcareaboutcookies- installs cookie-banner suppression helpers; no direct archive files.twocaptcha- installs/configures CAPTCHA-solving browser helpers; no direct archive files.pip- installs Python-based binaries into a managed virtualenv; no direct archive files.brew- installs binaries with Homebrew; no direct archive files.apt- installs binaries with APT; no direct archive files.custom- installs binaries via a custom shell command; no direct archive files.env- discovers binaries already onPATH; no direct archive files.base- shared utilities/test support for other plugins; no direct archive files.media- shared namespace/helpers for media-related plugins; no direct archive files.
AI Skill
This repo includes an abx-dl skill for coding agents that need to run the standalone ArchiveBox extractor pipeline without a full ArchiveBox install.
- Skill source:
skills/abx-dl/SKILL.md - skills.sh page: https://skills.sh/archivebox/abx-dl/abx-dl
Architecture
abx-dl is built on these components:
abx_dl/plugins.py- Plugin discovery fromabx-pluginsorABX_PLUGINS_DIRabx_dl/executor.py- Hook execution engine with config propagationabx_dl/config.py- Environment variable configurationabx_dl/cli.py- Rich CLI with live progress display
For more advanced use with collections, parallel downloading, a Web UI + REST API, etc.
See: ArchiveBox/ArchiveBox
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file abx_dl-1.10.4.tar.gz.
File metadata
- Download URL: abx_dl-1.10.4.tar.gz
- Upload date:
- Size: 69.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.10.6 {"installer":{"name":"uv","version":"0.10.6","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ce213e83f43c124ce9e951cf4d57ca5fbb5c8f691e8c88fed1bfc83f406d1332
|
|
| MD5 |
6d035a1004bbcb45e72c3acff17dedc9
|
|
| BLAKE2b-256 |
bbed81c0e0c27a73761526f1b6041b55ca26e671fb4922882a06d1408c90091c
|
File details
Details for the file abx_dl-1.10.4-py3-none-any.whl.
File metadata
- Download URL: abx_dl-1.10.4-py3-none-any.whl
- Upload date:
- Size: 59.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.10.6 {"installer":{"name":"uv","version":"0.10.6","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5203b0dd2ebb4553f85e52cb6ced153263876bf1875b31b1e29da875b01601b1
|
|
| MD5 |
be1a7581f0dbf5fde9f3ee2b018c1bc8
|
|
| BLAKE2b-256 |
1b3bc543640b67e5fcecc45b6d22cf158df0f36cd8ae9f7056bac675b4822ea5
|







