Dataset preparation, dataloaders, and ecosystem bridges for 2D anatomical segmentation.

Project description
2D Anatomy Segmentation Datasets Repository
Welcome to the 2D Anatomy Segmentation Datasets repository! This project provides a collection of scripts, tools, and datasets to streamline training and evaluation for anatomical segmentation tasks in medical imaging. Whether you're a researcher or practitioner in the medical imaging field, this repository is designed to collect 2D anatomical datasets and make it easy to download, process, and visualize data from various imaging modalities.
Prepared datasets plug directly into SMP, mmsegmentation, mmdetection, or HuggingFace through a single splits-JSON contract that carries license, citation, normalization stats, and split seed alongside the data.
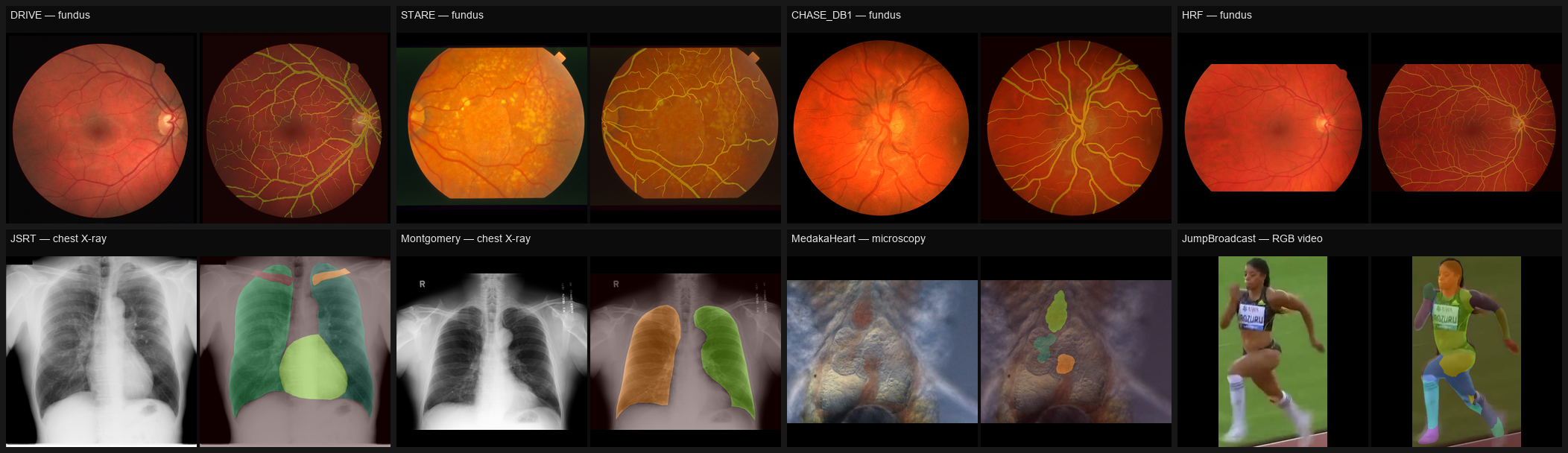
60-second demo (CPU)
git clone https://github.com/ConstantinSeibold/2DAnatomyDatasets.git
cd 2DAnatomyDatasets
pip install -e '.[smp]'
sh src/prepare_data/prepare_drive/get_drive_full.sh
export DRIVE_ROOT_FOLDER=./datasets/drive
python configs/smp/drive_unet.py # one forward + backward step on CPU
Install
pip install -e . # core (dataset prep + raw PyTorch dataloaders)
pip install -e '.[smp]' # + segmentation_models_pytorch
pip install -e '.[mmseg]' # + mmsegmentation adapter / exporter
pip install -e '.[mmdet]' # + mmdetection adapter / exporter
pip install -e '.[hf]' # + HuggingFace datasets
pip install -e '.[all]' # everything
Pick a path
| You want… | Start with |
|---|---|
| Fastest end-to-end training | SMP — from anatomy_datasets import DRIVE; DRIVE(split="train") works with any SMP model. See configs/smp/. |
| Already using mmseg | mmseg runtime adapter — AnatomyMulticlassDataset in your config; no on-disk export. See configs/mmseg/drive_unet.py. |
| Training Mask R-CNN / detection | mmdet — small datasets use shipped COCO; PAXRay-scale uses sharded export. See configs/mmdet/. |
| Training SegFormer / Mask2Former | HuggingFace — to_hf_dataset(splits_json, root) returns a DatasetDict. See configs/hf/. |
| Just the raw masks | Use the splits JSON directly. Format spec below. |
Datasets
Run sh src/prepare_data/prepare_<name>/get_<name>_full.sh to download +
prepare. Each emits a splits JSON with full metadata (license, citation,
BibTeX, normalization stats, seed). Grouped by modality, sorted ascending
by image count within each group.
