High-performance bulk data movement for Redshift

Project description
Arrowjet
The fastest way to move data in and out of Redshift.
Arrowjet uses Redshift's native COPY and UNLOAD commands — the same paths AWS uses internally — wrapped in a simple Python API with automatic S3 staging, cleanup, and error handling.
pip install arrowjet # core (BYOC Engine, CLI basics)
pip install arrowjet[redshift] # + Redshift driver (arrowjet.connect())
pip install arrowjet[full] # + Redshift + SQLAlchemy
Why Arrowjet
Standard Redshift drivers move data row-by-row over the wire. For large datasets, this is the bottleneck.
Arrowjet routes through S3 instead — parallel, columnar, and fast.
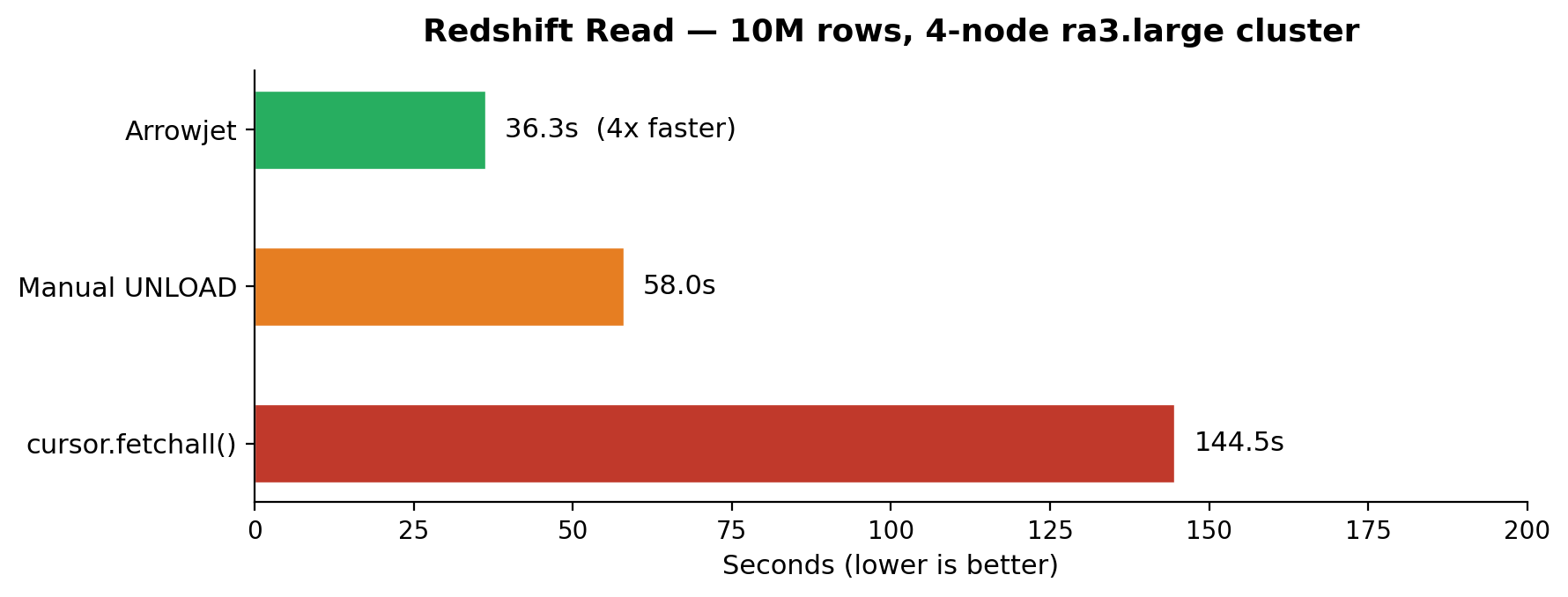
Reads (UNLOAD)
| Approach | 1M rows | 10M rows |
|---|---|---|
cursor.fetchall() |
~11s | ~105s |
| Manual UNLOAD | ~7s | ~58s |
| Arrowjet | ~4s | ~34s |
Writes (COPY)
| Approach | 1M rows | vs Arrowjet |
|---|---|---|
write_dataframe() INSERT |
13.4 hours | 14,523x slower |
executemany (batch 5000) |
27.1 hours | 29,296x slower |
| Multi-row VALUES (batch 5000) | 195.8s | 58.8x slower |
| Parallel VALUES (4 threads) | 148.4s | 44.6x slower |
| Manual COPY | 4.06s | 1.22x slower |
| Arrowjet | 3.33s | baseline |
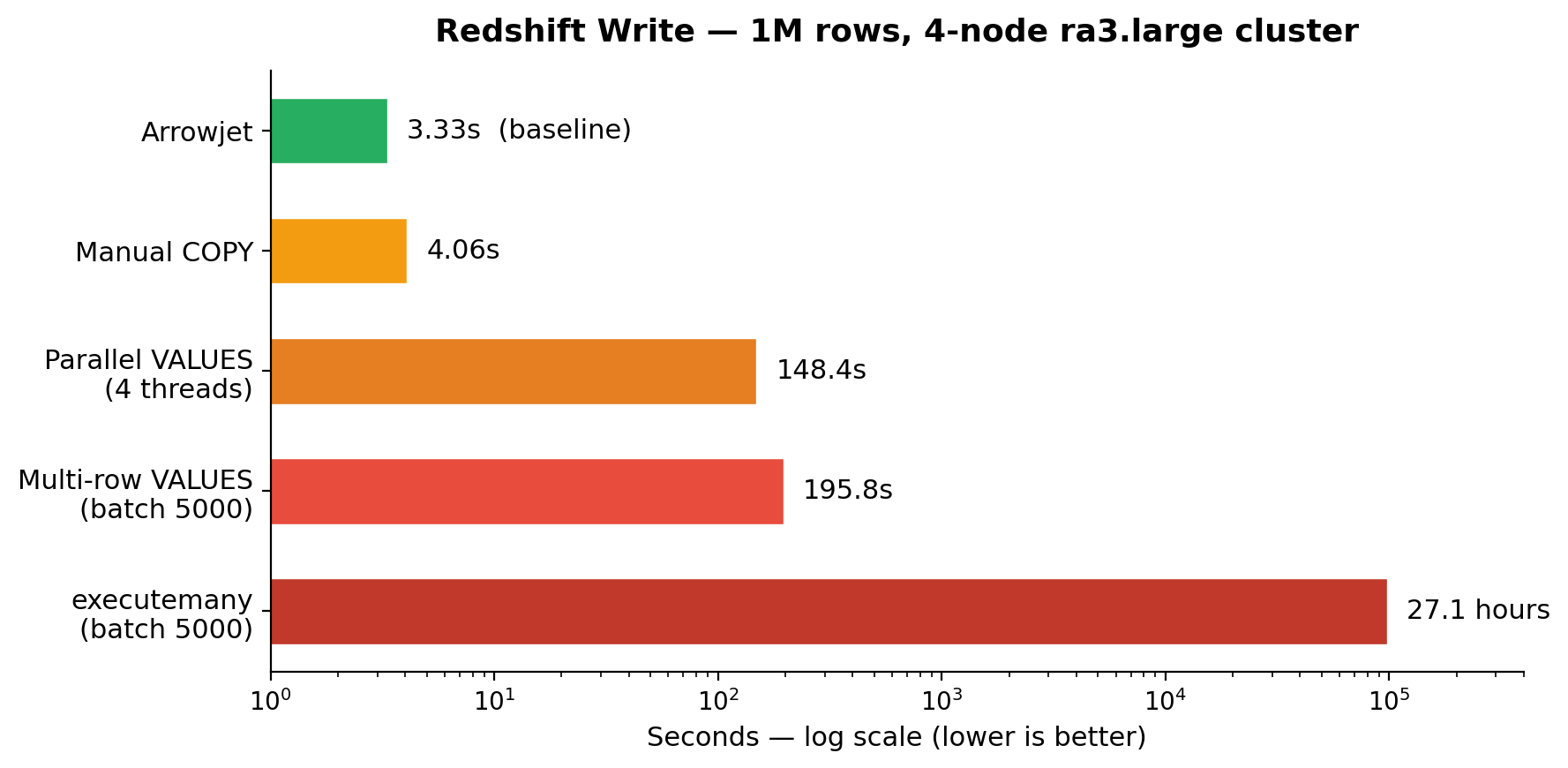
Benchmarked on a 4-node ra3.large cluster, EC2 same region. 5 iterations, randomized order.
