No project description provided

Reason this release was yanked:
wrong dependencies
Project description
APPLYBN

Создано с помощью инструментов и технологий:


applybn — это многоцелевой фреймворк с открытым исходным кодом, основанный на байесовских сетях и каузальных моделях.
Он представляет анализ данных, основанный на понятных и интерпретируемых алгоритмах байесовских сетей и каузальных моделей.
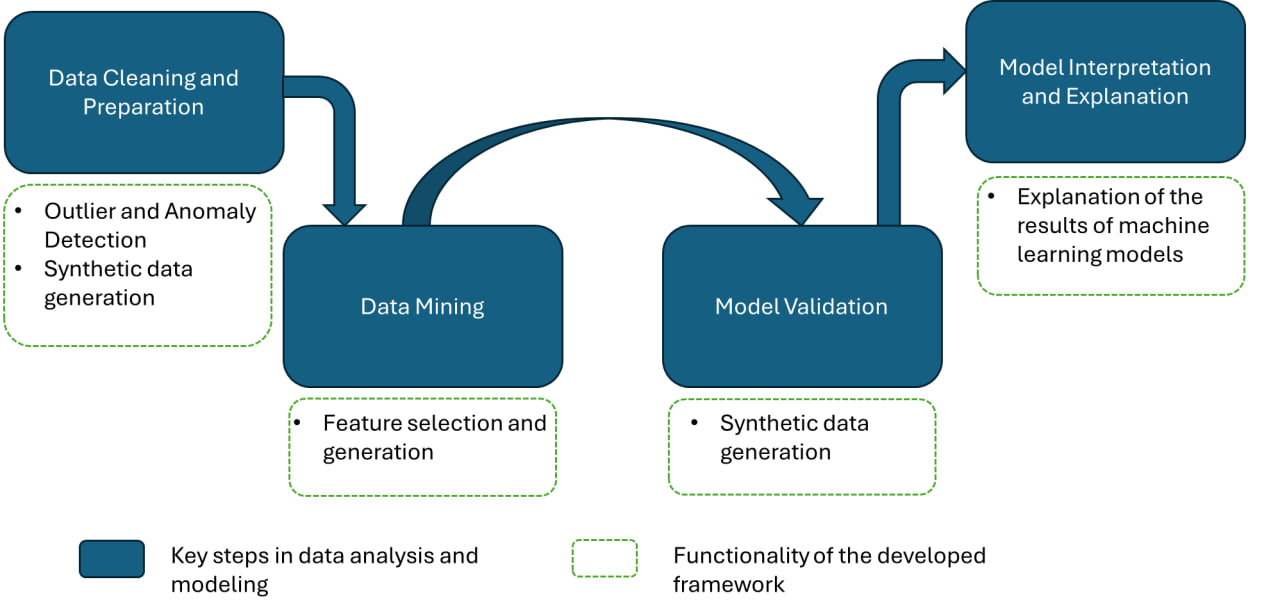
Ключевые особенности
1. Обнаружение аномалий во временных рядах и табличных данных
Табличные данные
- Метод сочетает в себе обнаружение на основе условных распределений байесовской сети и оценку на основе близости.
- Метод позволяет выявлять как выбросы по плотности, так и выбросы, возникающие из-за нарушения зависимостей между признаками.
Временные ряды
- Метод выявляет выбросы в многомерных временных рядах, используя динамические байесовские сети (DBN) для моделирования временных и межпеременных зависимостей.
- Его ключевые преимущества заключаются в улавливании сложных временных взаимозависимостей, автоматизации классификации выбросов с помощью адаптивных стратегий анализа оценок.
2. Генерация синтетических данных
- Фреймворк включает методы для генерации синтетических обучающих данных при обнаружении дисбаланса классов в наборе данных. Используя гибридные байесовские сети (с моделями гауссовых смесей), он генерирует сбалансированные синтетические данные, улучшая результаты обучения моделей.
- Метод позволяет учитывать взаимодействия между переменными, что повышает качество синтетических данных.
