AlayaLite Python extension module

Project description

AlayaLite – A Fast, Flexible Vector Database for Everyone.
Seamless Knowledge, Smarter Outcomes.

Features
- High Performance: Modern vector techniques integrated into a well-designed architecture.
- Elastic Scalability: Seamlessly scale across multiple threads, which is optimized by C++20 coroutines.
- Adaptive Flexibility: Easy customization for quantization methods, metrics, and data types.
- Two index paths in one package: an in-memory graph + RaBitQ path for low-latency retrieval, and the LASER on-disk Quantized Graph index for billion-scale workloads that do not fit in RAM.
- Ease of Use: Intuitive APIs in Python.
Documentation
Quick Start
Get started with just one command!
pip install alayalite # with pip
# or
uv pip install alayalite # with uv (standalone)
uv add alayalite # in a uv-managed project
In-memory index: quick start
import numpy as np
from alayalite import Client
client = Client()
index = client.create_index("ann")
vectors = np.random.rand(1000, 128).astype(np.float32)
queries = np.random.rand(10, 128).astype(np.float32)
gt = calc_gt(vectors, queries, 10)
# Insert vectors to the index
index.fit(vectors)
# Perform batch search for the queries and retrieve top-10 results
result = index.batch_search(queries, 10)
# Compute the recall based on the search results and ground truth
recall = calc_recall(result, gt)
print(recall)
Hybrid search in Collection: quick start
Use Collection when you want ANN results together with document IDs,
documents, and metadata filters.
collection = client.create_collection("docs", indexed_fields=["category"])
collection.insert([
("doc-1", "Vector database overview", vectors[0], {"category": "database"}),
("doc-2", "Cooking notes", vectors[1], {"category": "life"}),
])
result = collection.hybrid_query(
vectors=[vectors[0]],
limit=1,
metadata_filter={"category": "database"},
ef_search=10,
)
print(result["id"][0])
LASER on-disk index: quick start
For datasets that exceed RAM, the LASER on-disk Quantized Graph index keeps
hot data on SSD and only the search-time working set in memory. Vectors must be
float32 with raw_dim >= 128; L2 is the only supported metric in v1.
LASER is available on Linux x86_64 (libaio backend, default), macOS (thread-pool backend), and Windows x64 (IOCP backend). Platform notes:
- Linux x86_64 builds need
libaioheaders, for examplesudo apt-get install libaio-devon Debian/Ubuntu. - macOS builds need OpenMP from Homebrew:
brew install libomp. - Windows x64 builds should run from a Visual Studio 2022 developer shell with the Desktop development with C++ workload installed; MSVC provides the OpenMP runtime used by LASER.
See LASER.md for build flags, tuning notes, and the TOML-driven CLI.
LASER Index.fit pulls in PCA / k-means / progress-bar helpers (scikit-learn,
faiss-cpu, tqdm), which are declared as the [laser] extra so the base
install stays lean. Install them on top of the base wheel:
pip install "alayalite[laser]"
# or, with uv:
uv pip install "alayalite[laser]"
import shutil
import time
import numpy as np
from sklearn.datasets import make_blobs
from alayalite.laser import BuildParams, Index
from alayalite.utils import calc_gt, calc_recall
# Smoke-scale demo (~10-20s end-to-end on a modern laptop). Tuning details,
# paper-aligned configs and the on-disk layout are covered in the LASER guide above.
output_dir = "/tmp/alaya_laser"
shutil.rmtree(output_dir, ignore_errors=True)
# Synthetic GMM clusters so ANN has structure to find; uniform-random vectors
# in 768-D would collapse recall (high-D distance concentration).
pts, _ = make_blobs(n_samples=10_100, n_features=768, centers=64,
cluster_std=0.35, random_state=42)
vectors = pts[:10_000].astype(np.float32)
queries = pts[10_000:].astype(np.float32)
gt = calc_gt(vectors, queries, 10)
idx = Index.fit(
vectors,
output_dir=output_dir,
name="demo",
build_params=BuildParams(main_dim=256, ep_num=20),
seed=42,
num_threads=0,
dram_budget_gb=2.0,
)
idx.set_params(ef_search=200, num_threads=1, beam_width=16)
idx.batch_search(queries, 10) # warmup
t0 = time.perf_counter()
ids = idx.batch_search(queries, 10)
elapsed = time.perf_counter() - t0
print(f"Recall@10: {calc_recall(ids, gt):.3f}")
print(f"QPS: {len(queries) / elapsed:.1f} ({len(queries)} queries in {elapsed*1000:.1f} ms)")
# Reopen later without rebuilding:
# idx = Index.from_prefix("/tmp/alaya_laser/demo", dram_budget_gb=2.0)
LASER requires a LASER-enabled build. See the LASER Guide for platform requirements and build options.
