AlienSky optimized inference engine for Qwen on Apple Silicon

Project description
AlienSkyQwen
10x longer conversations. Better accuracy. On your Mac. Works with Qwen3.6 and Qwen3.5 models.
AlienSkyQwen brings enterprise-grade inference optimization to your Mac. Built on the same AlienSky technology licensed to hyperscalers and inference providers, it reduces the memory needed for conversation history by up to 16x while improving reasoning accuracy by up to +7.8 percentage points — no model changes, no quality trade-offs.
AlienSky improves reasoning accuracy on every model tested. Perplexity improves or shows near-zero impact — the optimized model predicts text as well or better than baseline.
Quick Start
Step 1: Install Python 3.11 or newer
Open Terminal and check your Python version:
python3 --version
If it shows 3.10 or older, install a newer version:
brew install python@3.14
Don't have Homebrew? Install it first: https://brew.sh
Step 2: Create a virtual environment
python3 -m venv ~/.aliensky
source ~/.aliensky/bin/activate
You'll see (.aliensky) appear in your terminal prompt. This means the environment is active.
Note: Every time you open a new terminal window, you need to re-activate:
source ~/.aliensky/bin/activate
Step 3: Install AlienSkyQwen
pip install alienskyqwen
This will also install mlx and mlx-lm automatically.
Step 4: Run your first model
python3 -c "
from alienskyqwen import aliensky_load
import mlx_lm
model, tokenizer = aliensky_load('mlx-community/Qwen3.5-27B-4bit')
print(mlx_lm.generate(model, tokenizer, 'Explain quantum computing in simple terms', max_tokens=500))
"
The first run will download the model (~14 GB). Subsequent runs use the cached version.
Or run as an OpenAI-compatible server
alienskyqwen-serve --model mlx-community/Qwen3.5-27B-4bit --port 8080
Then connect any chat interface (Open WebUI, chatbot-ui, or curl) to http://localhost:8080/v1.
Optimization Profiles
| Profile | KV Compression | Best For |
|---|---|---|
aliensky_v1_std |
9.85x | General use with dense models (default) |
aliensky_v1_fast |
16x | Maximum memory savings, long contexts |
aliensky_v1_quality |
6.56x | Peak accuracy on dense models |
aliensky_v1_balance |
10.67x | MoE models (recommended for 35B-A3B, 122B) |
model, tokenizer = aliensky_load("mlx-community/Qwen3.6-35B-A3B-4bit",
profile="aliensky_v1_balance")
Supported Models
| Model | Model Size (Q4) | Recommended Profile |
|---|---|---|
| Qwen3.6-35B-A3B | ~18 GB | aliensky_v1_balance |
| Qwen3.5-27B | ~14 GB | aliensky_v1_std |
| Qwen3.5-27B-Claude-Distilled | ~15 GB | aliensky_v1_std |
| Qwen3.5-122B-A10B | ~68 GB | aliensky_v1_balance |
| Qwen3.5-9B | ~5 GB | aliensky_v1_std |
Results at a Glance
All benchmarks run on Mac Studio M3 Ultra (512 GB). Full methodology and per-context breakdowns available in BENCHMARKS.
