Lightweight evaluation and observability toolkit for LLM agents
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
agenteval




A lightweight, framework-agnostic toolkit for evaluating and observing LLM agents.
The problem this solves
Standard unit tests don't work for agents. If you write assert result == "expected answer", you've already lost — because the same prompt can produce a different tool-calling sequence, different wording, or even a different conclusion on the next run. Flaky by design.
The correct mental model for agent reliability is statistical. Your agent doesn't "pass" or "fail" — it passes 80% of the time or 60% of the time. That's a meaningful number you can track, regress against, and improve. agenteval is built around that idea.
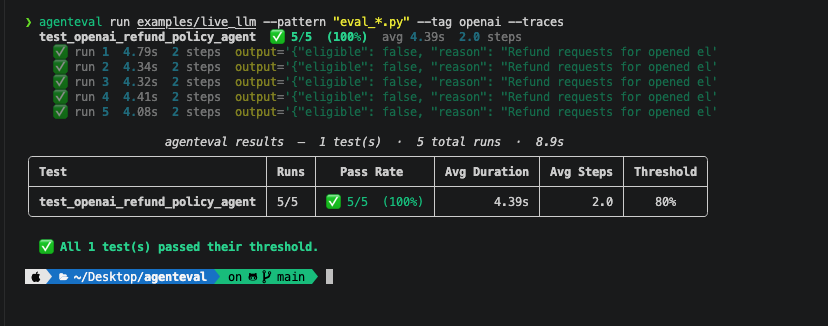
You define a test, tell it how many times to run (n=20) and what pass rate you'll accept (threshold=0.85), and get back a proper reliability score — along with per-run traces, timing, step counts, and failure breakdowns you can actually debug with.
test_find_restaurants 18/20 ✅ 90% avg 1.4s 2.8 steps
test_multi_step_reasoning 9/20 ⚠️ 45% avg 4.1s 6.3 steps
test_no_hallucination 15/20 ✅ 75% avg 2.0s 3.5 steps
Install
pip install agenteval-py
If you're using a specific framework, grab the extras:
pip install "agenteval-py[openai]" # OpenAI function calling
pip install "agenteval-py[anthropic]" # Anthropic tool use
pip install "agenteval-py[langchain]" # LangChain callback integration
pip install "agenteval-py[all]" # everything
Requires Python 3.11+.
The PyPI package name is agenteval-py, but the Python import and CLI
stay the same:
agenteval --help
import agenteval
Quick start

import agenteval
from agenteval import Tracer
# Your real agent and tools go here.
# This is a stand-in for demonstration.
async def web_search(query: str) -> str:
return f"search results for: {query}"
async def my_agent(prompt: str, search) -> str:
results = await search(query=prompt)
return f"Based on my research: {results}"
# This test runs 20 times. It must pass at least 85% of those runs.
@agenteval.test(n=20, threshold=0.85)
async def test_agent_uses_search(tracer: Tracer) -> None:
# Wrap your tools. The tracer records every call — name, args, result, timing.
search = tracer.wrap(web_search)
# Mark the run boundary. Duration is captured automatically.
async with tracer.run(input="What is agenteval?") as run:
result = await my_agent("What is agenteval?", search=search)
run.set_output(result)
# Assert on what happened. Failures are collected, not raised one-by-one.
(tracer.assert_that()
.called_tool("web_search") # did the agent actually search?
.completed_within_steps(5) # not wandering through 10 tool calls?
.completed_within_seconds(10.0) # not timing out?
.response_contains("research") # did it produce a real response?
.no_errors() # no unhandled exceptions?
