Advanced Pipeline for Simple yet Comprehensive AnaLysEs of DNA metabarcoding data - Nanopore application

Project description
apscale
Advanced Pipeline for Simple yet Comprehensive AnaLysEs of DNA metabarcoding data


apscale-blast
Introduction
Apscale-blast is part of the metabarcoding pipeline apscale and is used for the taxonomic assignment of OTUs or ESVs.
Programs used:
- blast+ (blastn module)
Input:
- sequence fasta files (containing OTUs/ESVs) generated with Apscale (or any other metabarcoding pipeline)
Output:
- taxonomy table, log files
Installation
Apscale-blast can be installed on all common operating systems (Windows, Linux, MacOS). Apscale-blast requires Python 3.10 or higher and can be easily installed via pip in any command line:
pip install apscale_blast
To update apscale-blast run:
pip install --upgrade apscale_blast
The easiest installation option is the Conda apscale environment. This way, all dependencies will automatically be installed.
Further dependencies - blast+
Apscale-blast calls blast+ (blastn) in the background. It should be installed and be in PATH to be executed from anywhere on the system. However, a PATH to the executable can also be provided within the command.
You can find the latest blast+ executables and further information on the installation here.
IMPORTANT: Please cite the blast+ software.
Camacho, C., Coulouris, G., Avagyan, V., Ma, N., Papadopoulos, J., Bealer, K., & Madden, T. L. (2009). BLAST+: Architecture and applications. BMC Bioinformatics, 10, 421. https://doi.org/10.1186/1471-2105-10-421
Available databases
Apscale-blast uses pre-compiled databases. These databases will be tested and should prevent user-error. However, custom databases can also be created using these scripts, which are used to create the pre-compiled databases.
The pre-compiled databases are available under the following server and will be updated regularly.
IMPORTANT: Please cite the used database accordingly!
How to use
Start
- Open a terminal, powershell, or command line window. To view the help page type:
apscale_blast -h
Blastn search & filtering
- Apscale blast can be initialized by calling:
apscale_blast
- You will be asked to provide the FULL PATH to your database. Enter the PATH in the command line. For example:
/Users/tillmacher/Downloads/MIDORI2_UNIQ_NUC_GB260_srRNA_BLAST
- Next, you will be asked to provide the FULL PATH to your query fasta file that contains the OTU/ESV sequences. Enter the PATH in the command line. For example:
/Users/tillmacher/Downloads/test_data_OTUs.fasta
-
Apscale-blast will split your fasta into smaller subsets [DEFAULT: 100].
-
Each subset fasta file will be seperately blasted in parallel [DEFAULT: CPU count - 1].
-
A new folder is created containing the unfiltered blastn results:
├───test_data_OTUs.fasta
└───test_data_OTUs
├───IDs.txt
├───log.txt
├───test_data_OTUs.parquet.snappy
└───subsets
├───subset_1_blastn.csv
├───subset_2_blastn.csv
├───subset_3_blastn.csv
└───subset_4_blastn.csv
- Apscale-blast will automatically filter the blastn results according to the following criteria:
- By e-value (the e-value is the number of expected hits of similar quality which could be found just by chance):
- The hit(s) with the lowest e-value are kept (the lower the e-value the better).
- By taxonomy:
- Hits with the same taxonomy are dereplicated.
- Hits are adjusted according to thresholds (default: species >=98%, genus >=95%, family >=90%, order >=85%) and dereplicated.
- Hits with still conflicting taxonomy are set back to the most recent common taxonomy
- OTU without matches in the blastn search are re-added as 'No Match'
- The results are collected and written to an new Excel file.
├───test_data_OTUs.fasta
└───test_data_OTUs
├───IDs.txt
├───log.txt
├───test_data_OTUs_taxonomy.xlsx <-- Filtered taxonomic identification results!
├───test_data_OTUs.parquet.snappy
└───subsets
├───subset_1_blastn_filtered.xlsx
├───subset_1_blastn.csv
├───subset_2_blastn_filtered.xlsx
├───subset_2_blastn.csv
├───subset_3_blastn_filtered.xlsx
├───subset_3_blastn.csv
├───subset_4_blastn_filtered.xlsx
└───subset_4_blastn.csv
Options
BLASTn & Filtering
options:
-h, --help: show this help message and exit
-database DATABASE, -db DATABASE: PATH to local database. Use "remote" to blast against the complete GenBank database (might be slow)
-blastn_exe BLASTN_EXE: PATH to blast executable. [DEFAULT: blastn]
-query_fasta QUERY_FASTA, -q QUERY_FASTA: PATH to fasta file.
-n_cores N_CORES: Number of CPU cores to use. [DEFAULT: CPU count - 1]
-task TASK: Blastn task: blastn, megablast, or dc-megablast. [DEFAULT: blastn]
-out OUT, -o OUT: PATH to output directory. A new folder will be created here. [DEFAULT: ./]
-subset_size SUBSET_SIZE: Number of sequences per query fasta subset. [DEFAULT: 100]
-max_target_seqs MAX_TARGET_SEQS: Number of hits retained from the blast search. Larger values increase runtimes and storage needs. [DEFAULT: 20]
-masking MASKING: Activate masking [DEFAULT="Yes"]
-thresholds THRESHOLDS: Taxonomy filter thresholds. [DEFAULT: 97,95,90,87,85]
-update_taxids, -u Update NCBI taxid backbone
Remote blast
Apscale blast allows the automatical usage of the NCBI blastn webpage, including the filtering of raw hits and creation of taxonomy table.
NCBI Genbank is a public resource, so usage limitations apply to this script. Datasets that involve large numbers of BLAST searches should use one of the provided local databases.
Requests will be rate-limited to 10 requests per day (1000 sequences) to avoid overloading the server.
Run the remote blast on weekends or between 9 pm and 5 am Eastern time on weekdays.
Benchmark
v1.0.2 with db release 2024_09
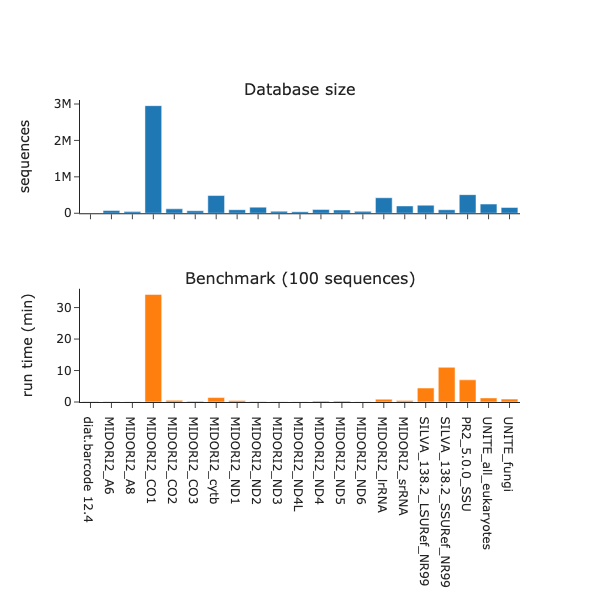
Databases
Midori2
Leray, M., Knowlton, N., & Machida, R. J. (2022). MIDORI2: A collection of quality controlled, preformatted, and regularly updated reference databases for taxonomic assignment of eukaryotic mitochondrial sequences. Environmental DNA, 4(4), 894–907. https://doi.org/10.1002/edn3.303
Unite
Nilsson, R. H., Larsson, K.-H., Taylor, A. F. S., Bengtsson-Palme, J., Jeppesen, T. S., Schigel, D., Kennedy, P., Picard, K., Glöckner, F. O., Tedersoo, L., Saar, I., Kõljalg, U., & Abarenkov, K. (2019). The UNITE database for molecular identification of fungi: Handling dark taxa and parallel taxonomic classifications. Nucleic Acids Research, 47(D1), Article D1. https://doi.org/10.1093/nar/gky1022
When using the all eukaryote database, please cite it as follows:
Abarenkov, Kessy; Zirk, Allan; Piirmann, Timo; Pöhönen, Raivo; Ivanov, Filipp; Nilsson, R. Henrik; Kõljalg, Urmas (2024): UNITE general FASTA release for eukaryotes 2. Version 04.04.2024. UNITE Community. https://doi.org/10.15156/BIO/2959335
Includes global and 3% distance singletons.