| Modality | Dataset | #Images | #Classes | Task | License | Env var | Notes |
|---|---|---|---|---|---|---|---|
| Chest X-ray | Montgomery | 138 | 3 | multiclass (left / right lung) | custom-academic | MONTGOMERY_ROOT_FOLDER |
PA chest radiographs from the NLM Montgomery County, MD TB-screening program — 80 normal + 58 TB-positive cases — with bilateral lung-field masks. (Jaeger et al., QIMS 2014.) |
| JSRT | 247 | 5 | multilabel (heart, clavicles, lungs) | custom-academic | JSRT_ROOT_PATH |
Japanese Society of Radiological Technology lung-nodule reference set: 247 PA chest radiographs (originally for CAD ROC analysis of nodule detection) with subsequent manual heart, lung-field, and clavicle annotations from the segmentation02 release. (Shiraishi et al., AJR 2000.) | |
| PAXRay | 852 | 166 | multilabel (fine-grained anatomy) | custom-academic | PAXRAY_ROOT_PATH |
Synthetic chest radiographs generated by projecting fine-grained anatomical labels from CT volumes; 166 classes covering individual bones, lung lobes, mediastinal organs and vessels. (Seibold et al., BMVC 2022.) | |
| PAXRay++ | 14,754 | 157 | multilabel | custom-academic | PAXRAYPP_ROOT |
Scaled-up PAXRay: 14,754 CT-projected chest radiographs (frontal + lateral) with 157 anatomy classes and >2M instance masks, built by ensembling 3D segmentation models over 10,021 thoracic CTs (RSNA-PE, RibFrac, LIDC-IDRI, COVID-19 cohorts) and projecting the volumetric pseudo-labels to 2D. (Seibold et al., 2023.) | |
| Fundus (color) | STARE | 20 | 2 | multiclass (vessel) | unknown | STARE_ROOT_FOLDER |
Structured Analysis of the REtina — classic 20-image vessel-segmentation benchmark with two independent expert annotators. (Hoover et al., IEEE TMI 2000.) |
| CHASE_DB1 | 28 | 2 | multiclass (vessel) | custom-academic | CHASEDB1_ROOT_FOLDER |
Retinal fundus images collected by the Child Heart And health Study in England; both eyes of 14 subjects with manual vessel annotations. (Fraz et al., IEEE TBME 2012.) | |
| DRIVE | 40 | 2 | multiclass (vessel) | custom-academic | DRIVE_ROOT_FOLDER |
Digital Retinal Images for Vessel Extraction — canonical vessel-seg benchmark; 40 fundus images from a Dutch diabetic-retinopathy screening program. (Staal et al., IEEE TMI 2004.) | |
| HRF | 45 | 2 | multiclass (vessel) | CC-BY-4.0 | HRF_ROOT_FOLDER |
High-Resolution Fundus images (3504×2336 or 3072×2048) across three cohorts — 15 healthy, 15 glaucoma, 15 diabetic retinopathy — with manual vessel annotations and FOV masks. (Budai et al., IJBI 2013.) | |
| FIVES | 800 | 2 | multiclass (vessel) | CC-BY-4.0 | FIVES_ROOT_FOLDER |
Fundus Image Vessel Segmentation set: 800 high-resolution color fundus images balanced across Normal / AMD / Diabetic retinopathy / Glaucoma; binary vessel annotations from expert crowdsourcing. (Jin et al., Scientific Data 2022.) | |
| IR retina | RAVIR | 23 | 3 | multiclass (arteries, veins) | custom-academic | RAVIR_ROOT_FOLDER |
Retinal Arteries and Veins in Infrared Reflectance imaging — semantic segmentation dataset distinguishing arteries from veins, used for vessel-morphometry analyses. (Hatamizadeh et al., IEEE JBHI 2022.) |
| OCT | DUKE_OCT | 110 | 16 | multiclass (retinal layers) | custom-academic | DUKE_ROOT_PATH |