3. Отбор и извлечение признаков
Отбор признаков на основе причинно-следственного эффекта
- Этот метод количественно оценивает причинно-следственные эффекты с помощью теории информации и пост-нелинейных моделей, автоматически выбирая признаки с ненулевым причинным влиянием на ключевые показатели эффективности (KPI) путем анализа снижения неопределенности в энтропии.
- Метод отличается интерпретируемостью и стабильностью, отдавая приоритет причинно-следственным связям, избегает ручной настройки пороговых значений и надежно работает даже с ограниченными или нелинейными промышленными данными, повышая надежность программных датчиков.
Отбор признаков на основе нормализованной взаимной информации
- Метод сочетает отбор признаков с правилами Мика для выявления марковских покрытий, используя взаимную информацию для сохранения узлов со значительными зависимостями и отсеивания нерелевантных или избыточных признаков в байесовских сетях.
- Его ключевые преимущества включают эффективную обработку высокоразмерных данных за счет сосредоточения на локальных структурах, повышенную точность по сравнению с традиционными методами.
Извлечение признаков на основе байесовских сетей
- Метод работает путем вывода условных зависимостей между признаками с использованием байесовских сетей и добавления вероятностных параметров (λ), представляющих эти зависимости, в исходный набор данных.
- Его преимущества включают повышенную точность классификации в различных областях, снижение зависимости от априорных знаний и низкую вычислительную сложность, что обеспечивает надежное и интерпретируемое обогащение признаков без ограничений, специфичных для предметной области.
4. Объяснимый анализ
Причинно-следственный анализ для моделей машинного обучения
- Метод анализа компонентов модели - строится структурная каузальная модель (SCM) для анализа моделей глубокого обучения, что позволяет отсеивать неважные части (например, фильтры в CNN) путем оценки их причинной важности.
- Метод объяснения влияния данных на прогнозы позволяет делать причинно-следственные выводы между признаками и показателями уверенности модели. Рассчитывая средний причинный эффект (ACE), он помогает определить, какие признаки значительно влияют на неопределенность модели, предоставляя ценную информацию для улучшения или отладки моделей.
5. Совместимость со Scikit-learn
Все оценщики и преобразователи данных совместимы со scikit-learn.
Направления прикладного использования
Ниже приведён обобщённый перечень направлений прикладного использования фреймворка applybn на основе его ключевых возможностей:
Обнаружение аномалий
-
Финансы и банковская сфера: выявление мошеннических транзакций и отклонений в поведении клиентов на основе табличных и временных данных.
-
Промышленный мониторинг и предиктивное обслуживание: раннее обнаружение отклонений в работе оборудования (например, датчиков на производственной линии) с учётом сложных временных зависимостей.
-
Кибербезопасность: детектирование нетипичных событий в логах и сетевом трафике, нарушений привычных зависимостей между признаками.
Генерация синтетических данных
-
Преодоление дисбаланса классов: дополнение малочисленных классов в датасете (например, при классификации редких заболеваний или редких отказов в оборудовании).
-
Конфиденциальность и защита персональных данных: создание «псевдо‑данных» для разработки и тестирования без утраты статистических свойств оригинала.
Отбор и извлечение признаков
-
Классификация и прогнозирование в бизнес-аналитике: автоматический выбор только причинно значимых факторов, влияющих на ключевые метрики (KPI), без ручной настройки порогов.
-
Биоинформатика и медицина: отбор генов или клинических маркёров на основе причинных эффектов и взаимной информации при ограниченных размерах выборки.
-
Рекомендательные системы: выявление наиболее релевантных факторов поведения пользователей для повышения качества рекомендаций.
Объяснимый анализ моделей (Explainable AI)
-
Debug и оптимизация нейронных сетей: анализ важности компонентов (фильтров, слоёв) через структурную каузальную модель, отсечение несущественных элементов.
-
Регулирование и отчётность: формализация вклада каждого признака в предсказание модели для соответствия требованиям «чёрного ящика» (например, в страховании или кредитовании).
Интеграция в ML‑конвейеры
-
Полная совместимость со Scikit‑learn: применение в пайплайнах вместе с другими пре- и пост‑обработчиками, перекрёстная валидация, grid‑search, имплементация в sklearn.Pipeline/imblearn.Pipeline.
