Detect and analyze structural variants from a de novo genome assembly aligned to a reference genome
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Assemblytics: detect variants from an assembly
If you use Assemblytics, please cite our paper in Bioinformatics: http://www.ncbi.nlm.nih.gov/pubmed/27318204
BioRxiv preprint also available: https://www.biorxiv.org/content/10.1101/044925v1
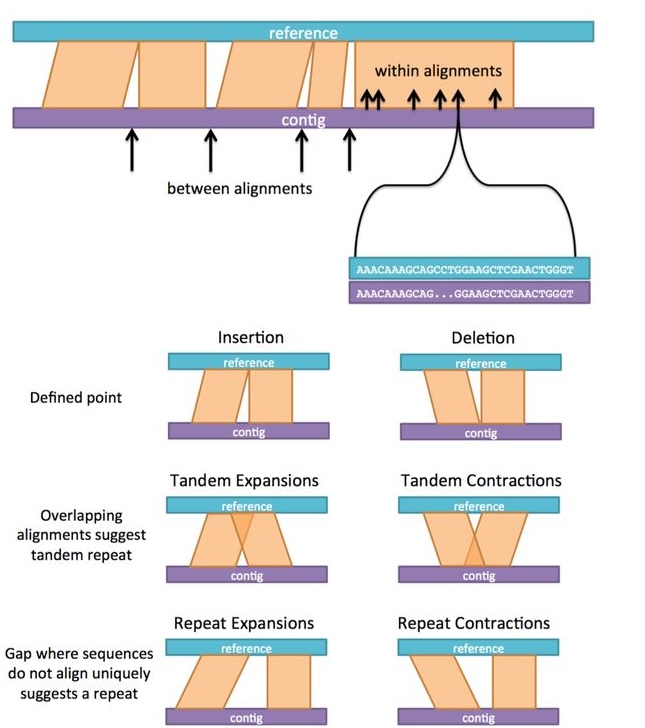
How Assemblytics works
Assemblytics analyzes alignments of a "query" assembly to a "reference" genome (or another assembly) to identify structural variants. The pipeline consists of the following key steps:
- Unique Anchor Filtering: For every alignment, Assemblytics calculates how much of the query sequence is "unique" (not covered by any other alignments). Alignments are only retained if they meet a minimum unique anchor length requirement (default 10,000 bp). This ensures that variants are called from high-confidence, non-repetitive regions.
- Calling Variants Between Alignments: Assemblytics identifies variants that occur in the gaps between adjacent alignments of the same query sequence. These include insertions, deletions, and tandem expansions/contractions that occur when the assembly and reference don't quite meet up.
- Calling Variants Within Alignments: The pipeline also scans within individual alignments for mismatches in the gap sizes on the reference vs. query side.
- Integration and Categorization: All identified variants are combined and categorized by type (Insertion, Deletion, Tandem Expansion/Contraction, Repeat Expansion/Contraction) and size.
- Visualization and Summary: Finally, the tool generates summary statistics and several plots, including a dot plot of filtered alignments, an Nchart of the assembly, and size distributions of all called variants.
How to use Assemblytics
- Align your assembly fasta file to some kind of reference you want to compare against. See
nucmerinput instructions below for the exact command we recommend. - Go to assemblytics.com and input your .delta file for analysis.
Important: Use only contigs rather than scaffolds from the assembly. This will prevent false positives when the number of Ns in the scaffolded sequence does not match perfectly to the distance in the reference.
nucmer input instructions
See my MUMmer tutorial on sandbox.bio.
IMPORTANT: Assemblytics was built for nucmer -maxmatch output and tuned to the following parameters, which is important for making the unique anchor filtering in Assemblytics work correctly.
Upload a delta file to analyze alignments of an assembly to another assembly or a reference genome
- Download and install MUMmer 4.
- Align your assembly to a reference genome using nucmer (from MUMmer package)
nucmer -maxmatch -l 100 -c 500 REFERENCE.fa ASSEMBLY.fa -prefix OUT
# Settings above are important for unique anchor filtering to work correctly in Assemblytics.
# I increased -l to 10000 for the human in input_examples, which cut down on file size significantly at the cost of losing a lot of sensitivity and thus alignments. I don't really recommend setting it that high for your main analysis, but it can be useful for a fast initial run.
# Optionally gzip
gzip OUT.delta
Consult the MUMmer github if you encounter problems.
- Use the output .delta or .delta.gz file at assemblytics.com
FAQ
What do the different variant types mean? What is tandem expansion versus repeat expansion?
What is unique anchor filtering for?
See this example showing the point of unique anchor filtering (from the bioRxiv preprint supplementary materials):
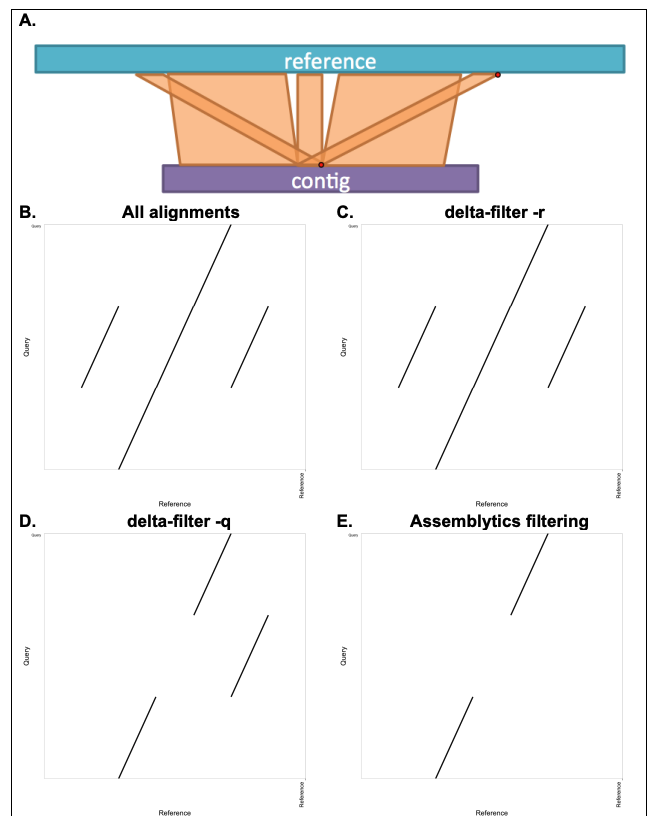
delta-filter -r (equivalent to unfiltered). D. Dot plot after delta-filter -q; here, a single nucleotide is enough for -q to prefer the third alignment. E. Dot plot after Assemblytics unique anchor filtering: only alignments with at least 10 kb uniquely anchored sequence (aligning to a single position in the reference) are retained; the repeats are removed. Assemblytics annotates structural variants within such filtered gaps as repeat expansions or contractions, depending on whether the gap is larger in the query or reference, respectively. No variant is reported unless the gap size changes, so repeats themselves are not reported as SVs—only expansions (increased size) or contractions (decreased size) are.
For small genomes (e.g. bacteria), you may want to reduce the unique_length to 1000.
How long does the analysis take?
The analysis will run in a few seconds for most genomes, and for the human example which is a 6 MB gzipped delta, it takes 50 seconds. It should scale linearly with file size, so expect at least a minute per 10MB. On assemblytics.com, it runs client-side meaning using your computer's own CPU, so if you are working on a really slow computer, it could run somewhat slower. If it's an issue, see nucmer instructions note on -l above, or consider running the python version.
What aligners can I use?
Assemblytics was built on MUMmer 3 but MUMmer 4 is still compatible. Other aligners do not produce .delta files but rather SAM/BAM outputs, which MUMmer 4 also supports now, but MUMmer was sort of the original aligner for genome assemblies (as opposed to reads), so that's what Assemblytics was built to work with. Many choices about which alignments are kept are also going to be different from other aligners, so I don't recommend using Assemblytics with anything other than MUMmer.
why no translocations?
By default, candidate variants that span two different reference chromosomes ("Interchromosomal") are left out of the main results, since most of them come from misassemblies rather than real variants. Pass --long-range to also write these candidates to a separate assemblytics_long_range_variants.bed, so they're easy to find but clearly kept apart from the main, higher-confidence call set:
assemblytics -d input_examples/ecoli.delta.gz -o ecoli_output --long-range
# In addition to the usual output, this also writes ecoli_output/assemblytics_long_range_variants.bed.
# These candidates are usually misassemblies, but can occasionally be real translocations or
# other large-scale rearrangements -- review them manually before trusting them as true variants.
Python-only version for pipelines
The python part of Assemblytics can be run without the web app.
Depends on Python 3.8+, and includes numpy, pandas, and matplotlib dependencies.
pip install assemblytics
The assemblytics command orchestrates the entire pipeline from filtering to plotting.
assemblytics -d <delta_file> -o <output_dir>
Example using the provided E. coli sample:
assemblytics -d input_examples/ecoli.delta.gz -o ecoli_output
# The output should match the one in the output_examples/ecoli folder.
Development instructions
Python
git clone https://github.com/MariaNattestad/assemblytics.git
cd assemblytics
pip install -e .
assemblytics
Local web app
The web app (public/) runs the entire Assemblytics pipeline client-side in the browser via Pyodide (Python compiled to WebAssembly) in a Web Worker. There is no server-side code, no upload step, and no installation beyond a static file server — your delta file never leaves your machine.
To run it locally, serve the public/ folder with any static file server, for example:
cd assemblytics
python3 -m http.server 8000 --directory public
# Then open http://localhost:8000 in your browser
The Python source lives in assemblytics/ at the repo root. The web app loads it as a Python wheel (public/assemblytics-2.0.0-py3-none-any.whl) installed at runtime by Pyodide's micropip.
After editing any Python files under assemblytics/, rebuild the wheel before testing or deploying:
make wheel
This runs python3 -m build --wheel and copies the result into public/. If you bump the version in pyproject.toml, also update the filename on line 18 of public/worker.js to match.
Testing
output_examples/ contains pre-computed results for five organisms, generated from the delta files in input_examples/. These are kept around (and untouched by any refactoring) specifically so the pipeline's correctness can be checked by re-running it and comparing the variant calls. The most important file to compare is assemblytics_structural_variants.bed (the combined, final set of structural variant calls) — everything else (plots, indices, summary stats) is derived from it.
To re-run the pipeline on each input and diff its variant calls against the matching example output:
pip3 uninstall assemblytics # remove whatever's installed
pip3 install -e . # install editable from current directory
# E. coli (uses a smaller unique anchor length since it's a small genome)
assemblytics -d input_examples/ecoli.delta.gz -o /tmp/assemblytics_test/ecoli -l 1000
diff <(tail -n +2 /tmp/assemblytics_test/ecoli/assemblytics_structural_variants.bed | sort) \
<(tail -n +2 output_examples/ecoli/E__coli_example.Assemblytics_structural_variants.bed | sort) \
&& echo "ecoli: OK"
# Yeast (Saccharomyces cerevisiae)
assemblytics -d input_examples/yeast.delta.gz -o /tmp/assemblytics_test/yeast
diff <(tail -n +2 /tmp/assemblytics_test/yeast/assemblytics_structural_variants.bed | sort) \
<(tail -n +2 output_examples/yeast/Saccharomyces_cerevisiae_example.Assemblytics_structural_variants.bed | sort) \
&& echo "yeast: OK"
# Arabidopsis thaliana
assemblytics -d input_examples/arabidopsis.delta.gz -o /tmp/assemblytics_test/arabidopsis
diff <(tail -n +2 /tmp/assemblytics_test/arabidopsis/assemblytics_structural_variants.bed | sort) \
<(tail -n +2 output_examples/arabidopsis/Arabidopsis_example.Assemblytics_structural_variants.bed | sort) \
&& echo "arabidopsis: OK"
# Drosophila melanogaster
assemblytics -d input_examples/drosophila.delta.gz -o /tmp/assemblytics_test/drosophila
diff <(tail -n +2 /tmp/assemblytics_test/drosophila/assemblytics_structural_variants.bed | sort) \
<(tail -n +2 output_examples/drosophila/Drosophila_example.Assemblytics_structural_variants.bed | sort) \
&& echo "drosophila: OK"
# Human (assembly aligned to hg19) -- the largest input, this one takes the longest to run
assemblytics -d input_examples/human.delta.gz -o /tmp/assemblytics_test/human
diff <(tail -n +2 /tmp/assemblytics_test/human/assemblytics_structural_variants.bed | sort) \
<(tail -n +2 output_examples/human/Human_NA12878_to_hg19.Assemblytics_structural_variants.bed | sort) \
&& echo "human: OK"
(No pip install -e . yet? Run these from inside public/ instead, replacing assemblytics with python -m assemblytics.cli and adjusting the input_examples//output_examples/ paths to ../input_examples//../output_examples/.)
Each diff should print nothing (no differences) followed by the "OK" line. The tail -n +2 skips the header line, and sort makes the comparison order-independent since variant IDs can legitimately be assigned in a different order between runs.
Cutting a new release
- Bump the version in
pyproject.tomlandassemblytics/__init__.py. - Update
public/worker.jsline 18 to reference the new wheel filename. - Rebuild the wheel and copy it into
public/:make wheel - Remove the old wheel from
public/and commit everything. - Push to
mainand merge. - Fix the GitHub release tag — if you created the tag before the version bump commit landed on
main, delete it and recreate it:git tag -d vX.Y.Z git push origin :refs/tags/vX.Y.Z
Then create a new release on GitHub targeting the updatedmain. This triggers the Publish to PyPI workflow automatically via OIDC Trusted Publishing. - Update the bioconda recipe (
packaging/bioconda/meta.yaml): bump the version and update thesha256to match the new PyPI tarball (find it on the PyPI release page or withpip download assemblytics==X.Y.Z && sha256sum assemblytics-X.Y.Z.tar.gz).
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file assemblytics-2.0.1.tar.gz.
File metadata
- Download URL: assemblytics-2.0.1.tar.gz
- Upload date:
- Size: 31.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1d28654899eb2c3537d0268c44d909c183c3d2236c17f408dcc8d87418958ee0
|
|
| MD5 |
1b35e71c109bde6d7685bacc39e1fdaf
|
|
| BLAKE2b-256 |
15953038430ad1ec1c56fc6704ca7d169fbf757ab7ca8f8ff70aef6afcb94751
|
Provenance
The following attestation bundles were made for assemblytics-2.0.1.tar.gz:
Publisher:
publish.yml on MariaNattestad/assemblytics
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
assemblytics-2.0.1.tar.gz -
Subject digest:
1d28654899eb2c3537d0268c44d909c183c3d2236c17f408dcc8d87418958ee0 - Sigstore transparency entry: 1925891164
- Sigstore integration time:
-
Permalink:
MariaNattestad/assemblytics@045a3377b411a77eab67bd60dd465fae302531b9 -
Branch / Tag:
refs/tags/v2.0.1 - Owner: https://github.com/MariaNattestad
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@045a3377b411a77eab67bd60dd465fae302531b9 -
Trigger Event:
release
-
Statement type:
File details
Details for the file assemblytics-2.0.1-py3-none-any.whl.
File metadata
- Download URL: assemblytics-2.0.1-py3-none-any.whl
- Upload date:
- Size: 29.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f9eea89791e7aec2e9d2c6b159d61a8b8ffd14c7ddff553f1bda1ebb5992d26a
|
|
| MD5 |
0306d9a07e4ab8b49465ca512c13b4f9
|
|
| BLAKE2b-256 |
3758b59a830bf29b1a807bbda628083225df9068fbcd9885fb6f91e681bd0113
|
Provenance
The following attestation bundles were made for assemblytics-2.0.1-py3-none-any.whl:
Publisher:
publish.yml on MariaNattestad/assemblytics
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
assemblytics-2.0.1-py3-none-any.whl -
Subject digest:
f9eea89791e7aec2e9d2c6b159d61a8b8ffd14c7ddff553f1bda1ebb5992d26a - Sigstore transparency entry: 1925891477
- Sigstore integration time:
-
Permalink:
MariaNattestad/assemblytics@045a3377b411a77eab67bd60dd465fae302531b9 -
Branch / Tag:
refs/tags/v2.0.1 - Owner: https://github.com/MariaNattestad
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@045a3377b411a77eab67bd60dd465fae302531b9 -
Trigger Event:
release
-
Statement type:







