Works with Anna's Archive's ISBN code files

Project description
allisbns
allisbns is a Python package to work with the packed ISBN codes from Anna's Archive. It helps you to examine, manipulate, and plot such data that represent the largest fully open list of all known ISBNs.
(This project is not affiliated with Anna's Archive.)
Source Documentation Changelog
Introduction
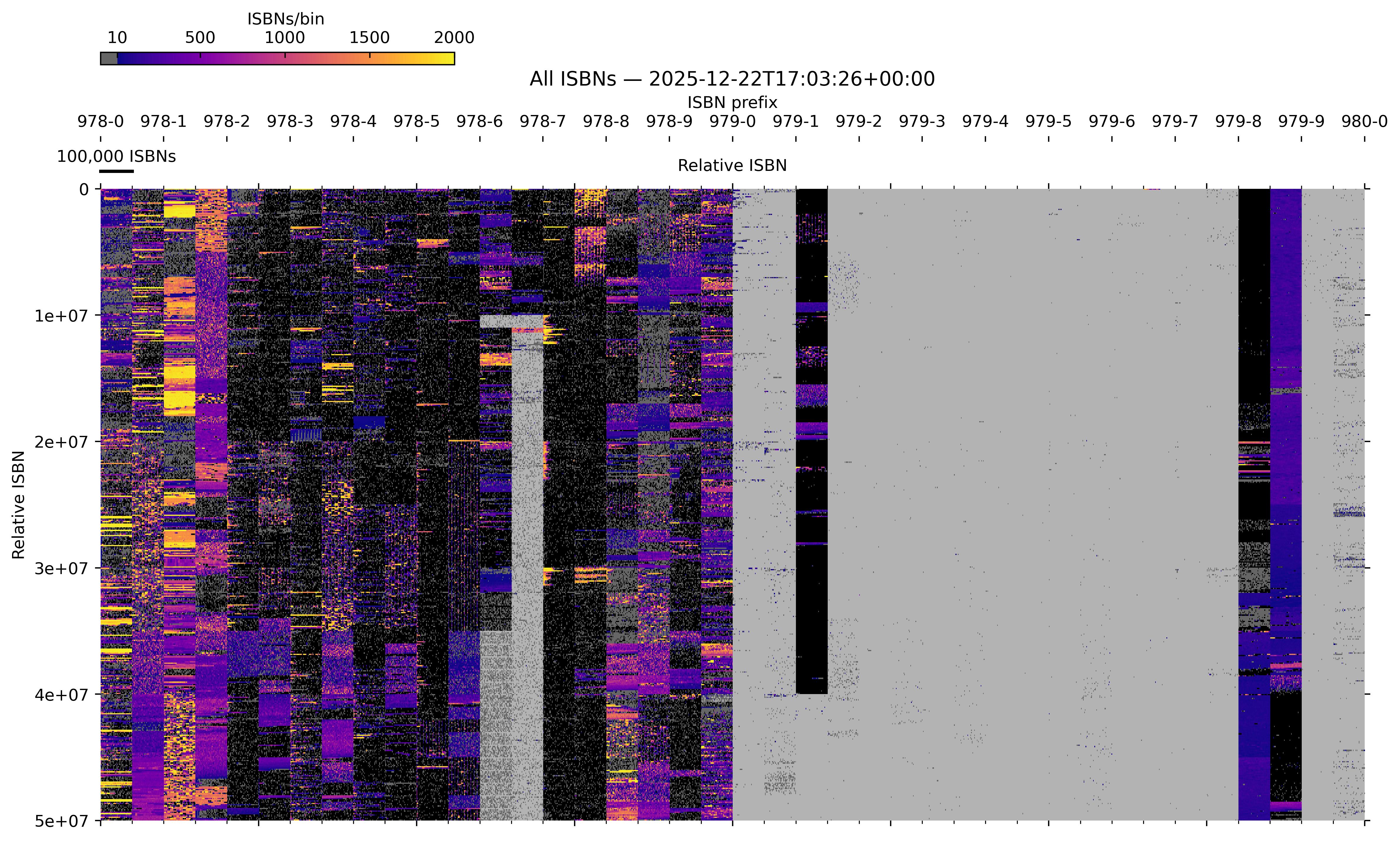
Anna's Archive, besides books and datasets, provides a large amount of metadata from different sources (including WorldCat, Google Books, the Chinese collections, and many others). Such an extensive collection presumably represents the largest openly available metadata about all known ISBNs ever published (see the figure below).
The derived metadata, periodically published by Anna and the team, includes the packed ISBN codes, a very compact representation of all ISBNs with distinction of original data sources: it can tell you what ISBNs are available in a dataset.
After the visualization contest, the beautiful interactive viewer exists to explore all ISBNs. However, sometimes you need more imperative control over the available data: check many ISBNs at once, analyze selected regions, compare different dumps, plot custom images, etc.

