Anomaly Detection Framework allows us to calculate Anomalities on any Time - Series Data Sets. It has an interface which is easy to manage to train - predict with given dataset.

Project description
Anomaly Detection Framework


Anomaly-Detection-Framework is a platform for Time Series Anomaly Detection Problems. Give the data to the platform to get the Anomaly Labels with scheduled time periods. It is such simple is that!!! Anomaly-Detection-Framework enables to Data Science communities easy to detect abnormal values on a Time Series Data Set. It is a platform that can run on Docker containers as services or python by using its modules. It also has the web interface which allows us to train - prediction - parameter tuning jobs easily.
Key Features
-
Web Interface:
It is a web interface which allows us to connect data source and execute Machine Learning processes. You may create tasks according to your data set. These tasks are train models, Anomaly Detection Prediction, Parameter Tunning For Train Models.
-
Schedule Machine Learning Jobs:
Three main processes are able to initialized from platform Train, Prediction, and Parameter Tuning. Each Process can be scheduled Daily, Monthly, Weekly Hourly, etc with given time. In addition to that, you may run your Machine Learning processes in real-time.
-
Dashboard Visualization:
When your data have been connected to a data source and assign Date Indicator, Model Dimensions (optional), and feature column from Create Task Menu Create Task, you may see the dashboard from Dashboard Menu.
-
Data Sources: Here is the data source that you can connect with your SQL queries:
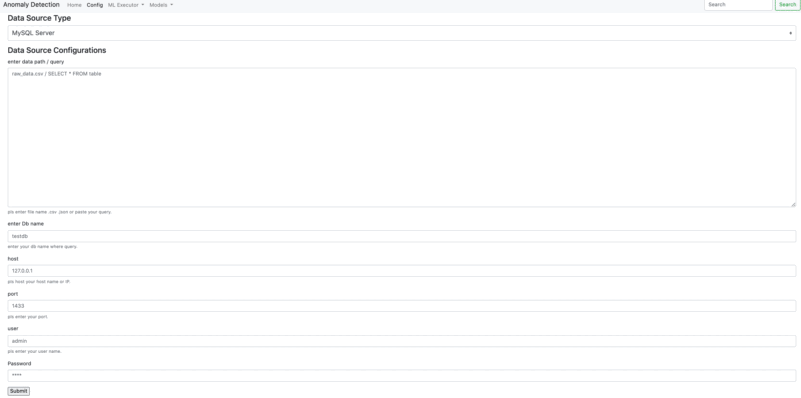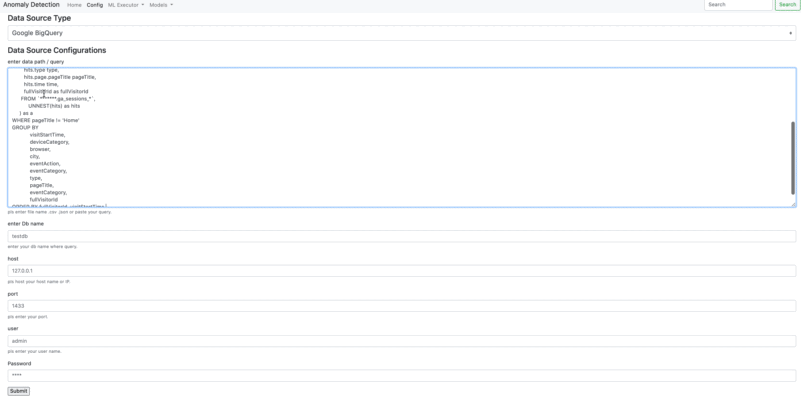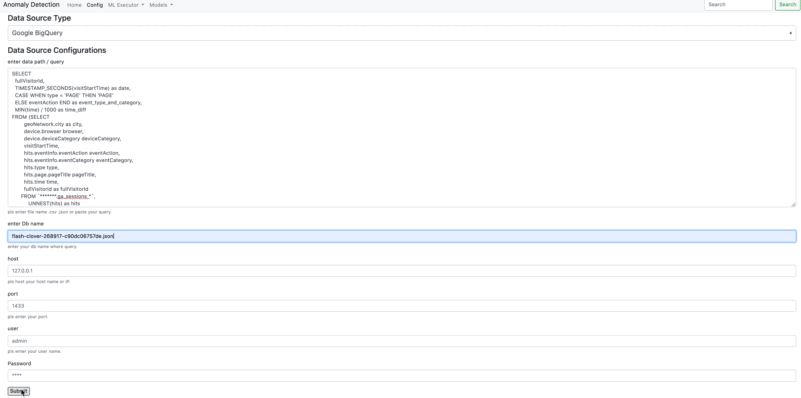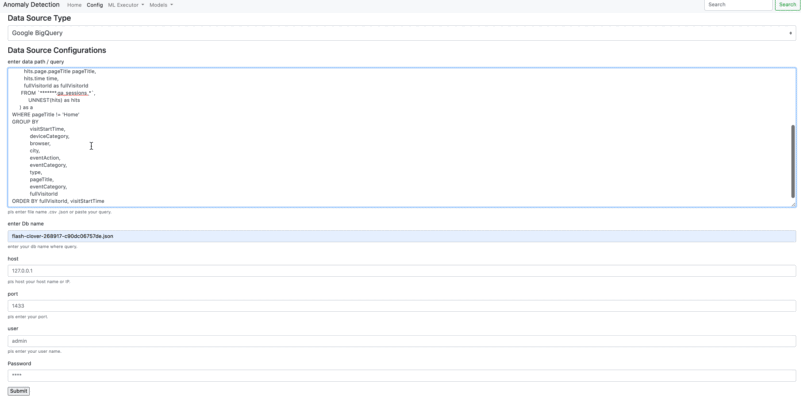
- Ms SQL Server
- PostgreSQL
- AWS RedShift
- Google BigQuery
- .csv
- .json
- pickle
-
Models:
There are 2 Anomaly Detection Algorithm and FBProphet Anomaly Detection Solution which are running on the platform.
- LSTM
- FBProphet
- Isolation Forest
-
API Services:
There are 4 Services run on the platform.
- Machine Learning Schedule Services
- LSTM Model Service
- FbProphet Model Service
- Isolation Foreset model Service
-
Docker Compose Integration (Beta):
These 4 containers are running on containers as services.
- ml_executor-services
- model-services-iso_f
- model-services-lstm
- model-services-prophet
Running Platform
1. You have to specify you directory
from anomaly_detection import ad_execute as ad_exec
ad = ad_exec.AnomalyDetection(path='./Desktop', environment='local)
ad.init(apis=None)