.check()) # raise once with all failures listed
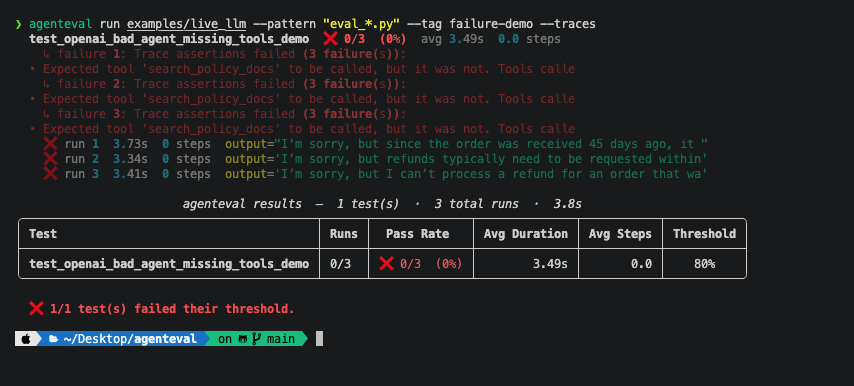
Run it with the CLI:
agenteval run tests/
Or directly in Python:
result = agenteval.run(test_agent_uses_search, n=10)
print(f"{result.n_passed}/{result.n_runs} passed ({result.pass_rate:.0%})")
# Drill into failures
for trace in result.failed_traces:
print(f"Run {trace.run_id}: {trace.error or trace.assertion_errors}")
How it works
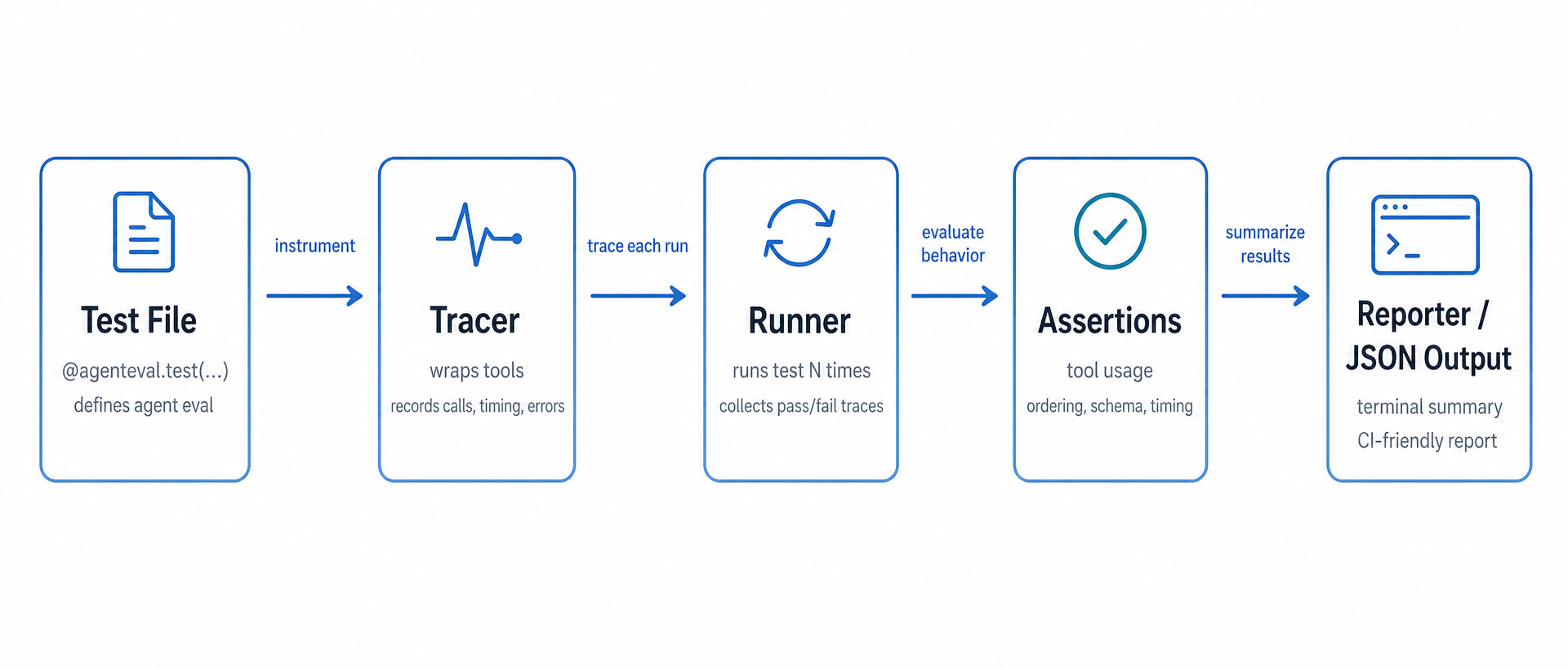
There are four moving parts:
Tracer — handed to your test function fresh each run. You wrap your tools with it (tracer.wrap(fn)), and it records every call: the function name, the arguments it received, the result it returned, how long it took, and whether it threw. Nothing in your actual agent code needs to change.