Quick Start
import arrowjet
conn = arrowjet.connect(
host="your-cluster.region.redshift.amazonaws.com",
database="dev",
user="awsuser",
password="...",
staging_bucket="your-staging-bucket",
staging_iam_role="arn:aws:iam::123456789:role/RedshiftS3Role",
staging_region="us-east-1",
)
# Bulk read — UNLOAD → S3 → Parquet → Arrow
result = conn.read_bulk("SELECT * FROM events WHERE date > '2025-01-01'")
df = result.to_pandas()
print(f"{result.rows:,} rows in {result.total_time_s}s")
# Bulk write — Arrow → Parquet → S3 → COPY
conn.write_dataframe(my_dataframe, "target_table")
# Safe mode — standard DBAPI for small queries, transactions, metadata
df = conn.fetch_dataframe("SELECT COUNT(*) FROM events")
Authentication
Arrowjet supports three authentication methods for Redshift.
Password (default)
conn = arrowjet.connect(
host="your-cluster.region.redshift.amazonaws.com",
user="awsuser",
password="...",
staging_bucket=..., staging_iam_role=..., staging_region=...,
)
IAM (recommended for production)
No password needed — temporary credentials are fetched automatically via GetClusterCredentials (provisioned) or GetCredentials (serverless).
# Provisioned cluster
conn = arrowjet.connect(
host="your-cluster.region.redshift.amazonaws.com",
auth_type="iam",
db_user="etl_user",
staging_bucket=..., staging_iam_role=..., staging_region=...,
)
# Serverless workgroup
conn = arrowjet.connect(
host="your-workgroup.account-id.region.redshift-serverless.amazonaws.com",
auth_type="iam",
db_user="admin",
staging_bucket=..., staging_iam_role=..., staging_region=...,
)
Requires AWS credentials in the environment (env vars, ~/.aws/credentials, or IAM role).
Secrets Manager
conn = arrowjet.connect(
host="your-cluster.region.redshift.amazonaws.com",
auth_type="secrets_manager",
secret_arn="arn:aws:secretsmanager:us-east-1:123:secret:my-redshift-secret",
staging_bucket=..., staging_iam_role=..., staging_region=...,
)
BYOC with any auth method
The auth module works standalone — resolve credentials, then use any driver:
from arrowjet.auth.redshift import resolve_credentials
creds = resolve_credentials(
host="your-cluster.region.redshift.amazonaws.com",
auth_type="iam",
db_user="etl_user",
)
# Use with redshift_connector
import redshift_connector
conn = redshift_connector.connect(**creds.as_kwargs())
# Or with ADBC
import adbc_driver_postgresql.dbapi
conn = adbc_driver_postgresql.dbapi.connect(creds.as_uri())
# Then pass to the Engine
engine = arrowjet.Engine(staging_bucket=..., staging_iam_role=..., staging_region=...)
result = engine.read_bulk(conn, "SELECT * FROM events")
Bring Your Own Connection
Already have connection management? Use the Engine API — no rewiring needed.
import arrowjet
import redshift_connector # or psycopg2, or any DBAPI connection
# Your existing connection
conn = redshift_connector.connect(host=..., database=..., ...)
# Arrowjet just does the bulk part
engine = arrowjet.Engine(
staging_bucket="your-bucket",
staging_iam_role="arn:aws:iam::123:role/RedshiftS3Role",
staging_region="us-east-1",
)
result = engine.read_bulk(conn, "SELECT * FROM events")
engine.write_dataframe(conn, df, "target_table")
Works with redshift_connector, psycopg2, ADBC, or any DBAPI-compatible connection.