When using the fungi database, please cite it as follows:
Abarenkov, Kessy; Zirk, Allan; Piirmann, Timo; Pöhönen, Raivo; Ivanov, Filipp; Nilsson, R. Henrik; Kõljalg, Urmas (2024): UNITE general FASTA release for Fungi 2. Version 04.04.2024. UNITE Community. https://doi.org/10.15156/BIO/2959333
Includes global and 3% distance singletons.
SILVA
Quast, C., Pruesse, E., Yilmaz, P., Gerken, J., Schweer, T., Yarza, P., Peplies, J., & Glöckner, F. O. (2013). The SILVA ribosomal RNA gene database project: Improved data processing and web-based tools. Nucleic Acids Research, 41(D1), D590–D596. https://doi.org/10.1093/nar/gks1219
pr2
Guillou, L., Bachar, D., Audic, S., Bass, D., Berney, C., Bittner, L., Boutte, C., Burgaud, G., de Vargas, C., Decelle, J., del Campo, J., Dolan, J. R., Dunthorn, M., Edvardsen, B., Holzmann, M., Kooistra, W. H. C. F., Lara, E., Le Bescot, N., Logares, R., … Christen, R. (2013). The Protist Ribosomal Reference database (PR2): A catalog of unicellular eukaryote Small Sub-Unit rRNA sequences with curated taxonomy. Nucleic Acids Research, 41(Database issue), D597–D604. https://doi.org/10.1093/nar/gks1160
diat.barcode
Rimet, F., Gusev, E., Kahlert, M., Kelly, M. G., Kulikovskiy, M., Maltsev, Y., Mann, D. G., Pfannkuchen, M., Trobajo, R., Vasselon, V., Zimmermann, J., & Bouchez, A. (2019). Diat.barcode, an open-access curated barcode library for diatoms. Scientific Reports, 9(1), Article 1. https://doi.org/10.1038/s41598-019-51500-6
CRUX
Curd, E. E., Gold, Z., Kandlikar, G. S., Gomer, J., Ogden, M., O’Connell, T., Pipes, L., Schweizer, T. M., Rabichow, L., Lin, M., Shi, B., Barber, P. H., Kraft, N., Wayne, R., & Meyer, R. S. (2019). Anacapa Toolkit: An environmental DNA toolkit for processing multilocus metabarcode datasets. Methods in Ecology and Evolution, 10(9), 1469–1475. https://doi.org/10.1111/2041-210X.13214
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file apscale_nanopore-1.0.0.tar.gz.
File metadata
- Download URL: apscale_nanopore-1.0.0.tar.gz
- Upload date:
- Size: 19.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2f34e2c8a57218bb8395941af2fe4c1eb97601a556f4899e961ea727a85d7d8a
|
|
| MD5 |
4a7b5250f315e6fdfa09ff5ac8f2934f
|
|
| BLAKE2b-256 |
c1c9e3ade1b0ec99c277eeb7e777db53a13d2721ce39bcc919a457faaa8cd7bd
|
File details
Details for the file apscale_nanopore-1.0.0-py3-none-any.whl.
File metadata
- Download URL: apscale_nanopore-1.0.0-py3-none-any.whl
- Upload date:
- Size: 15.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9e95bafe33c091515b79ce1428683f4754a1afeaedab690ec16f742a5d6f7237
|
|
| MD5 |
199636581afa601c444ae338a348481e
|
|
| BLAKE2b-256 |
9c516a9c3dd9ef38be9c718d23853974c096584c9f4d2a20231a68ccb5a0bb76
|







