Asynchronous job scheduler

Project description
asyncjobs





Asynchronous job scheduler. Using asyncio to run jobs in worker threads/processes.
Description
A job scheduler for running asynchronous (and synchronous) jobs with
dependencies using asyncio. Jobs are coroutines (async def functions) with
a name, and (optionally) a set of dependencies (i.e. names of other jobs
that must complete successfully before this job can start). The job coroutine
may await the results from other jobs, schedule work to be done in a thread or
subprocess, or various other things provided by the particular Context object
passed to the coroutine. The job coroutines are run by a Scheduler, which
control the execution of the jobs, as well as the number of concurrent threads
and processes doing work. The Scheduler emits events which allow e.g. progress
and statistics to be easily collected and monitored. A separate module is
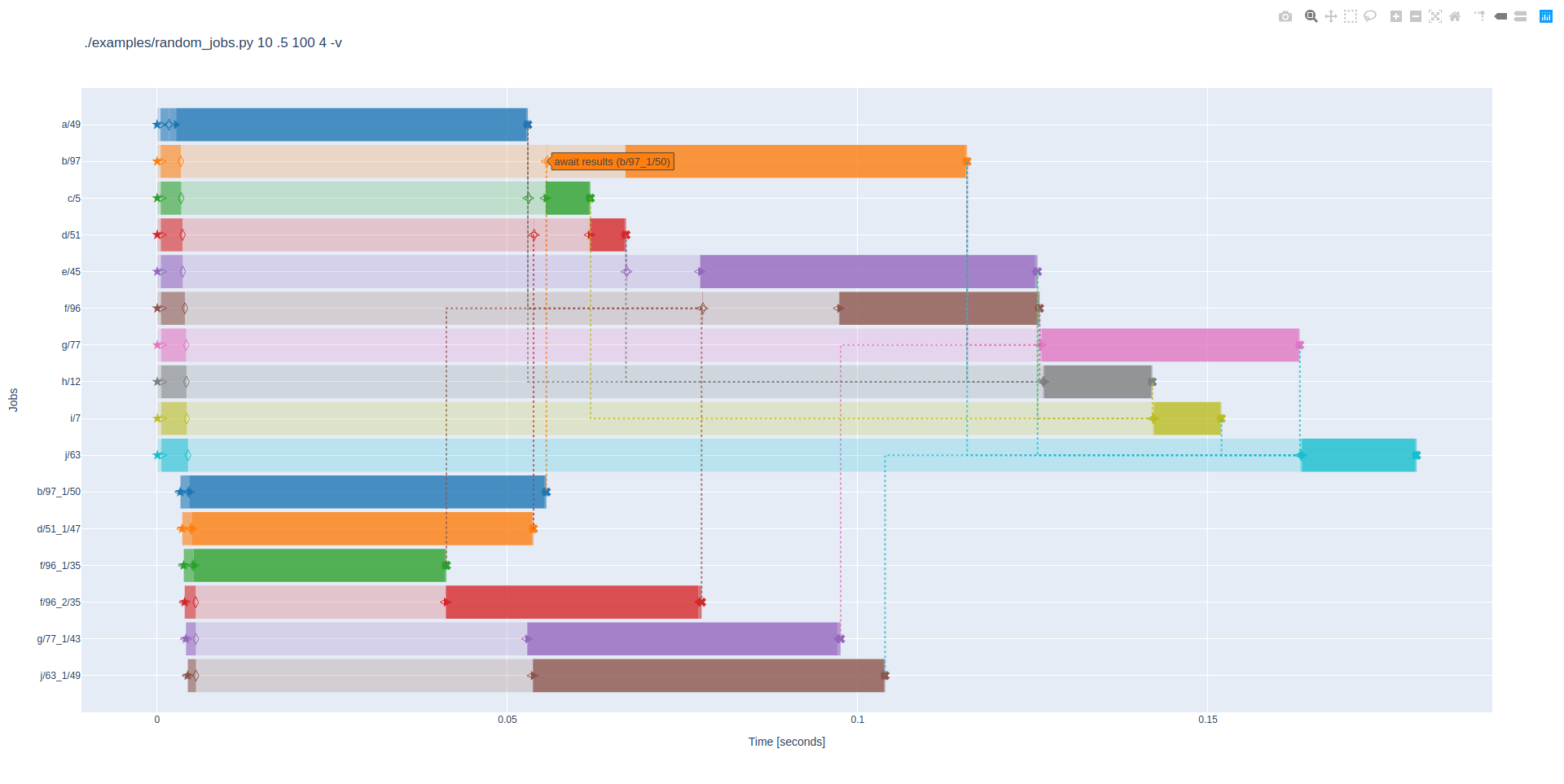
provided to turn Scheduler events into an interactive scheduling plot:
A job coroutine completes in one of three ways:
- Jobs complete successfully by returning, and the returned value (if any) is known as the job result.
- Jobs are considered to have failed if any exception propagates from its coroutine. Any job that depend on (i.e. await the result of) another job will be automatically cancelled by the scheduler if that other job fails.
- Jobs may be cancelled, which is implented by the scheduler raising an
asyncio.CancelledErrorinside the coroutine, and having it propagate out of the coroutine.
The Scheduler handles its own cancellation (e.g. Ctrl-C) by cancelling all ongoing and remaining tasks as quickly and cleanly as possible.
Usage examples
Run three simple jobs in sequence
import asyncio
from asyncjobs import Scheduler
import time
def sleep(): # Run in a worker thread by job #2 below
print(f'{time.ctime()}: Sleep for a second')
time.sleep(1)
print(f'{time.ctime()}: Finished sleep')
s = Scheduler()
# Job #1 prints uptime
s.add_subprocess_job('#1', ['uptime'])
# Job #2 waits for #1 and then sleeps in a thread
s.add_thread_job('#2', sleep, deps={'#1'})
# Job #3 waits for #2 and then prints uptime (again)
s.add_subprocess_job('#3', ['uptime'], deps={'#2'})
asyncio.run(s.run())
(code also available here) should produce output like this:
16:35:58 up 9 days 3:29, 1 user, load average: 0.62, 0.55, 0.55
Tue Feb 25 16:35:58 2020: Sleep for a second
Tue Feb 25 16:35:59 2020: Finished sleep
16:35:59 up 9 days 3:29, 1 user, load average: 0.62, 0.55, 0.55
Fetching web content in parallel
This example fetches a random Wikipedia article, and then follows links to other articles until 10 articles have been fetched. Sample output:
fetching https://en.wikipedia.org/wiki/Special:Random...
* [Nauru national netball team] links to 3 articles
fetching https://en.wikipedia.org/wiki/Nauru...
fetching https://en.wikipedia.org/wiki/Netball...
fetching https://en.wikipedia.org/wiki/Netball_at_the_1985_South_Pacific_Mini_Games...
* [Netball at the 1985 South Pacific Mini Games] links to 4 articles
* [Netball] links to 114 articles
fetching https://en.wikipedia.org/wiki/1985_South_Pacific_Mini_Games...
fetching https://en.wikipedia.org/wiki/Rarotonga...
fetching https://en.wikipedia.org/wiki/Cook_Islands...
* [Nauru] links to 257 articles
fetching https://en.wikipedia.org/wiki/Ball_sport...
* [Ball game] links to 8 articles
fetching https://en.wikipedia.org/wiki/Commonwealth_of_Nations...
* [Rarotonga] links to 43 articles
fetching https://en.wikipedia.org/wiki/Netball_Superleague...
* [Cook Islands] links to 124 articles
* [Netball Superleague] links to 25 articles
* [Commonwealth of Nations] links to 434 articles
* [1985 South Pacific Mini Games] links to 5 articles
Wasting time efficiently across multiple threads
The final example (which was used to produce the schedule plot above) simulates a simple build system: It creates a number of jobs (default: 10), each job sleeps for some random time (default: <=100ms), and has some probability of depending on each preceding job (default: 0.5). After awaiting its dependencies, each job may also split portions of its work into one or more sub-jobs, and await their completion, before finishing its remaining work. Everything is scheduled across a fixed number of worker threads (default: 4).
Installation
Run the following to install:
$ pip install asyncjobs
Development
To work on asyncjobs, clone this repo, and run the following (in a virtualenv) to get everything you need to develop and run tests:
$ pip install -e .[dev]
Additionally, if you want to generate scheduling plots (as seen above), you
need a couple more dependencies (plotly and
numpy):
$ pip install -e .[dev,plot]
Alternatively, if you are using Nix, use the included
shell.nix to get a development environment with everything automatically
installed:
$ nix-shell
Use nox to run all tests, formatters and linters:
$ nox
This will run the pytest-based test suite under all
supported Python versions, format the code with
black and run the
flake8 linter.
Contributing
Main development happens at https://github.com/jherland/asyncjobs/. Post issues and PRs there.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file asyncjobs-0.5.5.tar.gz.
File metadata
- Download URL: asyncjobs-0.5.5.tar.gz
- Upload date:
- Size: 129.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.2.0 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.6.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f24e28f684fea5f3df4ca255dd82a2e051d5e9f1780d876e847718adcbf780ae
|
|
| MD5 |
362aa8503e10e28af8259636b7677b89
|
|
| BLAKE2b-256 |
2d10cbef6f079fc8c9ea3cc39f95e44ff8657caaec7b1da12f7e5f314db298d2
|
File details
Details for the file asyncjobs-0.5.5-py3-none-any.whl.
File metadata
- Download URL: asyncjobs-0.5.5-py3-none-any.whl
- Upload date:
- Size: 26.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.2.0 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.6.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e3a05e4497268aa4ca2bd48c6c628bde0950273a53e5000761ee6cfaac46258c
|
|
| MD5 |
5b11df6e19cba1c4a12d77a9cb9bdca2
|
|
| BLAKE2b-256 |
b73162f7ef3a5297b09513d863dc591f3fc209b00cb12bdf8194258e57f2c43e
|