Once, you have assigned the path, a folder called Anomaly_Detection_Framework will be created inside of it. This folder includes models, data, logs, and docs folders.Trained models will be imported to the models folder. logs folder for both ml_execute, model_iso_f, model_prophet, and model_lstm of log files will be created at logs file. Your .csv, .json or .yaml data source file must be copied to the data folder which is at the Anomaly_Detection_Framework folder. If you are connecting to Google Big Query data source, Big Query API (.json file) must be copied into the "data" folder. Once, prediction jobs have been initialized output .csv file is imported to the data folder.
The given path will be your workspace where all data-source you can store or get from it. By using "AnomalyDetection" module of path argument you can specify the path. If there are files which are already exists on the given path, you may remove them by using remove_existed = True (default False)
-
anomaly_detection.AnomalyDetection:
-
AnomalyDetection
path : The location where you are willing to create models and prediction data set.
*enviroment : local or docker
host : local or docker
remove_existed : remove data from the location where you have entered as a path.
master_node : if False, you must enter the services of information manually (port host, etc.). This allows the user to initialize each service on different locations or servers or workers. If False there will not be a web interface. Once you create a master node, in order to use other services, you have to clarify these services on it. The master node will lead the other services which has additional web interface service that runs on it
-
init
This initializes the folders. Checks the available ports for services in the range between 6000 - 7000. Updates the apis.yaml if it is necessary.
apis :
services = { 'model_iso_f': {'port': 6000, 'host': '127.0.0.1'}, 'model_lstm': {'port': 6001, 'host': '127.0.0.1'} } ad = ad_exec.AnomalyDetection(path='./Desktop', environment='local, master_node=False) ad.init(apis=services)Example above, It will initializes model_iso_f and model_lstm services. Both will be run on a given host with given ports. However given ports are used, it will assign another port automatically.
-
2. Run The PLatform
ad.run_platform()
This process initializes the platform. Once you have run the code above you may have seen the services are running. If you assign master_node = True you may use enter to web interface from http://127.0.0.1:7002/. If 7002 port is used from another platform directly platform assigns +1 port. (7003,7004, 7005, ..)
