Diagnostic toolkit for black-box evaluation of automated peer-review systems.

Project description
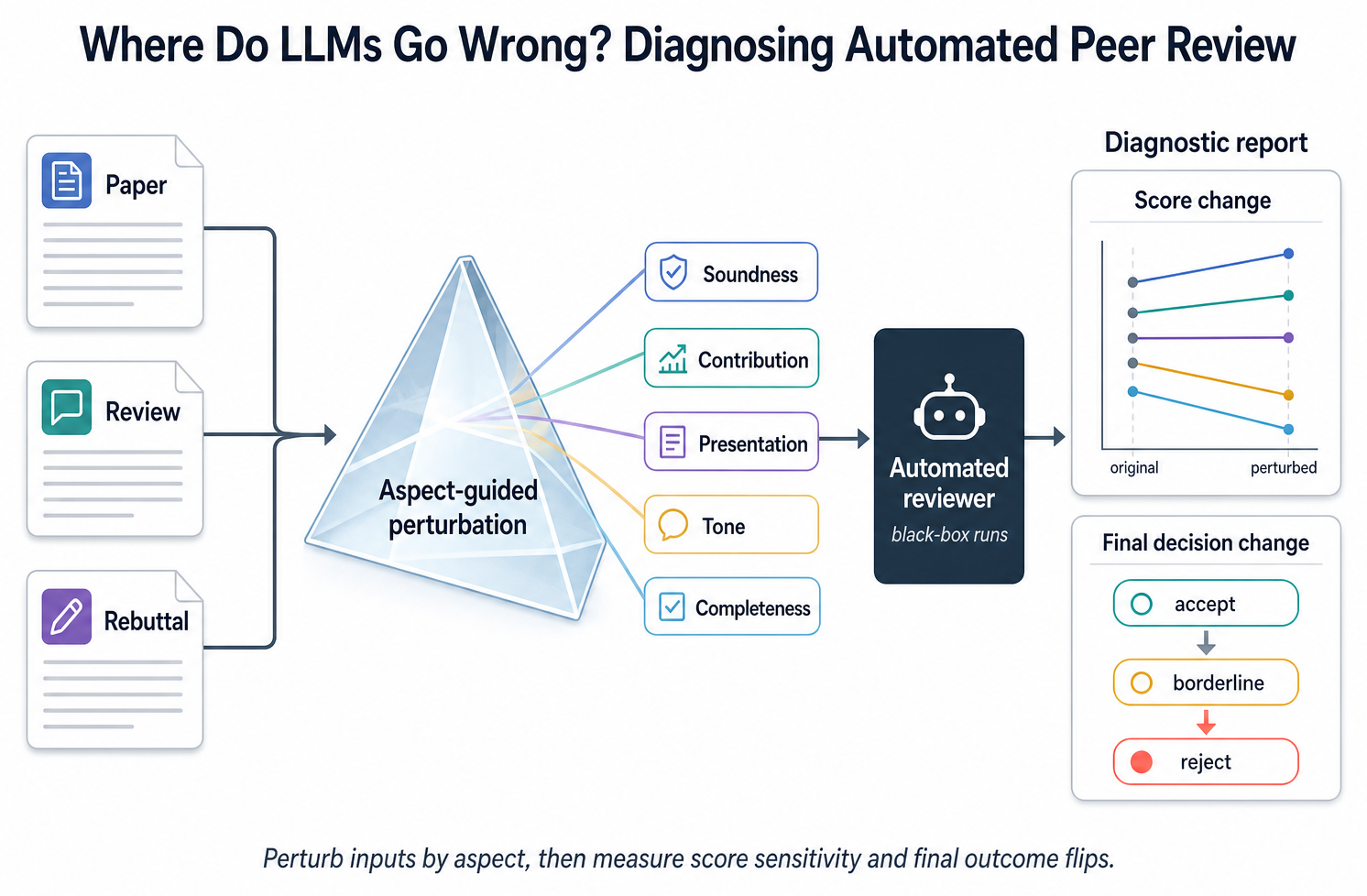
Where Do LLMs Go Wrong? Diagnosing Automated Peer Review





Official repository for the CIKM 2025 paper “Where Do LLMs Go Wrong? Diagnosing Automated Peer Review via Aspect-Guided Multi-Level Perturbation.”
Use this repo to evaluate automated peer-review systems on paired original/perturbed inputs and generate aspect-level diagnostic reports. The data lives on Hugging Face; the installable reporting CLI lives on PyPI.
Start fast
Install the CLI and run the bundled demo. No dataset, API key, GPU, or model download is needed.
python -m pip install ai-reviewer-diagnostics
ai-reviewer-diagnostics --demo --output-md outputs/demo_diagnostic_report.md
Expected output:
Compared 1 condition pair(s).
Wrote outputs/demo_diagnostic_report.md
For a repo checkout:
git clone https://github.com/PKU-ONELab/where-do-llms-go-wrong
cd where-do-llms-go-wrong
make quickstart
make demo-report
What is included
| Need | Use |
|---|---|
| Diagnostic report CLI | ai-reviewer-diagnostics / ai-reviewer-report |
| Main paired perturbation data | HF dataset → data/content_pairs/*.jsonl |
| Released score artifacts | HF dataset → data/annotation_scores/*.jsonl |
| Prompt templates | prompts/ |
| API / local inference wrappers | scripts/ |
| Paper-analysis scripts | analysis/ |
| Reproduction notes | docs/REPRODUCIBILITY.md |
Use the dataset
The primary dataset is before/after perturbation pairs:
from datasets import load_dataset
pairs = load_dataset("leejamesssss/ai-reviewer-diagnostic-data", split="train")
print(pairs[0].keys()) # id, source, aspect, content_before, content_after
Download the full HF repo when you need manifests or score artifacts:
hf download leejamesssss/ai-reviewer-diagnostic-data --repo-type dataset --local-dir ai-reviewer-diagnostic-data
python scripts/summarize_release_data.py --data-dir ai-reviewer-diagnostic-data/data
content_pairs/ is the canonical benchmark surface. annotation_scores/ is for reproducing or auditing the paper’s released scoring outputs. The duplicated perturbed-only view is intentionally excluded because content_pairs.content_after already contains it.
Evaluate your own review system
Export baseline and perturbed outputs as JSONL with shared id values and any score/decision fields:
{"id":"paper_001","overall_score":8,"soundness_score":4,"final_decision":"Accept as Poster"}
Then run:
ai-reviewer-diagnostics --baseline outputs/my_system_baseline.jsonl --perturbed outputs/my_system_soundness_perturbed.jsonl --condition paper/soundness --output-md reports/my_system_soundness_report.md --output-json reports/my_system_soundness_report.json
Directory mode works for released score files:
ai-reviewer-diagnostics --scores-dir ai-reviewer-diagnostic-data/data/annotation_scores --output-md reports/released_scores_report.md
The report summarizes score deltas, decision-change rates, and top decision transitions. See docs/INTEGRATIONS.md for schemas and custom fields.
Development commands
uv sync # default runtime deps
uv sync --extra analysis # analysis deps
uv sync --extra vllm # optional local GPU inference deps
uv run make smoke-test # API-free checks
make clean # remove generated outputs
Inference wrappers:
python scripts/run_openrouter.py --input examples/example.json --output outputs/openrouter.jsonl --model <model> --api-key-env OPENROUTER_API_KEY
python scripts/run_gemini.py --input examples/example.json --output outputs/gemini.jsonl --model gemini-2.0-flash
python scripts/run_vllm.py --input examples/example.json --output outputs/vllm.jsonl --model-path <hf-or-local-model>
Repository map
ai_reviewer_diagnostics/ # pip package and diagnostic report CLI
scripts/ # inference, preprocessing, quickstart, data-summary CLIs
analysis/ # scripts for released score artifacts
examples/ # tiny fixtures for demos/tests
prompts/ # prompt templates
data/README.md # pointer to HF dataset
docs/ # data, integrations, reproducibility
paper/README.md # DOI / citation pointer
Citation
@inproceedings{li2025where,
title = {Where Do LLMs Go Wrong? Diagnosing Automated Peer Review via Aspect-Guided Multi-Level Perturbation},
author = {Li, Jiatao and Li, Yanheng and Hu, Xinyu and Gao, Mingqi and Wan, Xiaojun},
booktitle = {Proceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM '25)},
year = {2025},
publisher = {ACM},
doi = {10.1145/3746252.3761274},
url = {https://doi.org/10.1145/3746252.3761274}
}
Docs: GETTING_STARTED, DATA, REPRODUCIBILITY, INTEGRATIONS, CONTRIBUTING.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ai_reviewer_diagnostics-0.1.4.tar.gz.
File metadata
- Download URL: ai_reviewer_diagnostics-0.1.4.tar.gz
- Upload date:
- Size: 12.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
19170f0dc76444e4d4e200b97a93e6cda09e2046afcae98d17ba8366dc3bbd80
|
|
| MD5 |
ad101ea9fb5b817c9e65baca64aa92f7
|
|
| BLAKE2b-256 |
4af6a108fbd53bda80ddb4edf87c6f4f06ef52de83ee84739fd77616144979a0
|
File details
Details for the file ai_reviewer_diagnostics-0.1.4-py3-none-any.whl.
File metadata
- Download URL: ai_reviewer_diagnostics-0.1.4-py3-none-any.whl
- Upload date:
- Size: 11.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
63fd520485da9370443a6667e3375cc3205dadc457fba9cf5d78b8d027dd3a33
|
|
| MD5 |
9d2819a72ec0cbe0ec57b191a90573dc
|
|
| BLAKE2b-256 |
3a295163cda814d066b3587a35d25f8c71d323c21941af2065f3f77ae7e49cc1
|