Benchmark
AlayaLite ships two complementary index paths. The benchmarks below cover both.
In-memory index vs. ANN-Benchmarks
We evaluate the in-memory path against other vector database systems using
ANN-Benchmark (compile locally and
open -march=native in your CMakeLists.txt to reproduce the results).
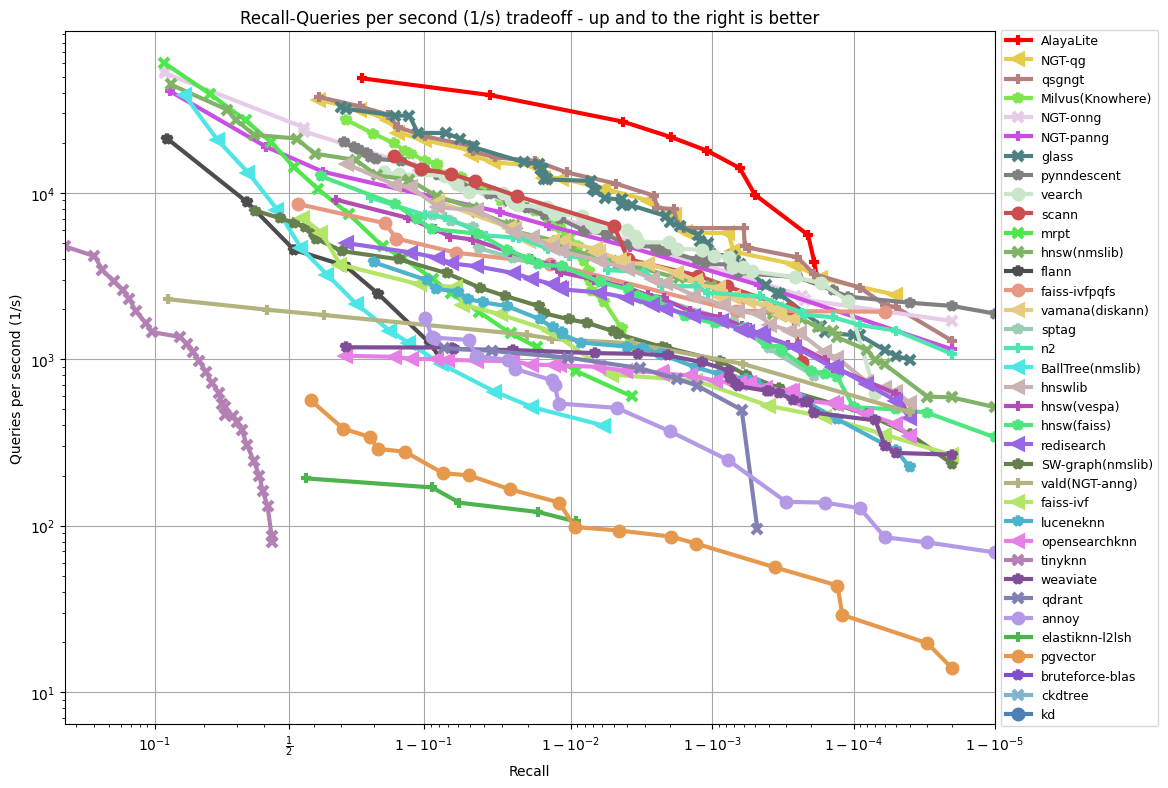 |
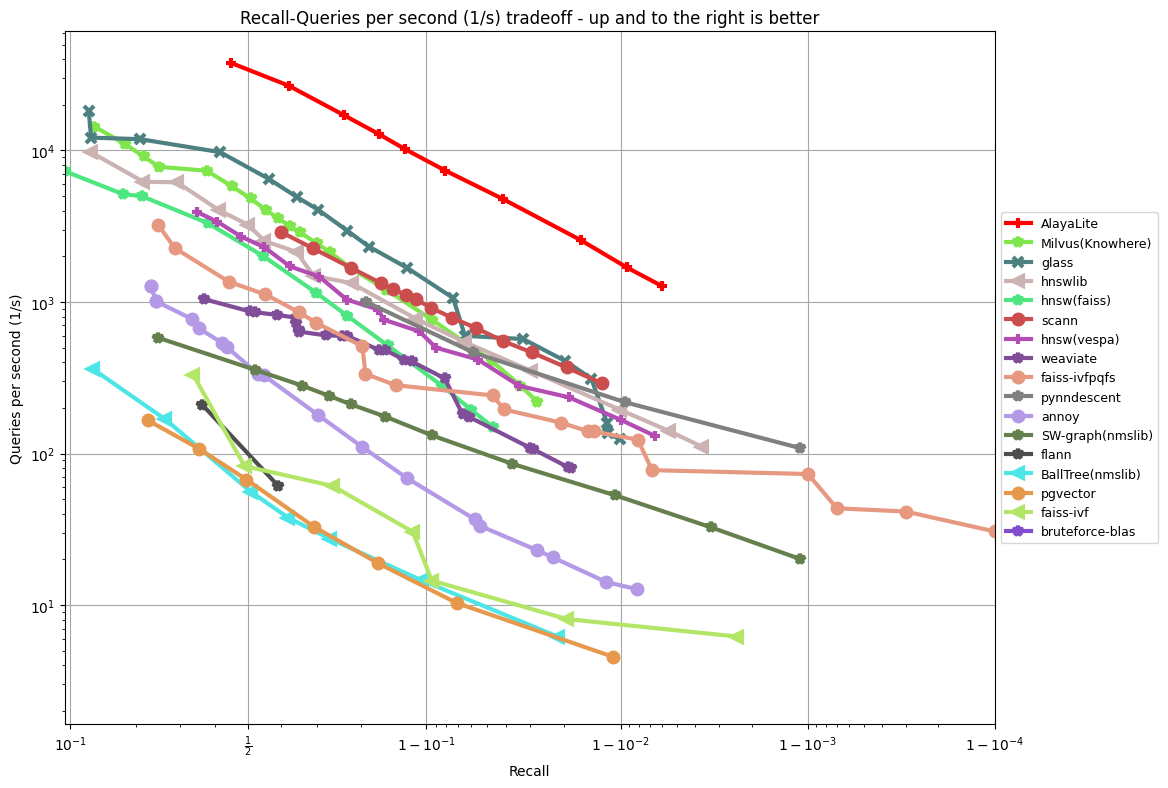 |