2. Data Source
You can connect to data source from Data Source Configuraitons. There is two option to connect to a data source. You can integrate on the web interface or you can use AnomalyDetection method in order to able to connect a data source.
from anomaly_detection import ad_execute as ad_exec
# create your platform folders.
ad = ad_exec.AnomalyDetection(path='./Desktop', environment='local')
# copy folders
ad.init()
# initialize services
ad.run_platform()
# create data source with Google BigQuery
ad.create_data_source(data_source_type='googlebigquery',
data_query_path="""
SELECT
fullVisitorId,
TIMESTAMP_SECONDS(visitStartTime) as date,
CASE WHEN type = 'PAGE' THEN 'PAGE'
ELSE eventAction END as event_type_and_category,
MIN(time) / 1000 as time_diff
FROM (SELECT
geoNetwork.city as city,
device.browser browser,
device.deviceCategory deviceCategory,
visitStartTime,
hits.eventInfo.eventAction eventAction,
hits.eventInfo.eventCategory eventCategory,
hits.type type,
hits.page.pageTitle pageTitle,
hits.time time,
fullVisitorId as fullVisitorId
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*`,
UNNEST(hits) as hits
) as a
WHERE pageTitle != 'Home'
GROUP BY
visitStartTime,
deviceCategory,
browser,
city,
eventAction,
eventCategory,