Integrations
Airflow
@task
def export_sample():
import arrowjet
conn = arrowjet.connect(host=..., staging_bucket=..., ...)
result = conn.read_bulk("SELECT * FROM benchmark_test_1m LIMIT 1000")
print(f"Exported {result.rows:,} rows in {result.total_time_s}s")
conn.close()
See examples/airflow/ for before/after comparison and benchmarks.
dbt
# Run dbt transforms, then bulk-export the results
bash examples/dbt/run_with_arrowjet.sh
See examples/dbt/ for the full setup.
SQLAlchemy
from sqlalchemy import create_engine
engine = create_engine("redshift+arrowjet://user:pass@host:5439/dev")
When to Use Each Mode
| Mode | Use when | How |
|---|---|---|
read_bulk |
Large SELECT (100K+ rows) | UNLOAD → S3 → Parquet → Arrow |
write_bulk / write_dataframe |
Loading data (any size) | Arrow → Parquet → S3 → COPY |
fetch_dataframe |
Small queries, transactions | PostgreSQL wire protocol |
Configuration
conn = arrowjet.connect(
# Redshift connection
host="...", database="dev", user="awsuser", password="...",
# Authentication (optional — default "password")
auth_type="password", # password | iam | secrets_manager
db_user="etl_user", # IAM: database user
secret_arn="arn:...", # Secrets Manager: secret ARN
aws_region="us-east-1", # AWS region (inferred from host if omitted)
aws_profile="production", # AWS profile name (optional)
# S3 staging (required for bulk mode)
staging_bucket="my-bucket",
staging_iam_role="arn:aws:iam::123:role/RedshiftS3",
staging_region="us-east-1",
# Optional
staging_prefix="arrowjet-staging", # S3 key prefix
staging_cleanup="on_success", # always | on_success | never | ttl_managed
staging_encryption="none", # none | sse_s3 | sse_kms
max_concurrent_bulk_ops=4,
)
See docs/configuration.md for the full reference.
CLI
arrowjet configure # set up connection profile
arrowjet export --query "SELECT * FROM sales" --to ./out.parquet # export to local file
arrowjet export --query "SELECT * FROM sales" --to s3://bucket/sales/ # export direct to S3 (no roundtrip)
arrowjet import --from s3://bucket/sales/ --to sales_table # load from S3 via COPY
arrowjet import --from ./data.parquet --to sales_table # load from local file
arrowjet preview --file ./out.parquet # inspect a Parquet file
arrowjet preview --file s3://bucket/sales/data.parquet # inspect an S3 Parquet file
arrowjet validate --table sales --row-count # row count
arrowjet validate --table sales --schema # column types
arrowjet validate --table sales --sample # sample rows
arrowjet validate --table sales --schema-name myschema --row-count # non-public schema
All commands read connection details from ~/.arrowjet/config.yaml (set up with arrowjet configure).
Override per-command with --host, --password, --profile, etc.
See docs/cli_reference.md for full details.
Requirements
- Python 3.10+
- Redshift cluster (provisioned or serverless)
- S3 bucket in the same region (for bulk mode)
- IAM role with S3 access attached to the Redshift cluster
- For IAM/Secrets Manager auth:
boto3(included in base install) and AWS credentials in the environment
See docs/iam_setup.md for IAM configuration.
License
MIT
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file arrowjet-0.2.0.tar.gz.
File metadata
- Download URL: arrowjet-0.2.0.tar.gz
- Upload date:
- Size: 73.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8e097172f0fe3afb098e31d704ddd50579ea66287104cc01c527cb9688697427
|
|
| MD5 |
01757bf44fee7850f756f47c436fcf8a
|
|
| BLAKE2b-256 |
6535ed00721da2b64aea637087a48d7316daf8ffdd1b11047eb2d477800b4f0b
|
File details
Details for the file arrowjet-0.2.0-py3-none-any.whl.
File metadata
- Download URL: arrowjet-0.2.0-py3-none-any.whl
- Upload date:
- Size: 59.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e88ffa7309763ae8f89574bbbf48a88c756e81b43ba30a57d79bd06cb135f6d8
|
|
| MD5 |
84a44ff87210a4b8480dc90164d82148
|
|
| BLAKE2b-256 |
2487fdb9285f5e5ad0ee9a58117688a88f6d48c97f78e15d27e8d32385343894
|