Runner — executes your test function N times concurrently (bounded by concurrency, default 4). It handles both sync and async test functions, catches any unhandled exceptions, and aggregates everything into a TestResult.
Assertions — a fluent chainable API (tracer.assert_that().called_tool(...).no_errors().check()) that collects failures instead of raising at the first one. When you call .check(), you get a single AssertionError listing every problem from that run.
Reporter — renders a color-coded summary table in the terminal with pass rates, average timing, step counts, and optional per-run trace details. Exports JSON for CI pipelines.
Writing tests
The test decorator
@agenteval.test(n=20, threshold=0.85, tags=["search", "integration"])
async def test_my_agent(tracer: Tracer) -> None:
...
n— how many times to run this test (default: 20)threshold— minimum pass rate to consider this test passing (default: 0.8)tags— optional labels for filtering withagenteval run --tag
Sync test functions work too — agenteval wraps them automatically:
@agenteval.test(n=10)
def test_sync_agent(tracer: Tracer) -> None:
tool = tracer.wrap(my_sync_tool)
with tracer.run(input="hello") as run:
result = my_sync_agent("hello", tool=tool)
run.set_output(result)
tracer.assert_that().no_errors().check()
Wrapping tools
# Method form — returns a wrapped version of the function
search = tracer.wrap(my_search_fn)
search = tracer.wrap(my_search_fn, name="web_search") # custom name in traces
# Decorator form — useful when defining tools inline
@tracer.tool
def calculator(x: int, y: int) -> int:
return x + y
@tracer.tool(name="math")
async def calculator(x: int, y: int) -> int:
return x + y
Both sync and async functions are supported. The wrapper is transparent — it preserves return values and re-raises exceptions exactly as before, just with recording on the side.
Recording the run
async with tracer.run(input="user prompt here") as run:
result = await my_agent("user prompt here")
run.set_output(result)
run.set_token_usage({"input_tokens": 400, "output_tokens": 120})
run.add_metadata(model="gpt-4o", temperature=0.7)
The context manager captures start/end time automatically. Any unhandled exception inside the block is recorded as trace.error (AssertionErrors from .check() are handled separately by the runner).
Assertions
All assertion methods return self so you can chain them. Failures are collected — .check() raises once at the end listing every issue, not just the first one.
tracer.assert_that()
# Tool usage
.called_tool("search") # called at least once
.never_called_tool("delete_record") # must never be called
.tool_call_count("search", min=1, max=3) # call count range
.tool_called_before("search", "summarize") # ordering check
.tool_called_with_args("search", {"q": "python"}) # argument subset match
.tool_called_with_args("search", {"q": "python"}, match="exact") # exact match
# Performance
.completed_within_steps(8) # at most 8 tool calls
.completed_within_seconds(15.0) # wall-clock time limit