type,
pageTitle,
eventCategory,
fullVisitorId
ORDER BY fullVisitorId, visitStartTime
""",
db='flash-clover-**********.json',
host=None,
port=None,
user=None,
pw=None)
Example above, it is created a connector to Google BigQuery by using AnomalyDtection method.
- Connection PostgreSQL - MS SQL
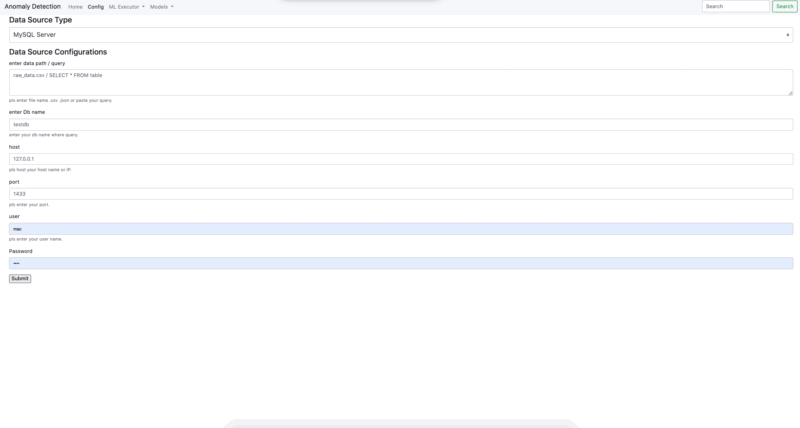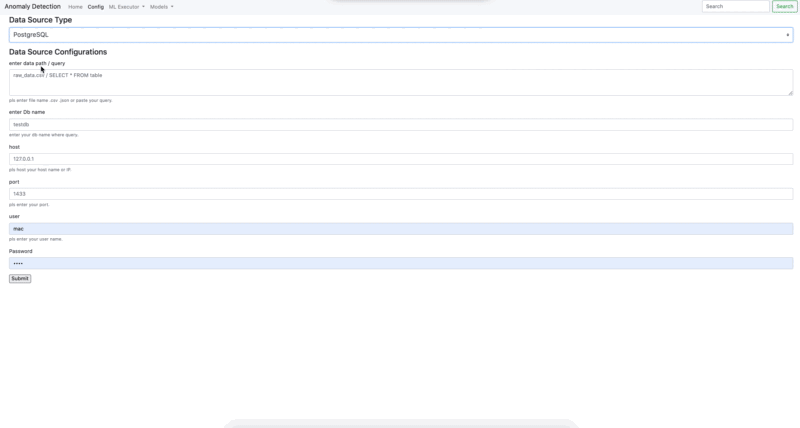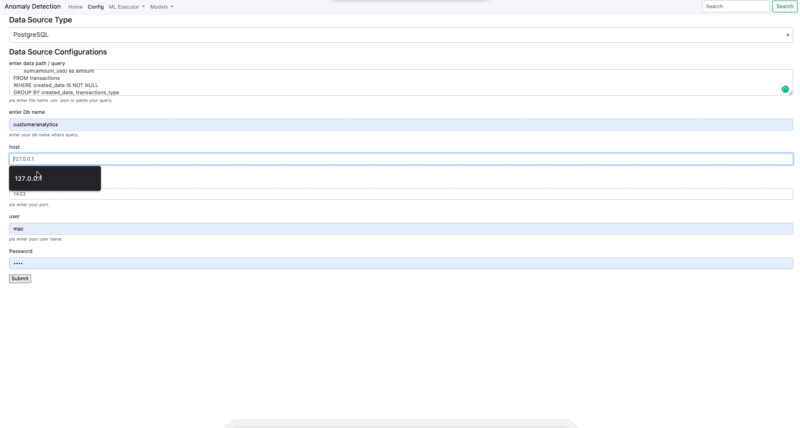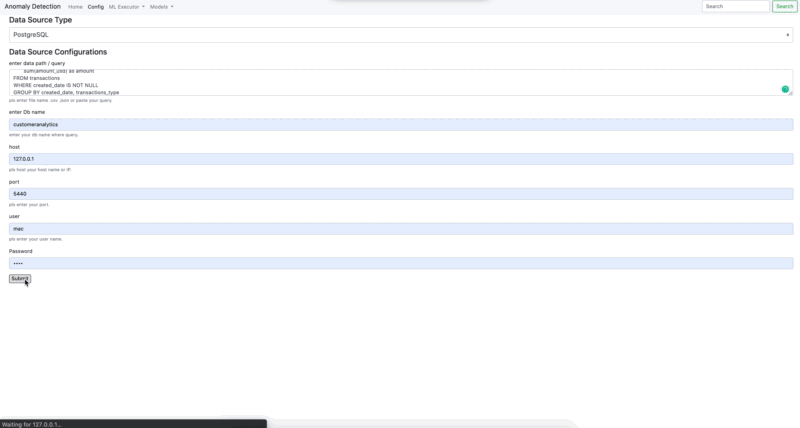
- Connection .csv - .json - .yaml
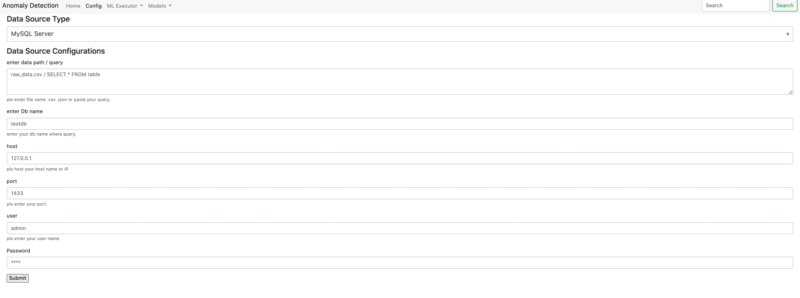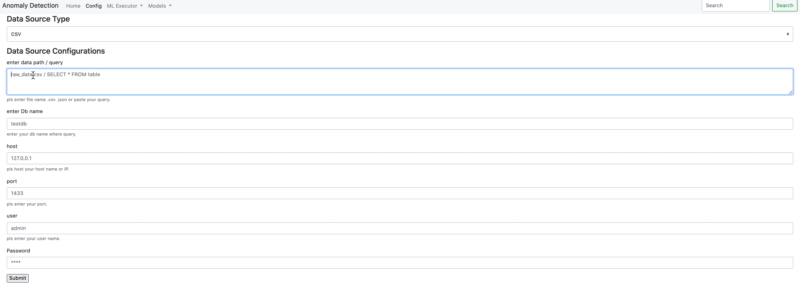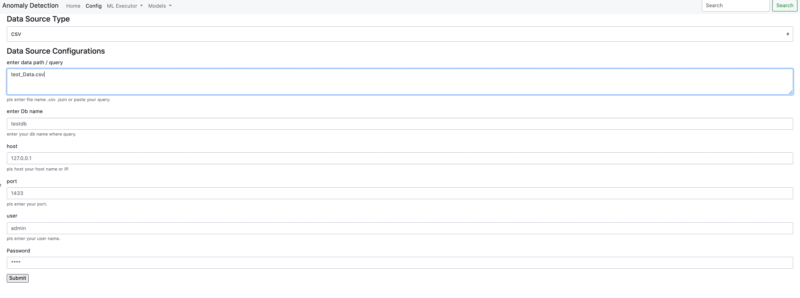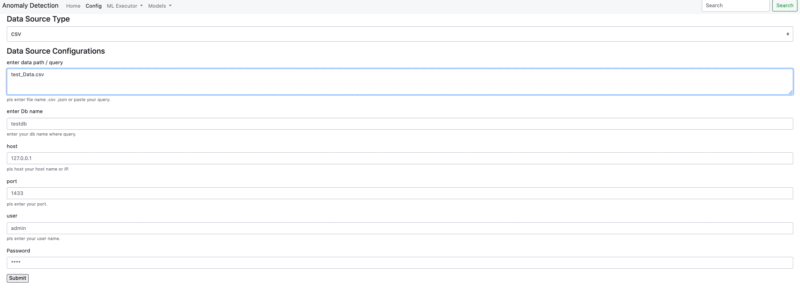