Spectral-domain OCT B-scans from patients with diabetic macular edema; retinal-layer boundaries plus fluid regions annotated for layer-segmentation research. (Chiu et al., BOE 2015.) |
| Panoramic X-ray | Teeth | 598 | 1 | detection (tooth) | custom-academic | TEETH_ROOT |
Panoramic dental radiographs with per-tooth polygon instance annotations; Kaggle release curated by Humans in the Loop. |
| Microscopy | MedakaHeart | 805 | 4 | multiclass (bulbus, atrium, heart) | GPL-3.0 | MEDAKA_HEART_ROOT_FOLDER |
Brightfield microscopy of medaka (Japanese rice fish) hatchlings, ventral view; cardiac-chamber segmentation supporting developmental-biology and frugal-labeler methodology research. (Schutera et al., PLOS ONE 2022.) |
| RGB video | JumpBroadcast | 1,809 | 15 | multiclass (body parts) | custom-academic | JUMP_BROADCAST_ROOT_FOLDER |
Cropped frames from TV broadcasts of triple-, high-, and long-jump athletes; per-frame body-part segmentation paired with an arbitrary-keypoint annotation set. (Ludwig et al., CVPRW 2023.) |
| Scintigraphy | BS80k | 82,544 | many | multilabel (bone regions) | custom-academic | BS80K_ROOT |
First large open-access bone-scan dataset: 82,544 images from 3,247 patients at West China Hospital, with anatomical-region segmentations. (Huang et al., Computers in Biology and Medicine 2022.) |
Programmatic metadata + BibTeX access:
from anatomy_datasets import get_dataset_info
info = get_dataset_info("DRIVE")
print(info.license, info.source_url, info.citation, info.bibtex)
Visualization
After preparing a dataset, two ways to inspect image / mask overlays.
Per-dataset verification script — writes overlays to ./verify_visually/<dataset>/:
python src/prepare_data/prepare_drive/verify_drive_visually.py
python src/prepare_data/prepare_hrf/verify_hrf_visually.py
# ...one per dataset under src/prepare_data/prepare_<name>/verify_<name>_visually.py
Programmatic — use the helpers in src/visualization/visualize.py:
from anatomy_datasets import DRIVE
from src.visualization.visualize import visualize_multiclass
import numpy as np
ds = DRIVE(split="train")
image, mask = ds[0]
overlay = visualize_multiclass(np.array(image), np.array(mask).astype(int), ds.label_dict)
Interactive — notebooks/Dataloader_example.ipynb walks through every dataset with rendered overlays.
Splits JSON contract
Every prepared dataset writes one file at <root>/<name>_splits.json:
{
"name": "DRIVE",
"version": "2026-05-18",
"seed": 42, // null if upstream split is fixed
"modality": "fundus",
"license": "custom-academic",
"license_url": "...",
"source_url": "...",
"paper_url": "...",
"citation": "Staal et al., IEEE TMI 2004.",
"bibtex": "@article{...}",
"normalization": {"mean": [r, g, b], "std": [r, g, b]}, // [0,1] float, train images only
"label_dict": {"0": "background", "1": "vessel"}, // keys = class IDs
"train": [{"image": "rel/path.png", "target": "rel/path.png"}, ...],
"val": [...],
"test": [{"image": "..."} , ...] // target may be missing (e.g. DRIVE test); dataloader returns (image, None)
}
Target file conventions:
- Multilabel (
.npy): 3D mask stack(C, H, W). Channel = class ID =label_dictkey. - Multiclass (PNG): single-channel integer mask. Pixel value = class ID.