|---|---|
Fashion-MNIST 784 Euclidean |
Gist 960 Euclidean |
In-memory collection vs. other mainstream systems
The same in-memory path powers Collection hybrid search when metadata filters
are involved. We evaluate this filtered retrieval workflow using
VectorDBBench on the
Medium Cohere dataset (1M vectors, 768 dimensions). The following results
report QPS under 0.1% selectivity filters at concurrency 1 and 80.
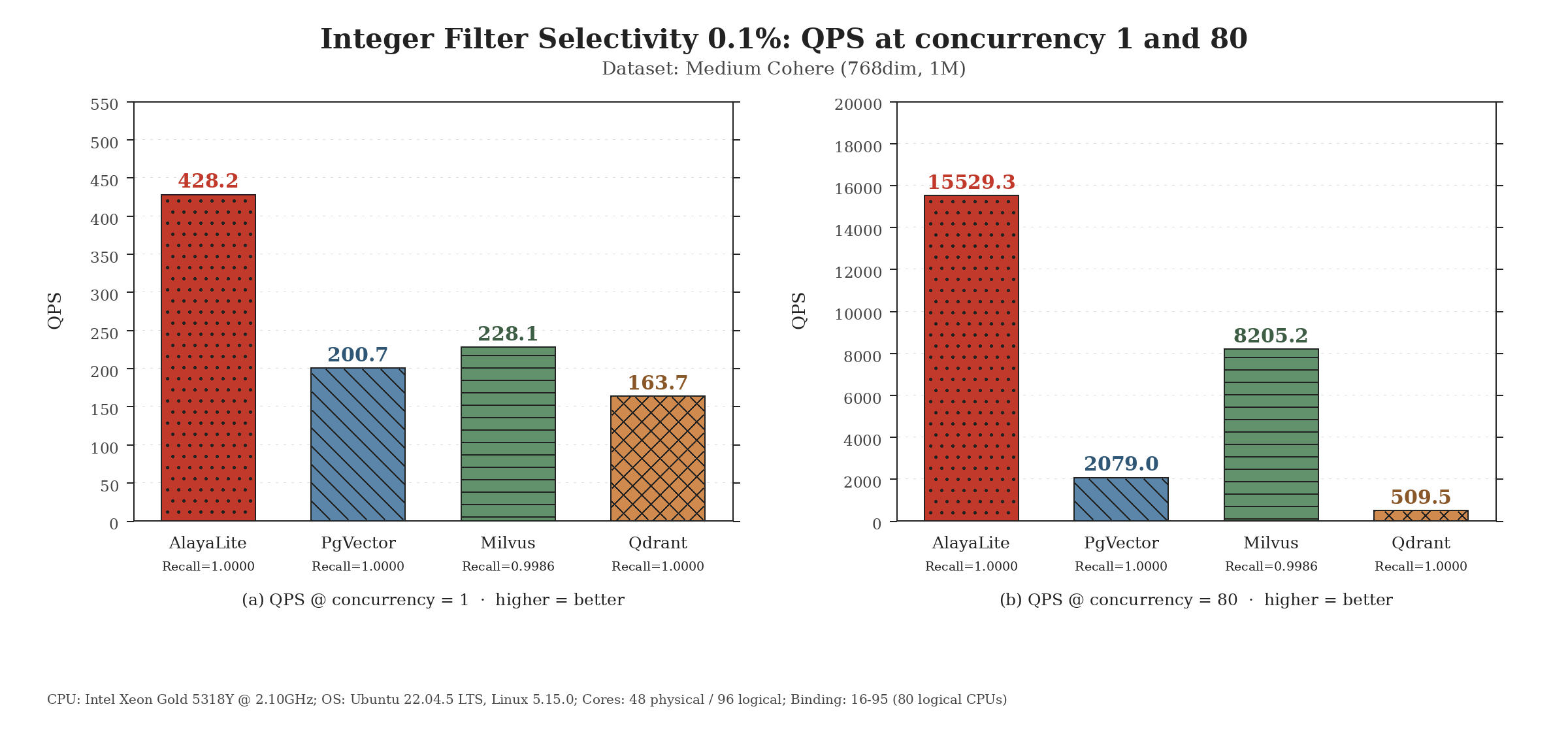
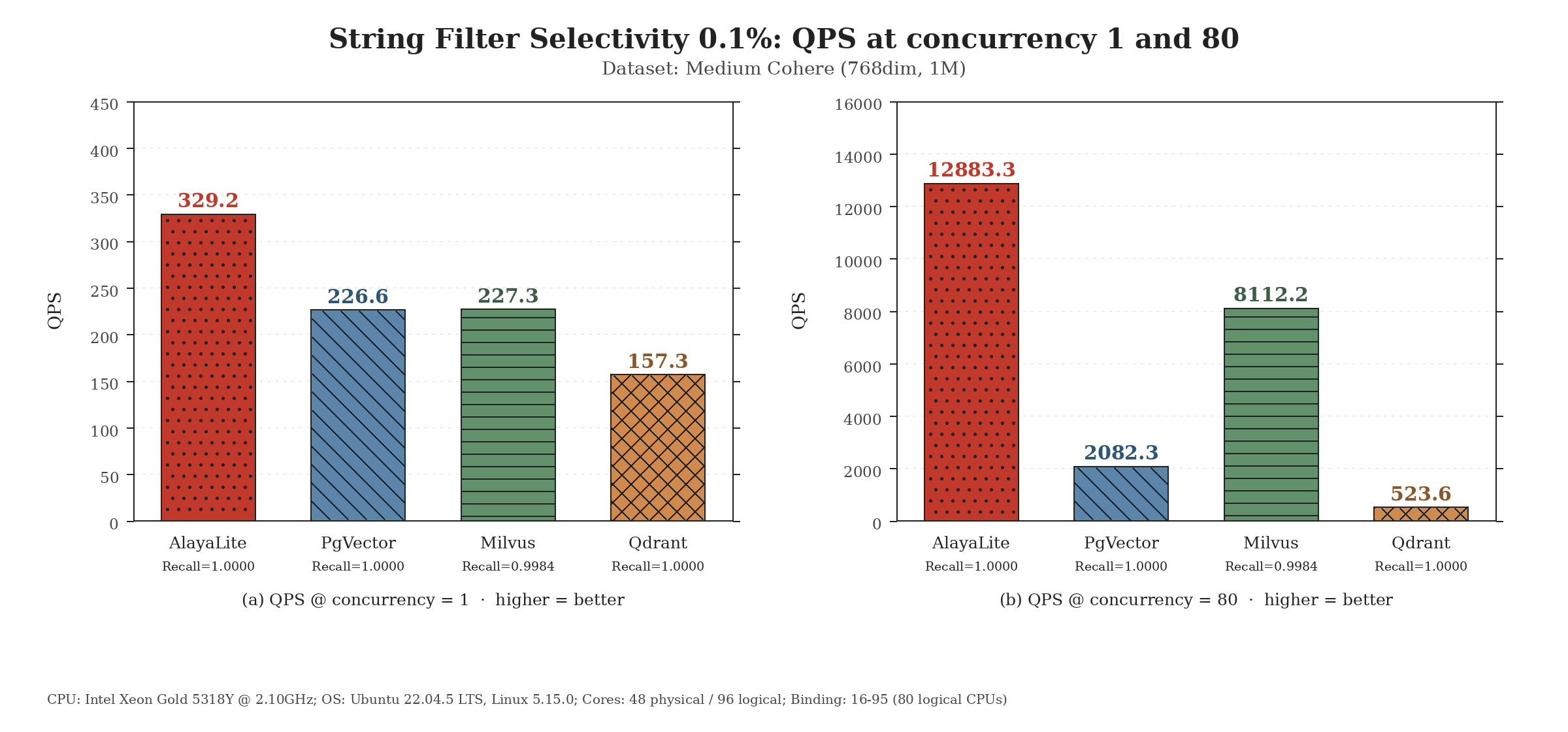
On-disk LASER vs. other large-scale systems
For the on-disk path, we compare LASER against other disk-resident vector systems on DPR100M (101M vectors × 768 dimensions, L2). Numbers are read directly from the benchmark output — see the AlayaLaser paper (SIGMOD 2026) for the algorithm details.