- Connection Google BigQuery
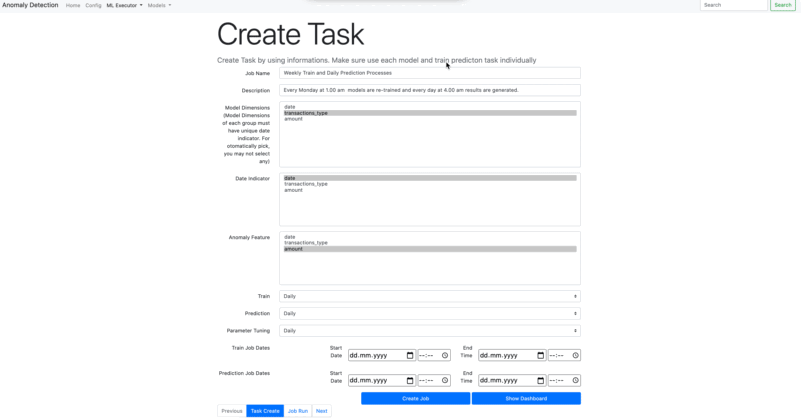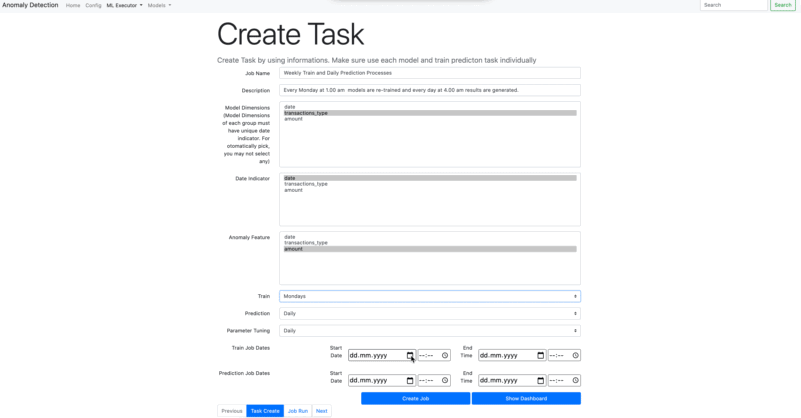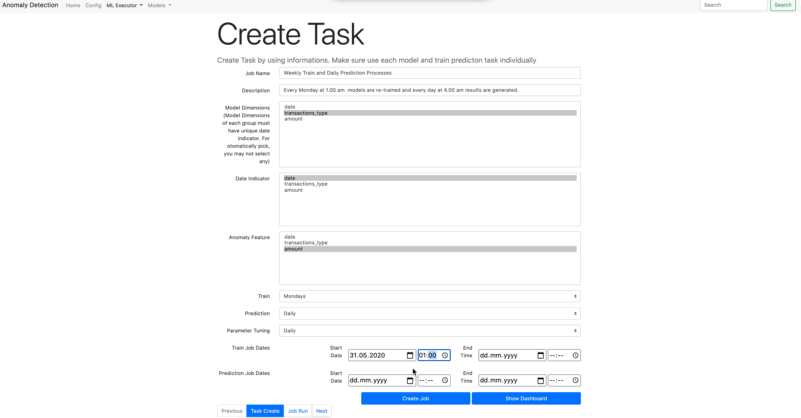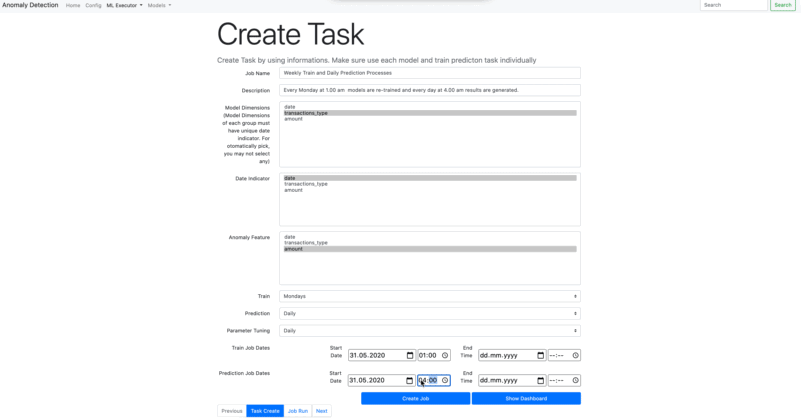
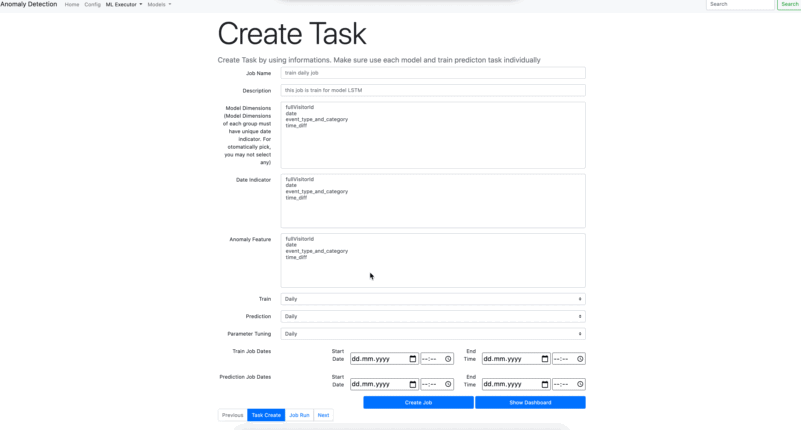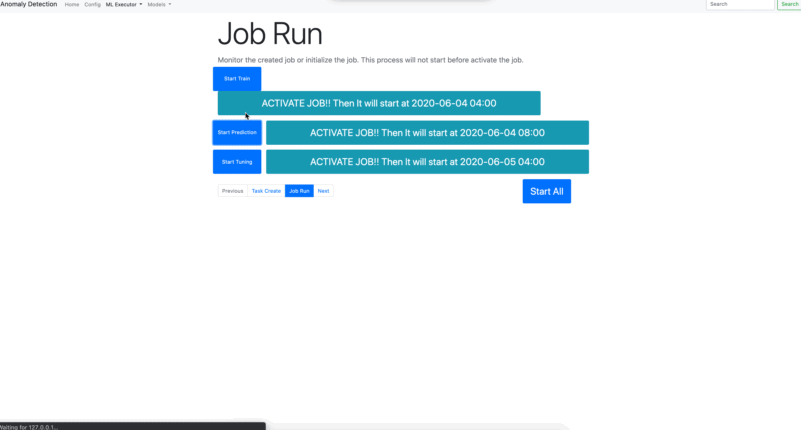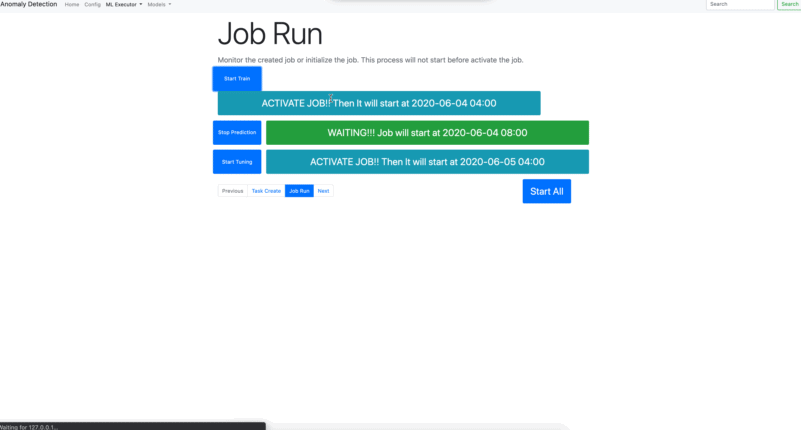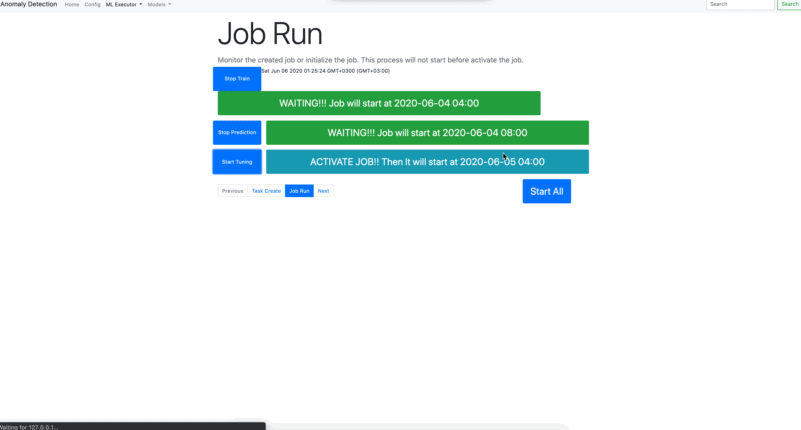
- Create Tasks
-
Model Dimensions : You may want to Train your model with separated Groups. The platform automatically finds the date part as dimensions from the Date Indicator. However external dimension can be included by assigning from here.