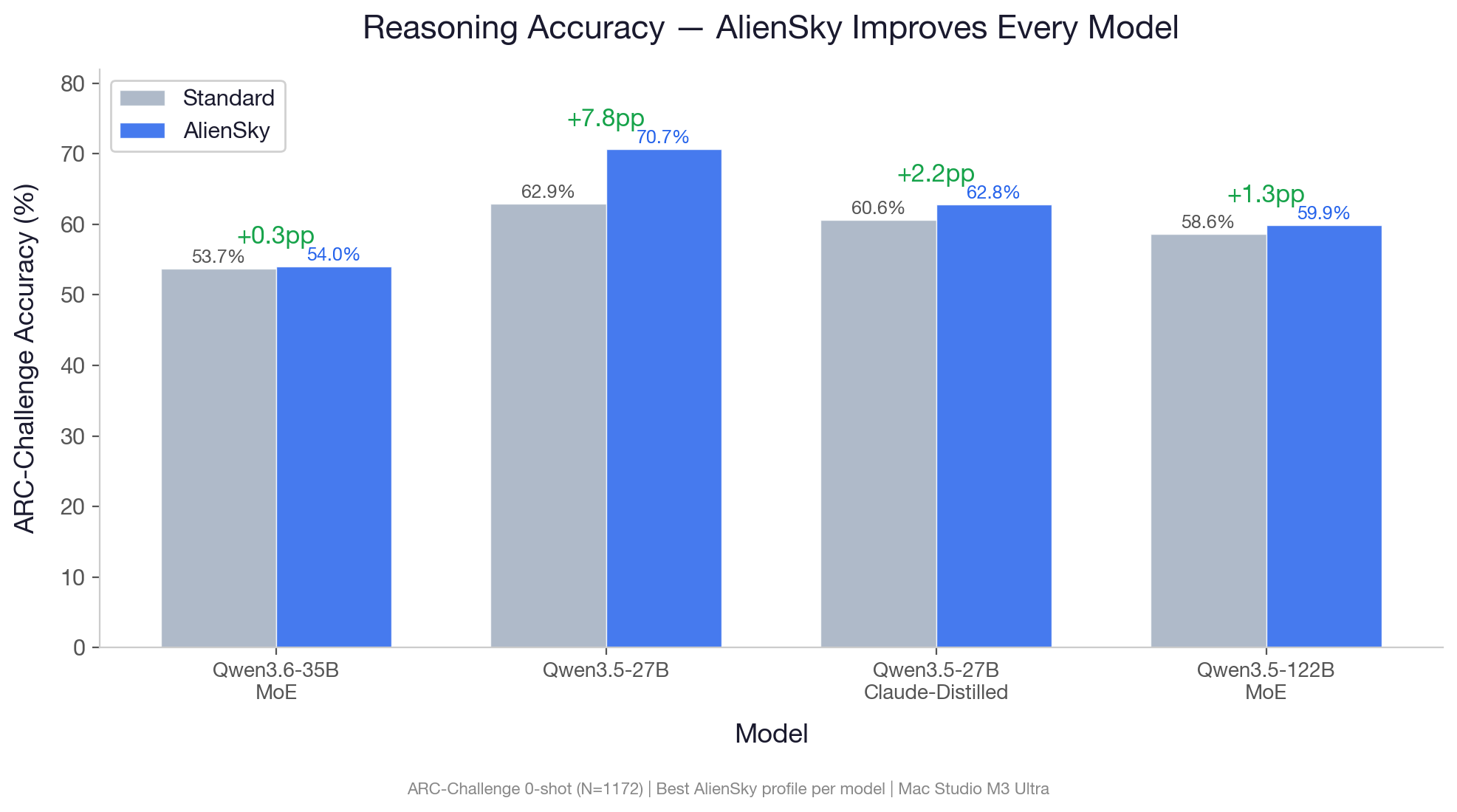
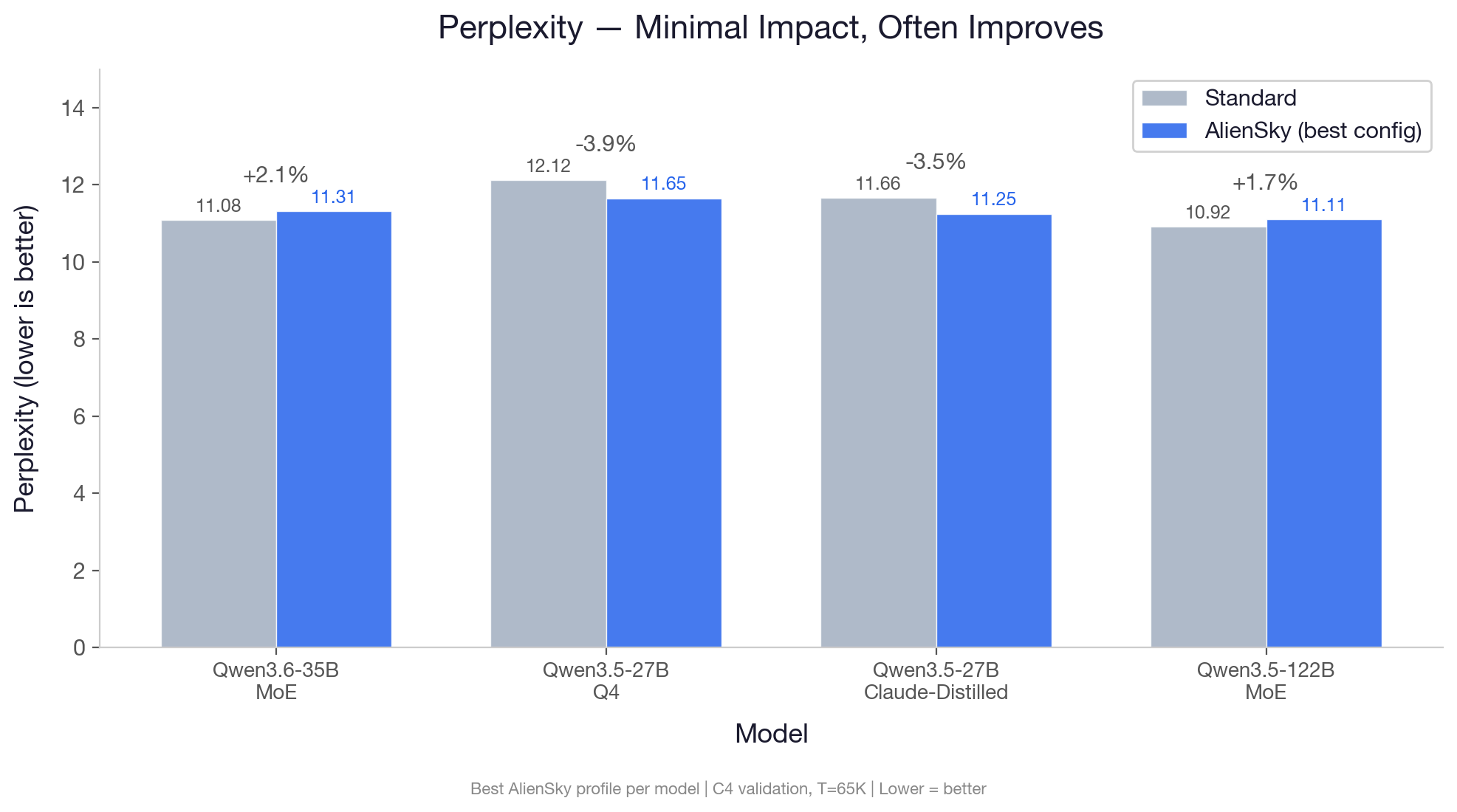
Accuracy
| Model | Profile | ARC-Challenge | MMLU (5-shot) | HellaSwag | Perplexity (C4) |
|---|---|---|---|---|---|
| Qwen3.6-35B-A3B (Q4) | v1_balance |
+0.34pp | +0.20pp | -0.50pp | +2.1% |
| Qwen3.5-27B (Q4) | v1_std |
+7.76pp | -2.00pp | -1.90pp | -4.3% |
| Qwen3.5-27B-Claude-Distilled (Q4) | v1_quality |
+2.22pp | — | — | -3.5% |
| Qwen3.5-27B (8-bit) | v1_quality |
+2.82pp | -1.00pp | -1.30pp | +0.5% |
| Qwen3.5-122B-A10B (Q4) | v1_quality |
+1.28pp | -2.20pp | -1.45pp | +1.7% |
| Qwen3.5-9B (Q4) | v1_std |
+1.54pp | — | -2.25pp | — |
AlienSky improves ARC-Challenge reasoning accuracy on every model tested. Perplexity improves on both 27B variants (lower is better) — the optimized model predicts text more accurately than baseline. The 8-bit and MoE models show near-zero PPL impact.