-
Конвейеры для задач классификации: объединение этапов синтетической генерации, отбора признаков, ресемплинга и обучения модели в единую цепочку обработки.
Образовательные и исследовательские задачи
-
Курсы по машинному обучению, демонстрация работы байесовских сетей и динамических каузальных моделей (DBN).
-
Научные исследования в области каузального анализа: тестирование и сравнение методов отбора на основе причинно-следственных эффектов.
Технические требования
OS: Linux/MacOS/Windows Python version: 3.11/3.12
Требования к железу аналогичны требованиям Pytorch в зависимости от использования GPU/CPU/MPS.
Установка
Чтобы начать работу с applybn, клонируйте репозиторий и установите необходимые зависимости.
- Установите менеджер пакетов uv
# On macOS and Linux.
curl -LsSf https://astral.sh/uv/install.sh | sh
# On Windows.
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
- Клонируйте репозиторий и установите зависимости с помощью uv
git clone https://github.com/Anaxagor/applybn.git
cd applybn
uv pip install -r pyproject.toml
Пример конвейера Scikit-learn
Пример, демонстрирующий, как использовать несколько компонентов из библиотеки applybn в Pipeline, совместимом со scikit-learn. Мы рассмотрим отбор признаков, генерацию признаков, ресемплирование для несбалансированных наборов данных и обнаружение аномалий.
import pandas as pd
import numpy as np
import warnings
import logging
import sys
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import KBinsDiscretizer
from imblearn.pipeline import Pipeline as ImbPipeline
from sklearn.linear_model import LogisticRegression
from applybn.feature_selection.ce_feature_selector import CausalFeatureSelector
from applybn.feature_extraction.bn_feature_extractor import BNFeatureGenerator
from applybn.imbalanced.over_sampling.bn_over_sampler import BNOverSampler
from applybn.anomaly_detection.static_anomaly_detector.tabular_detector import TabularDetector
warnings.filterwarnings('ignore')
logging.getLogger().setLevel(logging.CRITICAL)
logging.disable(logging.CRITICAL)
logging.getLogger('applybn').setLevel(logging.CRITICAL)
logging.getLogger('applybn').disabled = True
class NullWriter:
def write(self, txt): pass
def flush(self): pass
original_stderr = sys.stderr
sys.stderr = NullWriter()
class CausalFeatureSelector2(CausalFeatureSelector):
def fit(self, X, y):
super().fit(X, y)
self.selected_features_mask_ = self.get_support()
return self
def transform(self, X):
return X.iloc[:, self.selected_features_mask_]
def generate_example_data(n_samples=200, n_features=5, n_cat_features=2, target_name='target_class', imbalance_ratio=0.1, random_state=42):
"""Генерирует синтетический несбалансированный набор данных."""
rng = np.random.RandomState(random_state)
X_cont_data = rng.rand(n_samples, n_features - n_cat_features)
cont_feature_names = [f'cont_feature_{j}' for j in range(n_features - n_cat_features)]
X_cont_df = pd.DataFrame(X_cont_data, columns=cont_feature_names)
X_cat_df = pd.DataFrame()
for i in range(n_cat_features):
cat_feature_name = f'cat_feature_{i}'
temp_cont_for_cat = rng.rand(n_samples)
n_bins_cat = rng.randint(2, 4)
discretizer = KBinsDiscretizer(n_bins=n_bins_cat, encode='ordinal', strategy='uniform', subsample=None, random_state=rng)
# Сохраняем категориальные признаки как целые числа
X_cat_df[cat_feature_name] = discretizer.fit_transform(temp_cont_for_cat.reshape(-1, 1)).ravel().astype(int)
X_df = pd.concat([X_cont_df, X_cat_df], axis=1)
n_class1 = int(n_samples * imbalance_ratio)
n_class0 = n_samples - n_class1
y_array = np.array([0] * n_class0 + [1] * n_class1)
rng.shuffle(y_array)
y_series = pd.Series(y_array, name=target_name, dtype=int)
return X_df, y_series
# --- Основной пример ---
TARGET_NAME = 'target_class_example'
# 1. Генерация данных
print("1. Генерация синтетических данных...")
X_df, y_s = generate_example_data(n_samples=250, n_features=6, n_cat_features=2, target_name=TARGET_NAME, imbalance_ratio=0.15, random_state=42)
X_train_df, X_test_df, y_train_s, y_test_s = train_test_split(X_df, y_s, test_size=0.3, random_state=42, stratify=y_s)
print(f" Обучающие данные: {X_train_df.shape}, Тестовые данные: {X_test_df.shape}")
print(f" Распределение целевой переменной (обучение):\n{y_train_s.value_counts(normalize=True).to_string()}\n")
# 2. Обработка данных с обнаружением аномалий
X_train_df = X_train_df.reset_index(drop=True)
y_train_s = y_train_s.reset_index(drop=True)
X_test_df = X_test_df.reset_index(drop=True)
y_test_s = y_test_s.reset_index(drop=True)
detector = TabularDetector(target_name=TARGET_NAME, additional_score="IF")
X_train_df[TARGET_NAME] = y_train_s
detector.fit(X_train_df)
scores = detector.predict_scores(X_train_df)
threshold = np.percentile(scores, 95)
mask = scores <= threshold # Выбираем 5% самых аномальных примеров
X_train_df = X_train_df[mask]
y_train_s = X_train_df[TARGET_NAME]
y_train_s = y_train_s.reset_index(drop=True)
X_train_df = X_train_df.drop(columns=[TARGET_NAME])
X_train_df = X_train_df.reset_index(drop=True)
# 3. Создание полного конвейера с отбором признаков, генерацией признаков, передискретизацией и классификацией
processing_pipeline = ImbPipeline([
('feature_selector', CausalFeatureSelector2(n_bins=3)),
('bn_features', BNFeatureGenerator()),
('oversampler', BNOverSampler(class_column=TARGET_NAME, strategy='max_class', shuffle=True)),
('classifier', LogisticRegression(solver='liblinear', random_state=42))
])
# 4. Обучение и оценка конвейера
print("\n2. Обучение полного конвейера...")
processing_pipeline.fit(X_train_df, y_train_s)
pipeline_score = processing_pipeline.score(X_test_df, y_test_s)
print(f" Точность конвейера на тестовых данных: {pipeline_score:.4f}\n")
print("\n--- Пример завершен ---")
Помощь и поддержка
Документация с примерами
Документацию с примерами можно найти здесь.
Связь
Не стесняйтесь создавать новые задачи.
Если у вас есть вопросы или предложения, вы можете связаться с нами по следующим ресурсам:
- Helpdesk в чате Telegram
- ideeva@itmo.ru (Ирина Деева)
Участие в разработке
Вклад в applybn приветствуется! Если вы заинтересованы в улучшении каких-либо функций или тестировании новых веток, пожалуйста, ознакомьтесь с разделом Как внести вклад документации.
Лицензия
applybn распространяется под лицензией MIT. Дополнительную информацию см. в файле LICENSE.
Цитирование
@software{applybn,
author = {Irina Deeva},
title = {applybn},
url = {https://github.com/Anaxagor/applybn},
version = {0.1.0},
date = {2025-05-03},
}
Благодарности
Проект поддержан Фондом содействия инновациям.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file applybn-0.1.0.tar.gz.
File metadata
- Download URL: applybn-0.1.0.tar.gz
- Upload date:
- Size: 211.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
129b2c8e7789704fe4c13bab89cba31b79eb05ce4b2b47ff7ae1bbef3ab47564
|
|
| MD5 |
15000a09832d1d360cd4dbc6feffae46
|
|
| BLAKE2b-256 |
ec93bdd9547939614371f0e2a2f58e64da116217c1cbb3103cd1b5c6efc607d3
|
File details
Details for the file applybn-0.1.0-py3-none-any.whl.
File metadata
- Download URL: applybn-0.1.0-py3-none-any.whl
- Upload date:
- Size: 220.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
af12a1e0c6b68e28116ab31a56b461f040a4da424cfb85d6c111ed10a914f93f
|
|
| MD5 |
165b5e6f9fc55503aa99a2e82e30ea5f
|
|
| BLAKE2b-256 |
86471e9c833f7ca87795580c70dd60bff70541e2622138ee6b9dd27be7ac3abb
|