-
Date Indicator : You have to specify the date column from your raw data set. This is a mandatory field.
-
Anomaly Feature : In order to find the anomaly values, you have to specify which column we are investigating for. This is a mandatory field.
-
Train : Choose the schedule time period for train task. The chosen period will be started depending on the time where it is assigned at Train Job Dates - Start*. If Train Job Dates - Start* is not assigned, the job date will automatically assign as the current date and it can be started immediately. Parameter Tunning also runs when train task runs for the first time.
-
Prediction : As like Train Task, Prediction task also be scheduled similar way. However, you have to assign ***Prediction Job Dates - Start *** while you are creating task.
-
Parameter Tuning : Parameter Tuning also is able to be scheduled. However, the starting date is assigning related to Train Job Dates - Start. Parameter tunning also runs when train task runs for the first time.
-
Here are the schedule options :
-
Daily : Each day, the job process will start with a given time where you assign at Train Job Dates - Start.
-
only once : It can be triggered just once.
-
Mondays ... Sundays : Assigned day of the week, the job will start.
-
Weekly : Job will run every 7 days after it is started.
-
Every 2 Weeks : 14 days of the time period.
-
Monthly : every 30 days of the time period.
-
Every Minute : Every minute job can be triggered.
-
Every Second : Every each second job can be triggered.
-
-
You can create 3 main Machine Learning task which generally uses for each Data Scientist. You may create a task and schedule them separately. For instance, train can run every week, prediction can create outputs daily, and every each month parameters can be optimized by parameter tunning task.
This process is only available after Data Source is created. Once you create the data source you can see the column names on Model Dimensions, Date Indicator, Anomaly Feature. You can not create tasks separately.
- Job Run
Once, you create tasks, jobs are eligible to run periodically. You can also run below codes rather than using application interface;
ad.manage_train(stop=False)
ad.manage_prediction(stop=False)
ad.manage_parameter_tuning(stop=False)
*** AnomalyDetection.manage_train :***
- stop : If False stops running training scheduled task.
*** AnomalyDetection.manage_prediction :***
- stop : If False stops running prediction scheduled task.
*** AnomalyDetection.manage_parameter_tuning :***
- stop : If False stops running parameter tuning scheduled task.