Binned image (hi-res version) of all known ISBNs (source: Anna's Archive). The defined ISBN registration groups are underlaid in black. See here how it is plotted.
Installation
The package is available on PyPI:
pip install allisbns
To include optional plotting support, install it as:
pip install allisbns[plotting]
Quickstart
Download data
The package works with datasets provided as bencoded files named as
aa_isbn13_codes_*.benc.zst. Such files are located in the codes_benc
directory within the
aa_derived_mirror_metadata
torrents.
Work with datasets
Creates a dataset from the downloaded file with ISBN codes:
>>> from allisbns.dataset import CodeDataset
>>> md5 = CodeDataset.from_file(
... source="aa_isbn13_codes_20251118T170842Z.benc.zst",
... collection="md5",
... )
>>> md5
CodeDataset(array([ 6, 1, 9, ..., 1, 91739, 1],
shape=(14737375,), dtype=int32), bounds=(978000000000, 979999468900))
Here the md5 collection represents files available for downloading in Anna's
Archive. All available collections are:
'airitibooks', 'bloomsbury', 'cadal_ssno', 'cerlalc', 'chinese_architecture',
'duxiu_ssid', 'edsebk', 'gbooks', 'goodreads', 'hathi', 'huawen_library', 'ia',
'isbndb', 'isbngrp', 'kulturpass', 'libby', 'md5', 'nexusstc',
'nexusstc_download', 'oclc', 'ol', 'ptpress', 'rgb', 'sciencereading', 'shukui',
'sklib', 'trantor', 'wanfang', 'zjjd'
Query one ISBN:
>>> md5.query_isbn(978_2_36590_117)
QueryResult(is_streak=True, segment_index=8652142, position_in_segment=0)
Check many ISBNs:
>>> md5.check_isbns(range(978_2_36590_000, 978_2_36590_999 + 1))
array([ True, False, False, ..., False, False, False], shape=(1000,))
Get all filled ISBNs:
>>> md5.get_filled_isbns()
array([978000000000, 978000000001, 978000000002, ..., 979999377030,
979999377160, 979999468900], shape=(16916212,))
Crop the dataset to some ISBN region:
>>> from allisbns.isbn import get_prefix_bounds
>>> start_isbn, end_isbn = get_prefix_bounds("978")
>>> md5.crop(start_isbn, end_isbn)
CodeDataset(array([6, 1, 9, ..., 1, 2, 2],
shape=(14503001,), dtype=int32), bounds=(978000000000, 978999999999))
Further reading
After installing, check out the documentation. See Overview for the first guidance. The API reference describes modules, classes, and functions. There are practical examples that will demonstrate the main usage. Cookbook also contains useful examples. You want to contribute code? Contributing tells how to participate.
License
Creative Commons Zero v1.0 Universal.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file allisbns-0.1.1.tar.gz.
File metadata
- Download URL: allisbns-0.1.1.tar.gz
- Upload date:
- Size: 31.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c2614747526e09d5fa85b1326b37b60c5449ab6eb77227c84a77c515e0709bc3
|
|
| MD5 |
7ef9be4a61d13d8e3ea1fb8aa5c86423
|
|
| BLAKE2b-256 |
ef2902a686baa272fc4a29086c5a483d099b34ed30023df379d453865321fb69
|
File details
Details for the file allisbns-0.1.1-py3-none-any.whl.
File metadata
- Download URL: allisbns-0.1.1-py3-none-any.whl
- Upload date:
- Size: 33.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5c7f4e2d0a87f4eac930585600f4f70219ce225f5e46dcb6f877a5704a9c454c
|
|
| MD5 |
f4437a7eaa4d9b9986581f592f351408
|
|
| BLAKE2b-256 |
642c3d34540a5e05e2e29c75dfb11f1890a491c7fb2fc892d37ccbb5b182c6e8
|








{kind=link}