# Output quality
.response_contains("Python") # substring match
.response_contains("python", case_sensitive=False) # case-insensitive
.response_matches_schema(MyPydanticModel) # structured output validation
# Errors
.no_errors() # no unhandled exceptions
# Custom escape hatch
.custom(lambda t: len(t.tool_calls) >= 2)
.custom(lambda t: "gpt-4" in str(t.metadata), message="wrong model used")
.check() # raise AssertionError if anything above failed
You can also inspect without raising:
aset = tracer.assert_that().called_tool("search").no_errors()
if not aset.passed:
print(aset.failures) # list[str] — all failure messages
Framework adapters
OpenAI
pip install "agenteval-py[openai]"
from agenteval.adapters.openai_adapter import wrap_tools, extract_token_usage
import json
@agenteval.test(n=15, threshold=0.8)
async def test_openai_agent(tracer: Tracer) -> None:
tools = wrap_tools({"search": search_fn, "calculator": calc_fn}, tracer)
async with tracer.run(input=prompt) as run:
messages = [{"role": "user", "content": prompt}]
while True:
response = await client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=openai_tool_schemas,
)
run.set_token_usage(extract_token_usage(response))
choice = response.choices[0]
if choice.finish_reason == "tool_calls":
tool_results = []
for tc in choice.message.tool_calls:
args = json.loads(tc.function.arguments)
result = await tools[tc.function.name](**args)
tool_results.append({
"role": "tool",
"tool_call_id": tc.id,
"content": str(result),
})
messages.append(choice.message)
messages.extend(tool_results)
else:
run.set_output(choice.message.content)
break
tracer.assert_that().called_tool("search").no_errors().check()
Anthropic
pip install "agenteval-py[anthropic]"
from agenteval.adapters.anthropic_adapter import wrap_tools, extract_token_usage
@agenteval.test(n=15, threshold=0.8)
async def test_anthropic_agent(tracer: Tracer) -> None:
tools = wrap_tools({"web_search": search_fn}, tracer)
async with tracer.run(input=prompt) as run:
messages = [{"role": "user", "content": prompt}]
while True:
response = await client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=anthropic_tool_schemas,
messages=messages,
)
run.set_token_usage(extract_token_usage(response))
if response.stop_reason == "tool_use":
tool_results = []
for block in response.content:
if block.type == "tool_use":
result = await tools[block.name](**block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(result),
})
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
else:
text = next(b.text for b in response.content if b.type == "text")
run.set_output(text)
break
tracer.assert_that().called_tool("web_search").no_errors().check()
LangChain
pip install "agenteval-py[langchain]"
from agenteval.adapters.langchain_adapter import AgentEvalCallbackHandler
@agenteval.test(n=10, threshold=0.75)
async def test_langchain_agent(tracer: Tracer) -> None:
handler = AgentEvalCallbackHandler()
# The handler auto-connects to the active tracer via ContextVar.
# Multiple concurrent runs each get their own isolated tracer — no locking needed.
async with tracer.run(input=prompt) as run:
result = await agent.ainvoke(
{"input": prompt},
config={"callbacks": [handler]},
)
run.set_output(result.get("output", ""))
tracer.assert_that().called_tool("my_tool").no_errors().check()
CLI reference
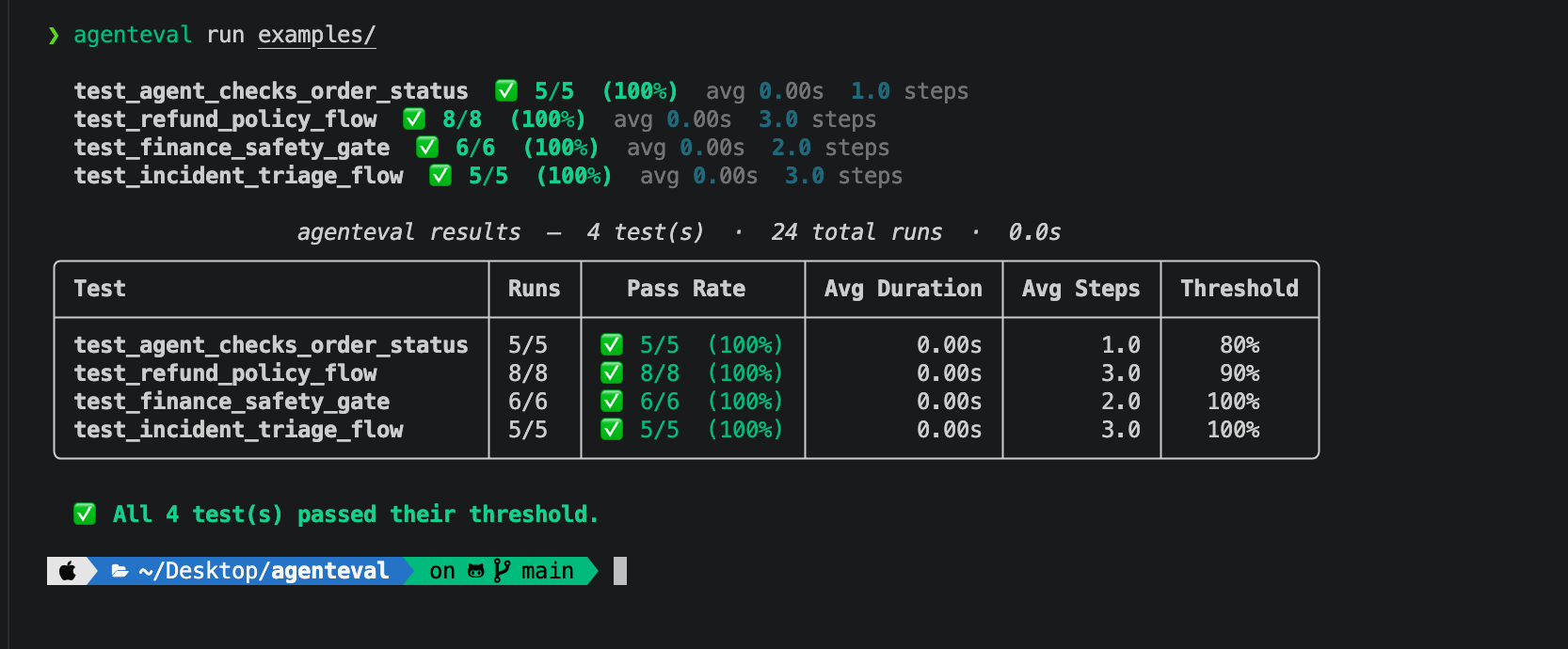
# Discover and run all test_*.py files
agenteval run tests/
# Adjust runs and threshold for this session
agenteval run tests/ --n 10 --threshold 0.9
# Filter by tag
agenteval run tests/ --tag integration
# Show per-trace details (useful when debugging failures)
agenteval run tests/ --traces
# Save a JSON report for CI or later inspection
agenteval run tests/ --output report.json
# Pretty-print a saved report
agenteval report report.json
agenteval report report.json --traces
Exit codes: 0 if all tests met their threshold, 1 if any failed, 2 on error (missing file, import failure, etc.). This makes it straightforward to gate on in CI/CD pipelines.
| Flag | Description | Default |
|---|---|---|
--n |
Override run count for all tests | test's own n |
--threshold |
Override threshold for all tests | test's own threshold |
--concurrency |
Max concurrent agent runs | 4 |
--tag |
Filter tests by tag (repeatable) | all tests |
--pattern |
File glob for test discovery | test_*.py |
--output |
Write JSON report to a file | none |
--traces |
Show per-run trace details | off |
--failures / --no-failures |
Show failure reasons | on |
Data models
AgentTrace(
run_id, # unique UUID for this run
input, # what was passed to the agent
output, # what the agent returned
tool_calls, # list[ToolCall] — every recorded tool invocation
duration_seconds, # wall-clock time for the entire agent run
total_steps, # number of tool calls (or manual override via run.set_steps())
token_usage, # dict from run.set_token_usage() — None if not provided
error, # string if the agent raised an unhandled exception
assertion_errors, # list of failure messages from .check()
passed, # True only if error is None and assertion_errors is empty
metadata, # dict from run.add_metadata()
)
TestResult(
test_name, n_runs, n_passed,
pass_rate, # n_passed / n_runs
threshold,
traces, # all AgentTrace objects for this test
passed_traces, # computed — only traces where passed=True
failed_traces, # computed — only traces where passed=False
avg_duration, # mean duration across all runs
avg_steps, # mean step count across all runs
met_threshold, # True if pass_rate >= threshold
tags,
)
SuiteResult(
results, # list[TestResult], one per test function
start_time, end_time,
total_tests, passed_tests, failed_tests,
all_passed,
duration_seconds,
)
Using in CI
The exit code makes this drop-in ready. A GitHub Actions example:
- name: Run agent evals
run: agenteval run tests/ --n 5 --output eval-report.json
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
- name: Upload eval report
uses: actions/upload-artifact@v4
with:
name: eval-report
path: eval-report.json
if: always()
Keep n lower in CI to control API costs — 5 or 10 runs is usually enough to catch regressions.