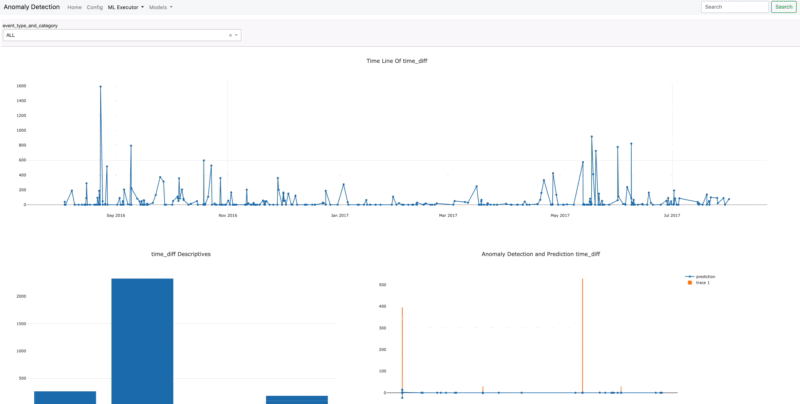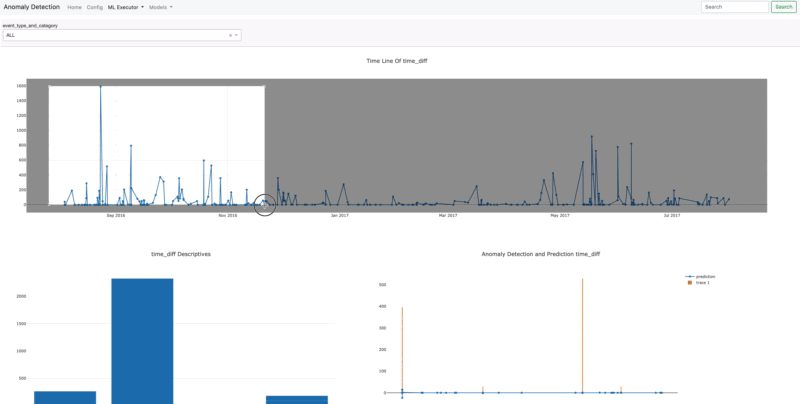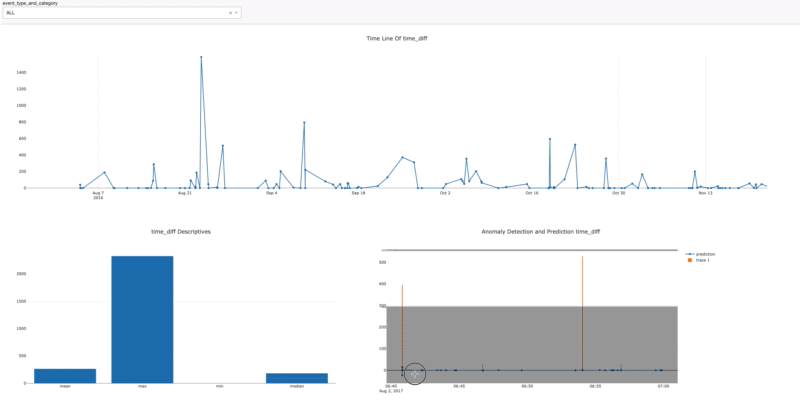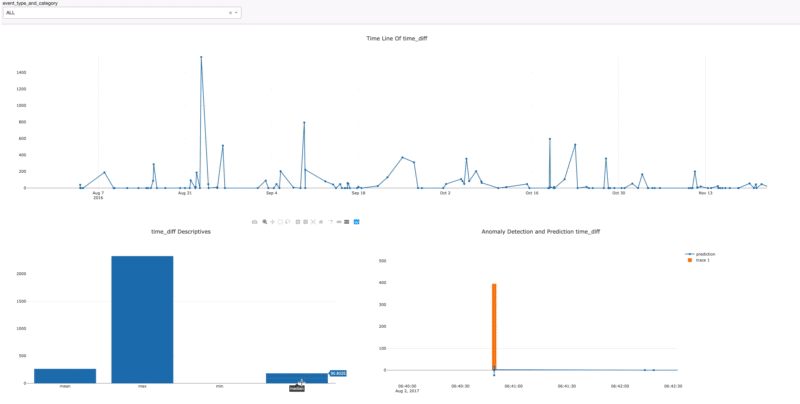
- Dashboard
Once you assign the data source connection and create the task automatically, the dashboard will be created directly according to the model dimension. After Data Source and Create Task are done, in order to initialize the platform with the code below;
ad = anomaly_detection.Ad_execute.AnomalyDetection(path='./Desktop', environment='local').reset_web_app()
ad.reset_web_app()
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file anomaly_detection_framework-0.0.21.tar.gz.
File metadata
- Download URL: anomaly_detection_framework-0.0.21.tar.gz
- Upload date:
- Size: 81.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.5.0 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.61.0 CPython/3.9.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e216721dfb4257ecd7bc21be7e692c4e8cbaee6f51d6f27cb0d2c422ca169409
|
|
| MD5 |
4b18595766e379e666733de5b7ec8ee5
|
|
| BLAKE2b-256 |
468d117030c79a21530c61b51ab153f44bd15aebe440f8fe4422df22f18a721f
|