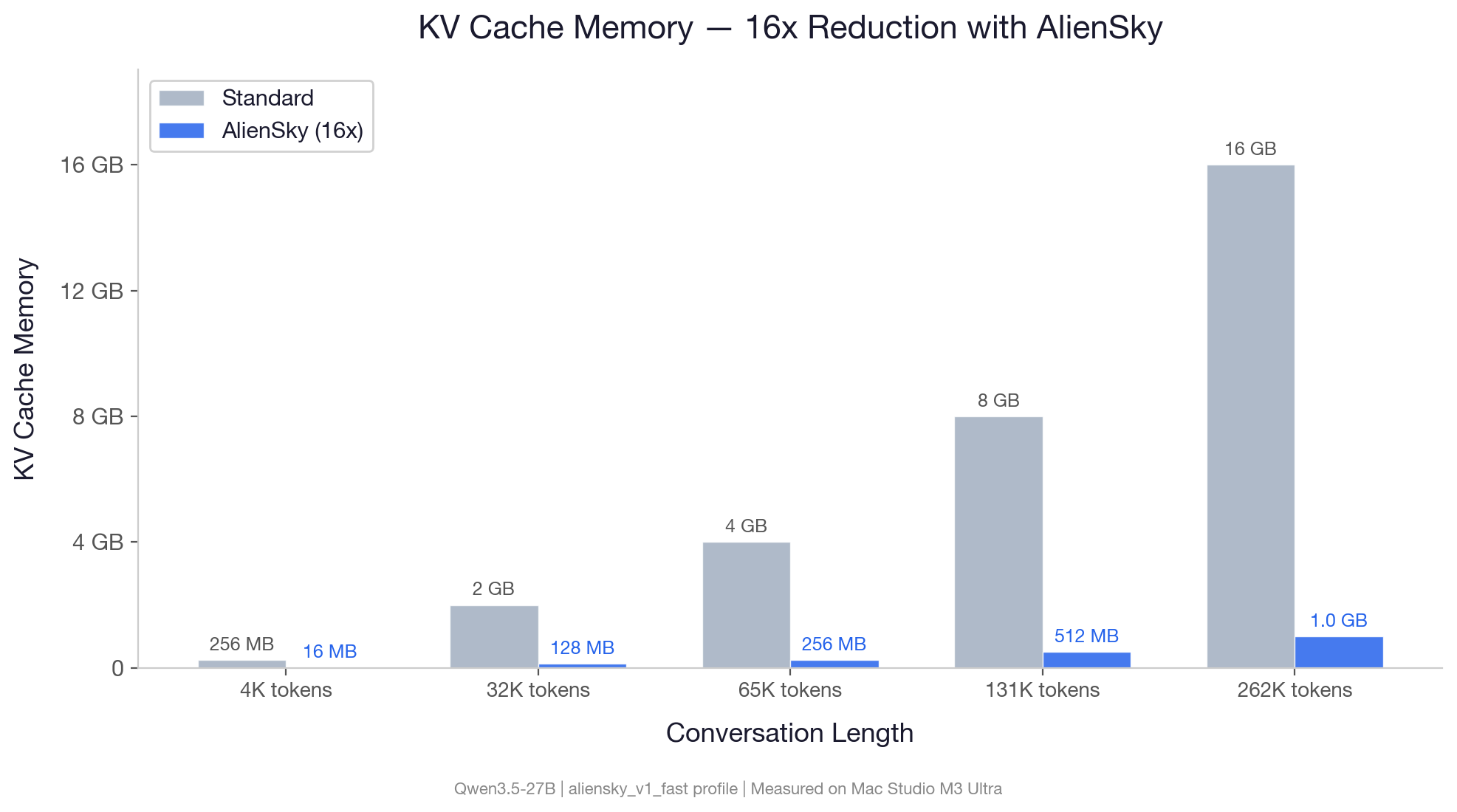
Memory Savings (KV Cache)
| Context Length | Baseline (27B) | AlienSky (v1_std, 9.85x) |
AlienSky (v1_fast, 16x) |
|---|---|---|---|
| 32K tokens | 2.0 GB | 208 MB | 128 MB |
| 131K tokens | 8.0 GB | 832 MB | 512 MB |
| 262K tokens | 16.0 GB | 1.6 GB | 1.0 GB |
MoE models (35B-A3B, 122B-A10B) achieve 10.67x savings with the v1_balance profile.
Decode Speed
| Context | Baseline | AlienSky (v1_std) |
Ratio |
|---|---|---|---|
| 4K tokens | 103.7 tok/s | 88.6 tok/s | 0.85x |
| 8K tokens | 99.3 tok/s | 85.8 tok/s | 0.86x |
| 32K tokens | 87.1 tok/s | 72.0 tok/s | 0.83x |
On Apple Silicon, decode speed is bottlenecked by model weight loading, not the KV cache. AlienSky's overhead is minimal in practice.
How It Works
When an LLM generates text, it stores the entire conversation in a structure called the KV cache. This cache grows with every token and can consume gigabytes of RAM.
AlienSky optimizes this at multiple levels:
- Compresses conversation memory to a fraction of its original size
- Computes attention directly on the compressed form — no decompression needed, up to 5x faster attention at long contexts
- Runs on Apple Metal via a custom GPU kernel for maximum speed
The result: 10-16x less memory, faster attention, and in many cases better answers — the optimization acts as noise reduction for the model's internal state.
What this unlocks: With 16x less memory per conversation, you can run multiple conversations in parallel, keep several models loaded simultaneously, or handle book-length contexts that would otherwise exhaust your Mac's RAM.