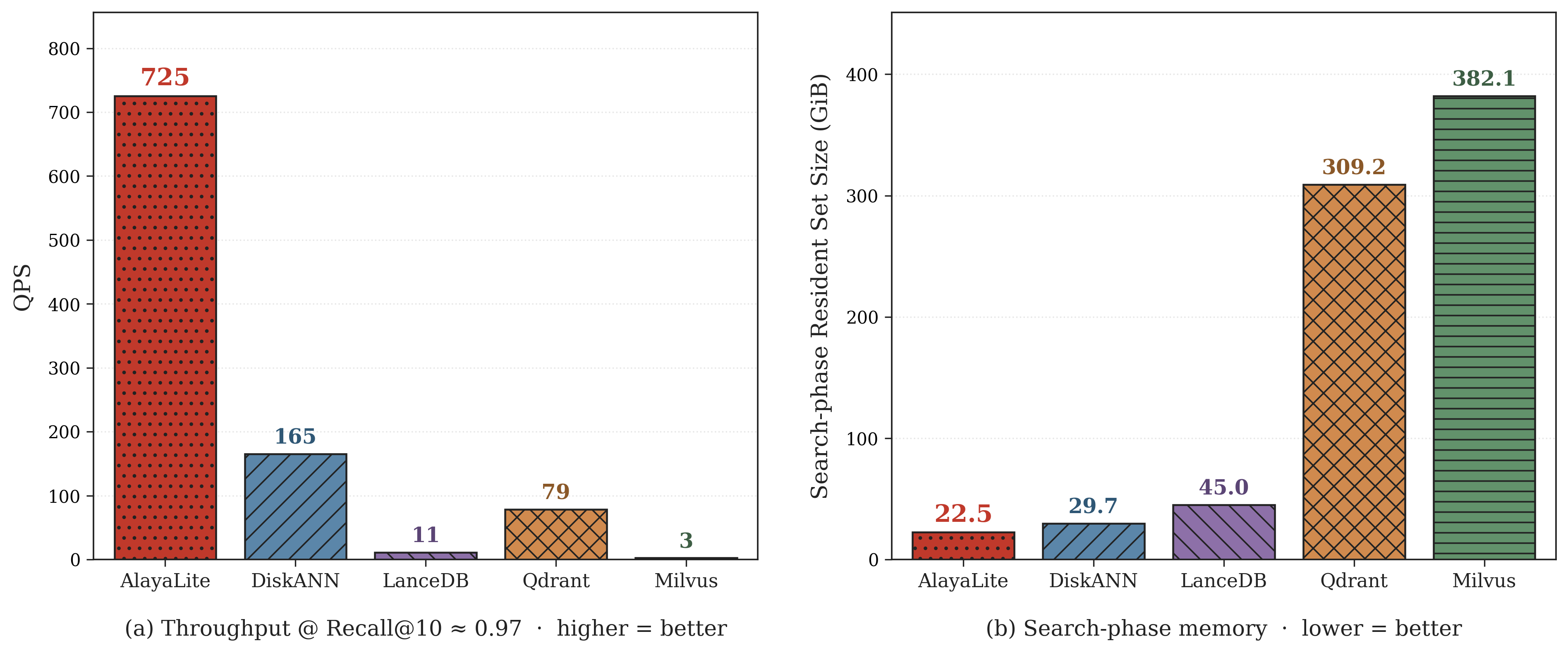
At Recall@10 ≈ 0.97, LASER serves about 725 QPS — roughly 4.4× DiskANN (165), 9.2× Qdrant (79), and 66× LanceDB (11) on this dataset, while Milvus (3) does not reach this recall band reliably. The search-phase resident set is 22.5 GiB, an order of magnitude below Qdrant (309.2 GiB) and Milvus (382.1 GiB) on the same workload.
Contributing
We welcome contributions to AlayaLite! If you would like to contribute, please follow these steps:
- Start by creating an issue outlining the feature or bug you plan to work on.