Missing-GT entries return (image, None). Use collate_optional_target for batching:
from anatomy_datasets import collate_optional_target
DataLoader(ds_test, collate_fn=collate_optional_target)
Exporters (on-disk → other frameworks)
# mmsegmentation (img_dir / ann_dir / palette PNG; auto multiclass vs per-channel)
python -m anatomy_datasets.exporters.mmseg \
--splits ./datasets/drive/drive_splits.json --root ./datasets/drive \
--out ./exports/mmseg_drive
# COCO (mmdet / detectron2 / generic; auto-shards above 50k anns)
python -m anatomy_datasets.exporters.coco \
--splits ./datasets/paxray/paxray.json --root ./datasets/paxray \
--out ./exports/coco_paxray
# Sharded SA-1B per-image RLE JSON (lazy load; for PAXRay-scale instance seg)
python -m anatomy_datasets.formats.sharded_coco \
--splits ./datasets/paxray/paxray.json --root ./datasets/paxray \
--out ./exports/sharded_paxray --image-link-mode symlink
# HuggingFace DatasetDict (Python only, no CLI)
python -c "from anatomy_datasets.exporters import to_hf_dataset; \
to_hf_dataset('./datasets/drive/drive_splits.json', './datasets/drive')"
Adapters (runtime, no on-disk export)
# mmseg config side-effect import
custom_imports = dict(imports=["anatomy_datasets.adapters.mmseg"])
train_dataloader = dict(dataset=dict(
type="AnatomyMulticlassDataset",
splits_json="./datasets/drive/drive_splits.json",
split="train",
))
# mmdet config (reads from sharded export)
custom_imports = dict(imports=["anatomy_datasets.adapters.mmdet"])
train_dataloader = dict(dataset=dict(
type="ShardedCocoMMDetDataset",
sharded_root="./exports/sharded_paxray",
split="train",
))
Layout
src/anatomy_datasets/ # the importable package
base.py # BaseMultiClassDataset, BaseMultiLabelDataset, BaseDetectionDataset, collate_optional_target
datasets/ # per-dataset class aliases
transforms.py # get_transform / get_transform_det (albumentations)
registry.py # DATASET_REGISTRY (license / citation / modality / BibTeX)
postprocess.py # add_metadata_to_splits_json
stats.py # compute_image_stats
formats/sharded_coco.py # SA-1B-style writer + reader
exporters/{coco,mmseg,hf} # one-shot exporters + CLIs
adapters/{mmseg,mmdet} # runtime adapters (lazy lib imports)
src/prepare_data/prepare_<name>/ # per-dataset download / labels / splits / verify scripts
src/visualization/visualize.py # overlay helpers (no CLI; import or use verify scripts)
configs/{smp,mmseg,mmdet,hf}/ # copy-paste training templates
notebooks/ # Download_datasets.ipynb, Dataloader_example.ipynb
src/training/ # legacy backcompat shim (train.py example, deprecated)
Adding a dataset
- Add a
DatasetInfo(includingbibtex) tosrc/anatomy_datasets/registry.py. - Write
src/prepare_data/prepare_<name>/{download_<name>.py, prepare_<name>_splits.py, get_<name>_full.sh}. Splits script must calladd_metadata_to_splits_json(...)at the end. - Add an entry to
src/anatomy_datasets/_discovery.py(alias → class + env var + default JSON name). - Add a thin alias module under
src/anatomy_datasets/datasets/<name>.py. - Add
verify_<name>_visually.pyunder the prep dir and verify by loading + overlaying masks.
Caveats
- mmseg has no native multilabel. Use per-channel export (
--mode per_channel) orAnatomyMultilabelDatasetwithtarget_channel. - Sharded format currently only writes from
.npymultilabel sources; polygon/COCO passthrough is TODO. - COCO exporter is multilabel-only; for multiclass PNG datasets use the mmseg exporter.
- HF exporter has no CLI yet (Python function only).
- Some registry license fields are
"unknown"— check the source URL before commercial use.
License
This project: MIT. Each upstream dataset retains its own license — see the table above and the license / license_url fields in each splits JSON.
Citation
If you use any dataset prepared by this repo, cite the upstream paper. BibTeX is embedded in every splits JSON under the bibtex key, accessible via anatomy_datasets.get_dataset_info(name).bibtex.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file anatomy_datasets-0.1.0.tar.gz.
File metadata
- Download URL: anatomy_datasets-0.1.0.tar.gz
- Upload date:
- Size: 46.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
09c138d3ff936d6952c7b85bfebc1b2e8e3d866626372f37ebae6124fe67941c
|
|
| MD5 |
da23fdfaadc25b5848e9e990b9e21e75
|
|
| BLAKE2b-256 |
873654735578090b6b627e9be983cb49be63e13d135740e9f545b12af491b6ea
|
File details
Details for the file anatomy_datasets-0.1.0-py3-none-any.whl.
File metadata
- Download URL: anatomy_datasets-0.1.0-py3-none-any.whl
- Upload date:
- Size: 52.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ef376cac10eb4314c40fd16774290fd51a5d1a6f1e8c3189b58156cd281f93be
|
|
| MD5 |
a75997fc0669b70b1a47376d195c867a
|
|
| BLAKE2b-256 |
b69ac78c47887266c40e21e2ccf83a0e92d5a28e844842dec70833d35aff8f5b
|