Requirements
- Apple Silicon Mac (M1 or newer)
- macOS 14.0+
- Python 3.11-3.14
- 16 GB+ unified memory (64 GB+ recommended for 27B models)
API Reference
aliensky_load(model, profile, data_path)
Load a model with AlienSky optimization.
model— HuggingFace model ID or local pathprofile— Optimization profile (default:"aliensky_v1_std")data_path— Path to AlienSky data file (auto-detected by default)
Returns (model, tokenizer) for use with mlx_lm.generate() or mlx_lm.server.
alienskyqwen-serve
alienskyqwen-serve [--model MODEL] [--profile PROFILE] [--port PORT] [--host HOST]
OpenAI-compatible API server. Default model: Qwen3.5-27B-4bit. Default port: 8080.
FAQ
Does AlienSky modify the model weights? No. It only optimizes how the model stores and retrieves conversation memory.
Why does reasoning accuracy improve? The compression acts as regularization, filtering noise in the model's internal representations. This effect is strongest on reasoning benchmarks and distilled models.
Can I use this with LM Studio?
Not directly. Run alienskyqwen-serve and connect any OpenAI-compatible client (Open WebUI, chatbot-ui, curl, etc.) to http://localhost:8080/v1.
What about Llama, Gemma, or other models? AlienSky currently supports Qwen3.5 and Qwen3.6. Additional architectures are planned.
License
Free for personal use. Commercial use requires a license. No modifications permitted. See LICENSE for full terms.
Copyright (c) 2026 AlienSky LLC.
"Qwen" is a trademark of Alibaba Group. AlienSky LLC is not affiliated with, endorsed by, or sponsored by Alibaba Group.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file alienskyqwen-0.1.4-cp314-cp314-macosx_14_0_arm64.whl.
File metadata
- Download URL: alienskyqwen-0.1.4-cp314-cp314-macosx_14_0_arm64.whl
- Upload date:
- Size: 74.4 MB
- Tags: CPython 3.14, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f47718f0aedfb3d6f49cc196057b02665637ff940388a811c133a43f967def18
|
|
| MD5 |
85f7d5c5b5cb6698ac04bd58a1c027c9
|
|
| BLAKE2b-256 |
54ca742b29c8e60c67a2c26734983874649b2ef01764e6ea3576036a715ebe83
|
File details
Details for the file alienskyqwen-0.1.4-cp313-cp313-macosx_14_0_arm64.whl.
File metadata
- Download URL: alienskyqwen-0.1.4-cp313-cp313-macosx_14_0_arm64.whl
- Upload date:
- Size: 74.4 MB
- Tags: CPython 3.13, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
54d5aa25be407ba12cf0084494b288564a8ae6676960ef70f78dc84207bfd78b
|
|
| MD5 |
40c11f393f96918deb080479c19fb656
|
|
| BLAKE2b-256 |
e3f6edf0bfc005ba33c6274badbf2a74dc6b4a2b3067c40c6e478f2e2317bfa9
|
File details
Details for the file alienskyqwen-0.1.4-cp312-cp312-macosx_14_0_arm64.whl.
File metadata
- Download URL: alienskyqwen-0.1.4-cp312-cp312-macosx_14_0_arm64.whl
- Upload date:
- Size: 74.4 MB
- Tags: CPython 3.12, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4b3e9909c49027e549dc8ab3a5e08cfa5f7296b1339c14a2330d94adc4ff789b
|
|
| MD5 |
39127eff7967dc1834ab5b627f7bd8cb
|
|
| BLAKE2b-256 |
0fa08dcc8cd7503f125486691c5a0daf80509a4cc70dbfdc80025decff74e1c3
|
File details
Details for the file alienskyqwen-0.1.4-cp311-cp311-macosx_14_0_arm64.whl.
File metadata
- Download URL: alienskyqwen-0.1.4-cp311-cp311-macosx_14_0_arm64.whl
- Upload date:
- Size: 74.4 MB
- Tags: CPython 3.11, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ba43888c7918a153daf11321d264442a72020fce28c90becfcbf154996290da0
|
|
| MD5 |
c90daadef83f805a8ce3ccd1067929cc
|
|
| BLAKE2b-256 |
3664db6497572db8b548b3637e79620339b86ba9cc3433647ec8c419ac6f0542
|