- We will collaborate on the best approach to move forward based on your issue.
- Fork the repository, implement your changes, and commit them with a clear message.
- Push your changes to your forked repository.
- Submit a pull request to the main repository.
Please ensure that your code follows the coding standards of the project and includes appropriate tests.
Acknowledgements
We would like to thank all the contributors and users of AlayaLite for their support and feedback.
Contact
If you have any questions or suggestions, please feel free to open an issue or contact us at dev@alayadb.ai.
For Chinese-speaking users, you can join our WeChat discussion group by scanning the QR code below:

License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file alayalite-1.0.3-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 3.8 MB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1620c5ea311b10754ea7b009e8dc619ee0ab4cca2704acc79131e9e9e32ff08e
|
|
| MD5 |
600b8aea5a65247b4da9db69970e53f4
|
|
| BLAKE2b-256 |
1635b343e9a866ecaac343c730d0c2b0bbeb32aff6831a115b07da67a518aa63
|
File details
Details for the file alayalite-1.0.3-cp313-cp313-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp313-cp313-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.0 MB
- Tags: CPython 3.13, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b775c6e3d3211d13eac81befe6e7e7f470c5f3c682c9fae41066694596c09e41
|
|
| MD5 |
dda8a8128f4af5d22ad6d20c2f51ed15
|
|
| BLAKE2b-256 |
ceca4e7a39fdabf4bbf1bac5d0b709f792c2c8a90d2ce9f7f1376bd137b45cbd
|
File details
Details for the file alayalite-1.0.3-cp313-cp313-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp313-cp313-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl
- Upload date:
- Size: 7.1 MB
- Tags: CPython 3.13, manylinux: glibc 2.26+ ARM64, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
70490e37804f731706f8cb544421f7e60659278ba9b56a4226bb7635756996d0
|
|
| MD5 |
eebebe0fd644962e252bee5085945481
|
|
| BLAKE2b-256 |
da5c3837a660283d8cbbba63d6376abbfee8eda36ab26a7105c02b8f2b912a1e
|
File details
Details for the file alayalite-1.0.3-cp313-cp313-macosx_15_0_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp313-cp313-macosx_15_0_x86_64.whl
- Upload date:
- Size: 7.0 MB
- Tags: CPython 3.13, macOS 15.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f44bd5f6ebb181c536c1260535f7af2d1c44b242b03c3d4b32d0506aeaf6d777
|
|
| MD5 |
fac4c2ca06ed0846b0583db1675e404e
|
|
| BLAKE2b-256 |
ad2c6185a08f931c55b997f6c35ea306baafc45bd4a3a2cc6859541b5771fc93
|
File details
Details for the file alayalite-1.0.3-cp313-cp313-macosx_15_0_arm64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp313-cp313-macosx_15_0_arm64.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.13, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
adccc20a6cbcf0b94f9e9bfc8f85b3c25b53da18904773a42ce17e53a144fe57
|
|
| MD5 |
7b12f772c6c2d5880b212de023de287f
|
|
| BLAKE2b-256 |
1d128197bc2d979b9444551ed6330f602dac6bca40ed2f460635bb6fb58fd3d7
|
File details
Details for the file alayalite-1.0.3-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 3.8 MB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f9a89d175078cb467a00974b3d51e88904d26c4965380e6e434a0dfe57cdde9c
|
|
| MD5 |
f14b2d808506dbc94408fcb0504a44ee
|
|
| BLAKE2b-256 |
b08d5046e3d7d7dd22a23f8de8ea01a955bb9a1383057fe17ebdb36074b30086
|
File details
Details for the file alayalite-1.0.3-cp312-cp312-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp312-cp312-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.0 MB
- Tags: CPython 3.12, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eec482b9a6ae0ac51b50ec779066fd0f7ef02236b2cdb4ecfea671f975b3c98e
|
|
| MD5 |
8644ea9b14c22d9bcc463767cae5835d
|
|
| BLAKE2b-256 |
4a010fa439806273591c04db7e554ff8e0a934df1db32dd830df104a9d247314
|
File details
Details for the file alayalite-1.0.3-cp312-cp312-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp312-cp312-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl
- Upload date:
- Size: 7.1 MB
- Tags: CPython 3.12, manylinux: glibc 2.26+ ARM64, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
20338ac40106cabcfba746bef5e913b6b596aff98179213fc4b4b2f92ff11058
|
|
| MD5 |
ec729281667a2a3c2ec64aab764f32bf
|
|
| BLAKE2b-256 |
0247034a8b099b1560c87bd4ae10680bb9bc8e79a5e1603ebf37fe64da575f7b
|
File details
Details for the file alayalite-1.0.3-cp312-cp312-macosx_15_0_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp312-cp312-macosx_15_0_x86_64.whl
- Upload date:
- Size: 7.0 MB
- Tags: CPython 3.12, macOS 15.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5ac4a910a07d31cb8f781251be8ffb7ae67dd6a9e82c787f5070ae01633f1bcb
|
|
| MD5 |
4d516ef56afe805d0c72788303fd951d
|
|
| BLAKE2b-256 |
33023f0c77df959d79faa2768f4bd6de3ef442f2c8fa9fcf9ff26b1d0d4632ee
|
File details
Details for the file alayalite-1.0.3-cp312-cp312-macosx_15_0_arm64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp312-cp312-macosx_15_0_arm64.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.12, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
828d138b920684861a1d75b21716b2c57ce7e330115d1d4e89f9dc3ff38fa0d9
|
|
| MD5 |
7dedf5979816e4fb2fbb1710887f25da
|
|
| BLAKE2b-256 |
9d0b89a87d41bb323e3a7fc2316fd0501d8276c9bd0bd47634789455a01c75ef
|
File details
Details for the file alayalite-1.0.3-cp311-cp311-win_amd64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp311-cp311-win_amd64.whl
- Upload date:
- Size: 3.8 MB
- Tags: CPython 3.11, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b0a3b9f65a7c7aa12e7da84421b37bc6c3b567b8450733756070df212c4307ac
|
|
| MD5 |
b328f1756fa30cbf9ea75fa12a56c27b
|
|
| BLAKE2b-256 |
47ff9698c82f1d5b39fda9e14bcd8e5e349644baedad17aef89e7acde1732aed
|
File details
Details for the file alayalite-1.0.3-cp311-cp311-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp311-cp311-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.0 MB
- Tags: CPython 3.11, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ed84071cf8311a63bd78860293b3631d26d8ad95ea4f996c63df538b8e3d1c29
|
|
| MD5 |
a3739e78feef38be9d78ba4777a1f588
|
|
| BLAKE2b-256 |
8146d961f7acda9525ae7fa4be161b7260c14a8cc55a5188685f50b7ef2bf61a
|
File details
Details for the file alayalite-1.0.3-cp311-cp311-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp311-cp311-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl
- Upload date:
- Size: 7.1 MB
- Tags: CPython 3.11, manylinux: glibc 2.26+ ARM64, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
00f64770c097a3144fad15e127f08477ff8b933b425aedf92a4fa6bd1fbf3daa
|
|
| MD5 |
3ea39063f8d6d8972725f2b87cfa5079
|
|
| BLAKE2b-256 |
213a83ab525de73f0395a28078777a3f9af25b6185e8b9408b3ad4d2f59ee6a6
|
File details
Details for the file alayalite-1.0.3-cp311-cp311-macosx_15_0_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp311-cp311-macosx_15_0_x86_64.whl
- Upload date:
- Size: 7.0 MB
- Tags: CPython 3.11, macOS 15.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b5296f5cf297b61674473d623ee651982ffe3e882aa03eac92b2d8fe6653136c
|
|
| MD5 |
057ae701b10c223a12bd5e9afb975a3c
|
|
| BLAKE2b-256 |
d234dc514d5d09d8ca01f62262bcfa1f525bae9052226d0babb42a6153f2b53a
|
File details
Details for the file alayalite-1.0.3-cp311-cp311-macosx_15_0_arm64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp311-cp311-macosx_15_0_arm64.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.11, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4fb8da392e22446a8a08a89eae27c284c8c64b2ac2c8d3e64d4d2d46937d1608
|
|
| MD5 |
6d2540dcf3fc89fab696efdbf6351383
|
|
| BLAKE2b-256 |
0821572235fb0edea4baa3e33be8daed5b46191a9f81d2c92d83c051ec901182
|
File details
Details for the file alayalite-1.0.3-cp310-cp310-win_amd64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp310-cp310-win_amd64.whl
- Upload date:
- Size: 3.8 MB
- Tags: CPython 3.10, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
671c5a678b1ec571615dc47c649d7ccc1a971186d348f4fbd7a60bb45c58c41f
|
|
| MD5 |
1c315903ff879baa4510bcd61a82639b
|
|
| BLAKE2b-256 |
6295a09a4b92dd7d5b6842895a8ba1bdb9ecc700df6c97ee921199b7d947b55f
|
File details
Details for the file alayalite-1.0.3-cp310-cp310-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp310-cp310-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.0 MB
- Tags: CPython 3.10, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
78584dc912e0d7e09fc36d754d01a78497c6ae3f251f88e71b0d4eff105324ac
|
|
| MD5 |
b6bc80a4bd119e94b5e3201c3676d79d
|
|
| BLAKE2b-256 |
7acf580ffc4ba0a1da8df70c685502e4fba9774f4ed5f67c6323fefef204193e
|
File details
Details for the file alayalite-1.0.3-cp310-cp310-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp310-cp310-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl
- Upload date:
- Size: 7.1 MB
- Tags: CPython 3.10, manylinux: glibc 2.26+ ARM64, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
984fee4fd91fc973bbd5d935511194b1b25244f5ce4869d36ea0df02e0f1cd57
|
|
| MD5 |
14077ac8f96f429ef3bee62f38c34930
|
|
| BLAKE2b-256 |
160938662914cb138e04968bf1838011784b3c115437c19aa3b93dfc4e630c6c
|
File details
Details for the file alayalite-1.0.3-cp310-cp310-macosx_15_0_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp310-cp310-macosx_15_0_x86_64.whl
- Upload date:
- Size: 7.0 MB
- Tags: CPython 3.10, macOS 15.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5978cfddcbab2414febd541c494588f434c2d904ad01628252f8e8d25c7dc18c
|
|
| MD5 |
c068b4f487d0ae5aca97721ac0f51fd1
|
|
| BLAKE2b-256 |
c28dec0bb987c3cd35487e0d4661ee02e6846983ca0e85b8f5cb2b10e8aa6edb
|
File details
Details for the file alayalite-1.0.3-cp310-cp310-macosx_15_0_arm64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp310-cp310-macosx_15_0_arm64.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.10, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
51069cb1f8820d5c60a7d10e06705d437fd118e14639ef80e8eaff0cacbd074f
|
|
| MD5 |
1c3a3ce73c9ef3c48171e241312a6b6a
|
|
| BLAKE2b-256 |
ff0ad141e251ef83f24a1aba2c515944e16ee11c91b9f9408138fac70e32e4c8
|
File details
Details for the file alayalite-1.0.3-cp39-cp39-win_amd64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp39-cp39-win_amd64.whl
- Upload date:
- Size: 3.8 MB
- Tags: CPython 3.9, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
90c345a371b0d34475a51802a59de0471a239db4466ecebd618ae8d257e7095a
|
|
| MD5 |
99410f60ff8cb414daf207379515df63
|
|
| BLAKE2b-256 |
ad3bfd3ff94f0d818385c0572597697f3fa4b4853d17dd7786eb613d76ea171a
|
File details
Details for the file alayalite-1.0.3-cp39-cp39-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp39-cp39-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.0 MB
- Tags: CPython 3.9, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f769388246aad3a24ea53bc3c6afc9569782cfecb6258ce1513f28599f34e145
|
|
| MD5 |
b971a475efb62aca948a16f92143566b
|
|
| BLAKE2b-256 |
4fcc34e916b89dc38c12205d3452363bb3dbb33e1e1b972ab45d38bfa90ef236
|
File details
Details for the file alayalite-1.0.3-cp39-cp39-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp39-cp39-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl
- Upload date:
- Size: 7.1 MB
- Tags: CPython 3.9, manylinux: glibc 2.26+ ARM64, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a9dde7f0324967ffe2df981c546ad64e924437c2afb002665a77ccfc7e2aac0b
|
|
| MD5 |
061fa7279a2d0e9d1285767a880b4500
|
|
| BLAKE2b-256 |
9fc79c7392f279c03194ca36cce9df2eae17f9a12c8c4a64bf22b54bd25a826b
|
File details
Details for the file alayalite-1.0.3-cp39-cp39-macosx_15_0_x86_64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp39-cp39-macosx_15_0_x86_64.whl
- Upload date:
- Size: 7.0 MB
- Tags: CPython 3.9, macOS 15.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a51cd8002a12d19f939daa6cd0e5f7f0ddb2737f33aa85332911caf62bf4f677
|
|
| MD5 |
9a69145aa1033feef27af0a9b68478e2
|
|
| BLAKE2b-256 |
9efe94b0b21d2937b853797ddeed7fe79e89201b1f81ac4fabd967aedfc6346d
|
File details
Details for the file alayalite-1.0.3-cp39-cp39-macosx_15_0_arm64.whl.
File metadata
- Download URL: alayalite-1.0.3-cp39-cp39-macosx_15_0_arm64.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.9, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
60cee82972853aacb7c74b7ca768cc3e1994331e932c889af3bd64361beed796
|
|
| MD5 |
087f8248cb4c69e62c4f9be48f17d022
|
|
| BLAKE2b-256 |
c348238e317ee5ec3739a6615b29bc282571d90d9f87c4998d90aca6b1abdae9
|