Project structure
agenteval/
├── src/agenteval/
│ ├── __init__.py # public API surface
│ ├── tracer.py # Tracer + RunContext — the core recording layer
│ ├── assertions.py # AssertionSet — fluent assertion API
│ ├── runner.py # runs a test function N times concurrently
│ ├── registry.py # @agenteval.test decorator + global test registry
│ ├── suite.py # discovers and runs test files
│ ├── reporter.py # Rich terminal output + JSON export
│ ├── cli.py # Typer CLI (agenteval run / agenteval report)
│ ├── models.py # AgentTrace, TestResult, SuiteResult, ToolCall
│ ├── exceptions.py # TracerError
│ └── adapters/
│ ├── openai_adapter.py # wrap_tools + extract_token_usage for OpenAI
│ ├── anthropic_adapter.py # same for Anthropic
│ └── langchain_adapter.py # AgentEvalCallbackHandler for LangChain
├── tests/ # full test suite for the framework itself
├── docs/ # detailed documentation per topic
│ ├── quickstart.md
│ ├── tracer.md
│ ├── assertions.md
│ ├── adapters.md
│ └── cli.md
└── pyproject.toml
Development setup
git clone https://github.com/awesome-pro/agenteval
cd agenteval
# Install in editable mode with all dev dependencies
pip install -e ".[dev]"
# Run the full test suite (no API keys needed)
pytest tests/ -v
# Lint and test
ruff check src/ tests/ --select F,I
pytest tests/ -v
The test suite runs completely offline — all agent runs inside the tests use mock functions. Three Python versions are tested in CI (3.11, 3.12, 3.13).
Contributing
See CONTRIBUTING.md for how to get set up, the branching strategy, and what to include in a pull request.
License
MIT — see LICENSE for details.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file agenteval_py-0.1.1.tar.gz.
File metadata
- Download URL: agenteval_py-0.1.1.tar.gz
- Upload date:
- Size: 3.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
51284a69b2ecc61808e7bbc71c7a71c94944b9f476f1b2b37831e447dc86bf35
|
|
| MD5 |
22a68a19db94bad4358bc32bc9206077
|
|
| BLAKE2b-256 |
5b4cedcab9f44060da63cdc38c84f1d0b7400e47ae843761ebebf5944f952874
|
Provenance
The following attestation bundles were made for agenteval_py-0.1.1.tar.gz:
Publisher:
publish.yml on awesome-pro/agenteval
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
agenteval_py-0.1.1.tar.gz -
Subject digest:
51284a69b2ecc61808e7bbc71c7a71c94944b9f476f1b2b37831e447dc86bf35 - Sigstore transparency entry: 1746762302
- Sigstore integration time:
-
Permalink:
awesome-pro/agenteval@3cbe83b244f62f5ae08b734a678f26e3c38063e9 -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/awesome-pro
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@3cbe83b244f62f5ae08b734a678f26e3c38063e9 -
Trigger Event:
release
-
Statement type:
File details
Details for the file agenteval_py-0.1.1-py3-none-any.whl.
File metadata
- Download URL: agenteval_py-0.1.1-py3-none-any.whl
- Upload date:
- Size: 29.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
37e3ad8f234daf1ac0adec711c9bd10ef9326c48b9062d18067c10644520ee46
|
|
| MD5 |
a60b36be046d5cfec5b8b01fea1fa6b3
|
|
| BLAKE2b-256 |
b7d4f4831ccd79a51e44c926721cc7b397b7af3d1d2868d2f0023fabfd011fbb
|
Provenance
The following attestation bundles were made for agenteval_py-0.1.1-py3-none-any.whl:
Publisher:
publish.yml on awesome-pro/agenteval
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
agenteval_py-0.1.1-py3-none-any.whl -
Subject digest:
37e3ad8f234daf1ac0adec711c9bd10ef9326c48b9062d18067c10644520ee46 - Sigstore transparency entry: 1746762426
- Sigstore integration time:
-
Permalink:
awesome-pro/agenteval@3cbe83b244f62f5ae08b734a678f26e3c38063e9 -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/awesome-pro
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@3cbe83b244f62f5ae08b734a678f26e3c38063e9 -
Trigger Event:
release
-
Statement type:







