A Python package for fast exploration of machine learning pipelines

Project description

Automated Tool for Optimized Modeling
A Python package for fast exploration of machine learning pipelines
📜 Overview
Mavs
m.524687@gmail.com
Documentation
Slack
| General Information | |
|---|---|
| Repository |     |
| Release |     |
| Compatibility |   |
| Build status |    |
| Code analysis |      |
💡 Introduction
During the exploration phase of a machine learning project, a data scientist tries to find the optimal pipeline for his specific use case. This usually involves applying standard data cleaning steps, creating or selecting useful features, trying out different models, etc. Testing multiple pipelines requires many lines of code, and writing it all in the same notebook often makes it long and cluttered. On the other hand, using multiple notebooks makes it harder to compare the results and to keep an overview. On top of that, refactoring the code for every test can be quite time-consuming. How many times have you conducted the same action to pre-process a raw dataset? How many times have you copy-and-pasted code from an old repository to re-use it in a new use case?
ATOM is here to help solve these common issues. The package acts as a wrapper of the whole machine learning pipeline, helping the data scientist to rapidly find a good model for his problem. Avoid endless imports and documentation lookups. Avoid rewriting the same code over and over again. With just a few lines of code, it's now possible to perform basic data cleaning steps, select relevant features and compare the performance of multiple models on a given dataset, providing quick insights on which pipeline performs best for the task at hand.
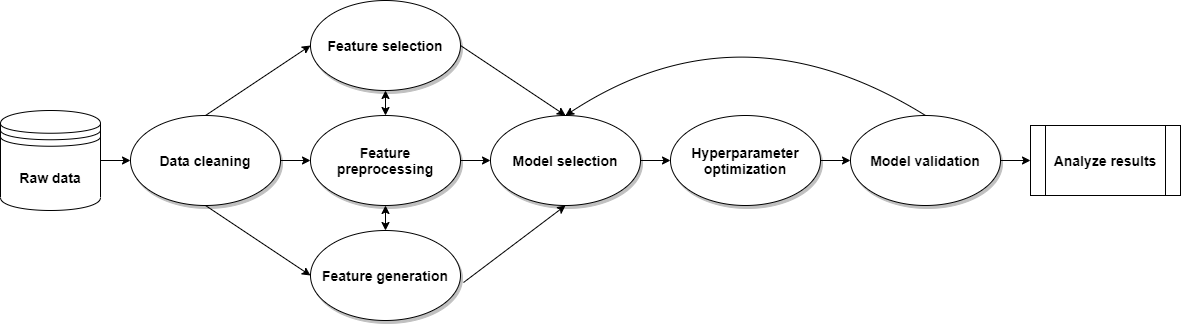
Example steps taken by ATOM's pipeline:
- Data Cleaning
- Handle missing values
- Encode categorical features
- Detect and remove outliers
- Balance the training set
- Feature engineering
- Create new non-linear features
- Select the most promising features
- Train and validate multiple models
- Apply hyperparameter tuning
- Fit the models on the training set
- Evaluate the results on the test set
- Analyze the results
- Get the scores on various metrics
- Make plots to compare the model performances
❗ Why you should use ATOM
- Multiple data cleaning and feature engineering classes
- 55+ classification, regression and forecast models to choose from
- Possibility to train multiple models with one line of code
- Fast implementation of hyperparameter tuning
- Easy way to compare the results from different models
- 50+ plots to analyze the data and model performance
- Avoid refactoring to test new pipelines
- Native support for GPU training
- Integration with polars, pyspark and pyarrow
- 30+ example notebooks to get you started
- Full integration with multilabel and multioutput datasets
- Native support for sparse datasets
- Build-in transformers for NLP pipelines
- Avoid endless imports and documentation lookups
🛠️ Installation
Install ATOM's newest release easily via pip:
$ pip install -U atom-ml
or via conda:
$ conda install -c conda-forge atom-ml
⚡ Usage


ATOM contains a variety of classes and functions to perform data cleaning, feature engineering, model training, plotting and much more. The easiest way to use everything ATOM has to offer is through one of the main classes:
- ATOMClassifier for binary or multiclass classification tasks.
- ATOMForecaster for forecasting tasks.
- ATOMRegressor for regression tasks.
Let's walk you through an example. Click on the SageMaker Studio Lab badge on top of this section to run this example yourself.
Make the necessary imports and load the data.
import pandas as pd
from atom import ATOMClassifier
# Load the Australian Weather dataset
X = pd.read_csv("https://raw.githubusercontent.com/tvdboom/ATOM/master/examples/datasets/weatherAUS.csv")
X.head()
Initialize the ATOMClassifier or ATOMRegressor class. These two classes are convenient wrappers for the whole machine learning pipeline. Contrary to sklearn's API, they are initialized providing the data you want to manipulate.
atom = ATOMClassifier(X, y="RainTomorrow", n_rows=1000, verbose=2)
Data transformations are applied through atom's methods. For example, calling the impute method will initialize an Imputer instance, fit it on the training set and transform the whole dataset. The transformations are applied immediately after calling the method (no fit and transform commands necessary).
atom.impute(strat_num="median", strat_cat="most_frequent")
atom.encode(strategy="target", max_onehot=8)
Similarly, models are trained and evaluated using the run method. Here, we fit both a LinearDiscriminantAnalysis and AdaBoost model, and apply hyperparameter tuning.
atom.run(models=["LDA", "AdaB"], metric="auc", n_trials=10)
And lastly, analyze the results.
atom.results
atom.plot_roc()
 Documentation
Documentation
| Relevant links | |
|---|---|
| ⭐ About | Learn more about the package. |
| 🚀 Getting started | New to ATOM? Here's how to get you started! |
| 👨💻 User guide | How to use ATOM and its features. |
| 🎛️ API Reference | The detailed reference for ATOM's API. |
| 📋 Examples | Example notebooks show you what can be done and how. |
| 📢 Chagelog | What are the new features in the latest release? |
| ❔ FAQ | Get answers to frequently asked questions. |
| 🔧 Contributing | Do you wan to contribute to the project? Read this before creating a PR. |
| 🌳 Dependencies | Which other packages does ATOM depend on? |
| 📃 License | Copyright and permissions under the MIT license. |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file atom_ml-6.1.0.tar.gz.
File metadata
- Download URL: atom_ml-6.1.0.tar.gz
- Upload date:
- Size: 304.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
90669d0ed075a5b07053a9d8d5f8db3389f78267045566e2c0eb78cd6948a833
|
|
| MD5 |
8c4d03e9f511d1b2bfa8e0edd8fc9ea5
|
|
| BLAKE2b-256 |
bcdddabcf7f5a023974820dcb6b9e0aa3582d4fa82e38b3dc096ba2bf51df30e
|
File details
Details for the file atom_ml-6.1.0-py3-none-any.whl.
File metadata
- Download URL: atom_ml-6.1.0-py3-none-any.whl
- Upload date:
- Size: 269.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
656896e88e40d6c7e9e331f2c3182f401e7e9946ae4a33ec0d60d0cf46130251
|
|
| MD5 |
cd339e3fd6049b4b2f2f8ed5a3ec41ad
|
|
| BLAKE2b-256 |
9b6bf0009c74783daa565577613462fecdc411be280e0f75e04173b7a2e171d2
|







