Capture, replay, and audit AI agent decisions. An open-source SDK for auditable AI agents.

Project description
auditable
Capture, replay, and audit AI agent decisions.




Novelties · Flagship Demo · Lifecycle · Install · Roadmap
Agents act on dependency state that quietly drifts. A budget read minutes ago can fall below the amount already committed; a price pinned at plan time can move before the action lands. Most tools log what happened, yet they cannot re-decide under the state that is live now, so a stale decision stands until a human notices. auditable closes that recovery gap across the lifecycle on one graph: it captures the decision, replays it against live state, and reverses the committed action when it no longer holds.
Three Novelties
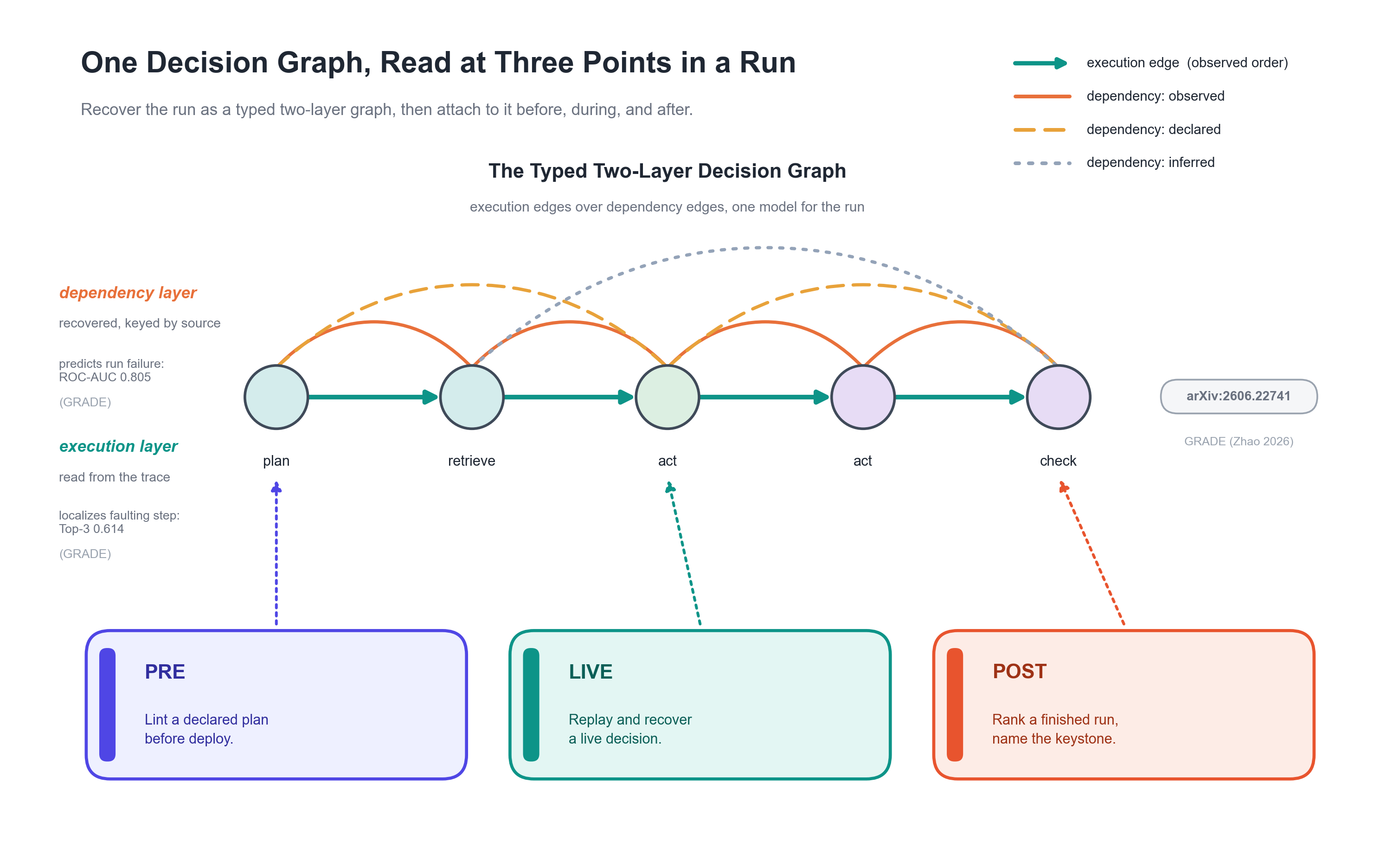
The full lifecycle chain. One graph kernel carries the analysis from design to live operation to review. PRE lints a declared plan, LIVE captures and recovers a live decision, POST ranks a finished run. examples/end_to_end.py walks a single payment through all three on one dataset and one state.
The graph model. Every pillar reads the same typed two-layer decision graph: an execution layer (control flow, observed from the trace) over a dependency layer (what each step relied on, declared or inferred, never read off the trace). The two-layer model is introduced in GRADE (arXiv:2606.22741).
The orthogonal decomposition. One agent decision crosses three spans: data (what it read and the snapshot it relied on), model (which model produced the output and its stated basis), and harness (the action executed and its cost). auditable binds all three in a single signed, hash-chained record, so a decision is judged as a unit.
The Flagship Moment
One payment, walked through the whole lifecycle in 18 auditable calls. The agent approves a $2,083.20 vendor payment against a budget snapshot that covered it. Six days later the live budget has dropped below the amount. replay re-decides on the live state, and the gate reverses the committed payment. This is recovery, not a log line.
pip install "auditable[graph]"
python examples/end_to_end.py
The run prints a single audit report: a REVIEW verdict, the keystone with its coverage reason, six findings with severity tags and recommended actions, and the LIVE recovery that rolled the payment back. Paste it into a pull request or an issue.
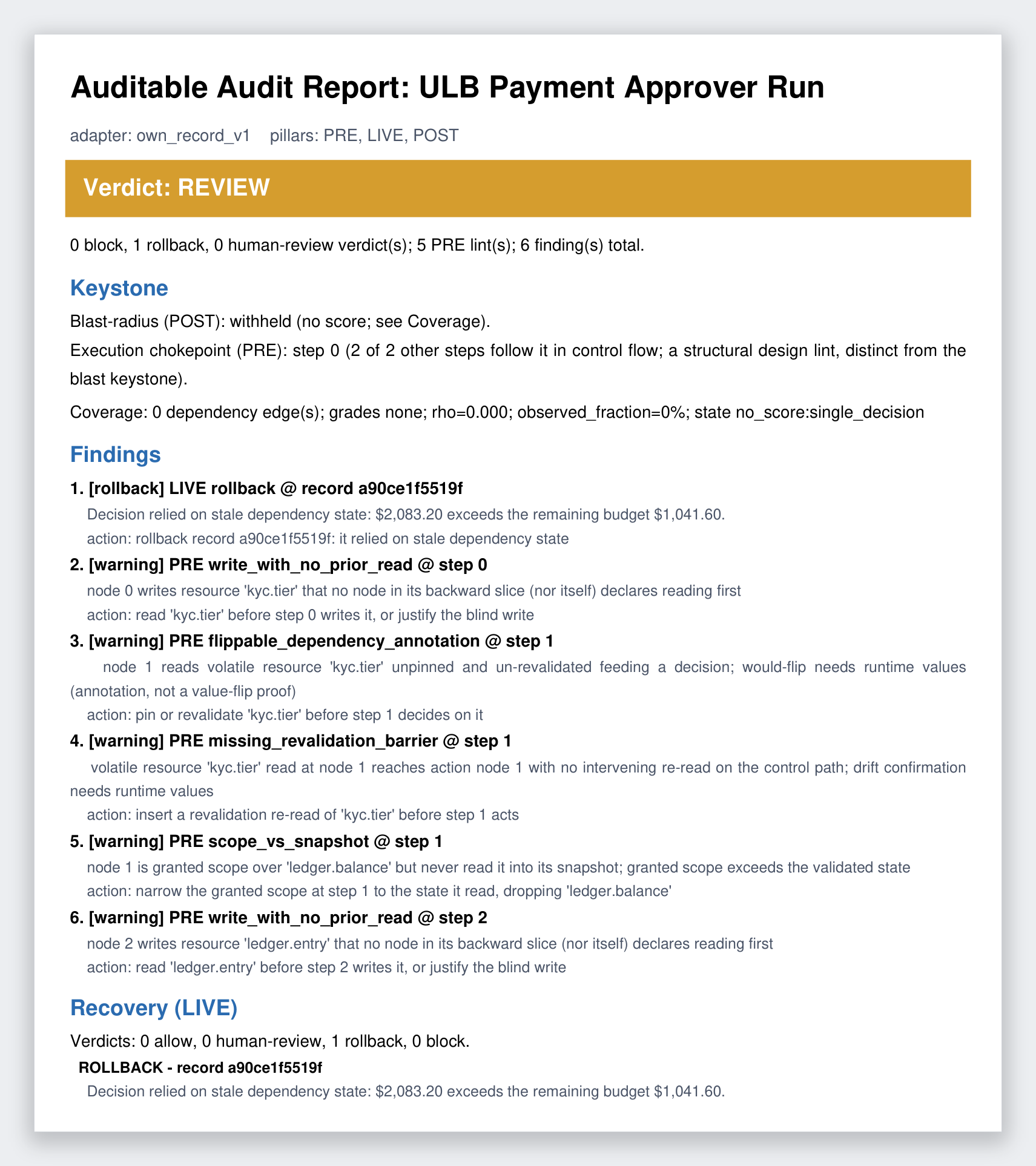
The shortest taste is LIVE on its own. Capture a decision, replay it under the live state, reverse the action when it no longer holds:
from auditable import Action, ActionGate, DependencySnapshot, ReferenceLedger, audit, replay
def policy(state, action):
ok = action.cost <= state["budget"]
return ok, "within budget" if ok else "over budget"
ledger = ReferenceLedger(balance=10_000)
gate = ActionGate(ledger)
payment = Action("payment", {"to": "acme"}, cost=4_200)
# The agent pays $4,200 against a budget snapshot that read $10,000.
with audit("payment", snapshot=DependencySnapshot(state={"budget": 10_000})) as decision:
decision.act(payment)
receipt = gate.commit(payment) # paid; balance is now 5,800
# The live budget is now $3,000. Replay re-decides; the gate reverses the payment.
verdict = replay(decision.record, live_state={"budget": 3_000}, policy=policy)
gate.enforce_post_commit(verdict, receipt=receipt)
print(verdict.action.value, "->", ledger.balance) # rollback -> 10000
replay is pure: it deep-copies the live state and the action, so a policy can never alter the signed record.
The Lifecycle
auditable runs the same detection-and-report pass over one typed decision graph at three points in an agent's life. The graph kernel stays constant; only the pillar changes (when it fires, what it scores).
| Pillar | When It Fires | Public Entry | Focus |
|---|---|---|---|
| PRE | Before deploy | analyze_plan |
Read-only structural lints on a declared plan. Names the control-flow chokepoint. Dependency-state risk withheld. |
| LIVE | While running | audit + replay + ActionGate |
Capture a decision, re-decide under live state, route a fix (allow, block, review, rollback) through a rail. The sharpest pillar. |
| POST | After a run | analyze_run |
Rank a finished run by structural blast share. Name the keystone the run rests on, so you review that step first. |
Install
pip install auditable
The core is dependency-free and torch-free. Structural-graph analysis (analyze_plan for PRE, analyze_run for POST) needs the optional graph extra (NetworkX):
pip install "auditable[graph]"
The LIVE snippet above runs on the core install alone.
The Three Pillars, in Detail
PRE: lint the plan before deploy (four read-only lints, the chokepoint, a coverage report)
Point analyze_plan at a declared plan (a plain dict, the neutral target a LangGraph, CrewAI, or AutoGen front-end would lower into) and it runs read-only structural lints over the plan graph. Every check is a pure NetworkX query: no value is executed, and every finding is a structural design warning, not a validated failure prediction.
from auditable.graph.pre import analyze_plan
from auditable.graph.adapters import declared_plan_v1
plan = {
"nodes": [
# 0: read a volatile price, but grant scope far beyond what it read.
{"idx": 0, "agent": "planner", "kind": "tool_call",
"reads": [{"id": "price", "volatile": True}],
"scope": ["price", "ledger", "vendor_db"]},
# 1: a decision that rests on the unpinned, un-revalidated price.
{"idx": 1, "agent": "planner", "kind": "decision",
"reads": [{"id": "price", "producer": 0, "volatile": True}],
"control_preds": [0]},
# 2: a consequential write of 'order', with no prior read of 'order'
# and no re-read of 'price' between the volatile read and the action.
{"idx": 2, "agent": "executor", "kind": "tool_call",
"reads": [{"id": "price", "producer": 0, "volatile": True}],
"writes": ["order"], "control_preds": [1]},
]
}
report = analyze_plan(plan, adapter=declared_plan_v1)
print(report)
The four shipping lints, all read-only queries at severity='warning':
| Lint | Fires When |
|---|---|
write_with_no_prior_read |
A node writes a resource that nothing in its backward slice ever read. |
flippable_dependency_annotation |
An unpinned, non-revalidated volatile dependency feeds a decision. This is an annotation; the would-it-flip question needs runtime values and is out of scope at PRE. |
scope_vs_snapshot |
Granted tool scope strictly exceeds the snapshot the node read. |
missing_revalidation_barrier |
A volatile read reaches a consequential action with no intervening re-read. Drift confirmation needs runtime values and is out of scope at PRE. |
The report also names the execution-topology keystone: the structural chokepoint of the declared plan, the node that the most other nodes transitively follow in control flow (the argmax of execution_reach over the handoff_to projection). This is a structural design lint, a separate concept from the POST blast-radius keystone, and it does not predict failure.
Alongside the lints, the Preflight Coverage Report is a descriptive coverage-readiness view, explicitly not a risk score. It reports the dependency-edge grade mix, the observed fraction, the saturation ratio, the exact no-score reason the runtime scorer would apply, which declared reads, writes, and edges still lack a resource identity, and the declared revalidation barriers per resource.
Two boundaries, stated plainly. Dependency-state blast-share risk is withheld at PRE: the declared dependency layer is declared-only (observed fraction zero), so analyze_plan returns state_b_risk=None with state_b_withheld=True and a reason string, and it raises rather than emit a number if a scored verdict ever came back. A table-stakes OWASP-Agentic and CWE rule floor is planned, not shipping.
See examples/analyze_plan.py and the PRE rules reference.
POST: rank a finished run, find the keystone (`analyze_run` over a recorded trajectory)
analyze_run reads a recorded agent run, builds one decision graph, and ranks every step by how much of the run transitively rests on it, so you review the keystone first. On a tau-bench airline trajectory, the one reservation read that both later writes depend on is the keystone.

from auditable import analyze_run
from auditable.graph.adapters import tau_bench_prior_db_reads_v1
report = analyze_run(run, adapter=tau_bench_prior_db_reads_v1)
k = report.keystone
print(k.idx, k.node_attrs["tool"]) # 2 get_reservation_details
The score is an uncalibrated triage ranking, not a calibrated probability. In a no-score state (no_score:single_decision, no_score:low_coverage) the scores are None, so a withheld score never reads as zero risk. The corpus write-to-read edges are modeled (a conservative prior-read upper bound, not a causal label); the report carries these caveats in report.notes. The trajectory is modeled on tau-bench (Sierra Research, MIT). See examples/analyze_run.py and the POST analysis reference.
How It Works: the two-layer graph, the signed record, the rail (kernel internals)
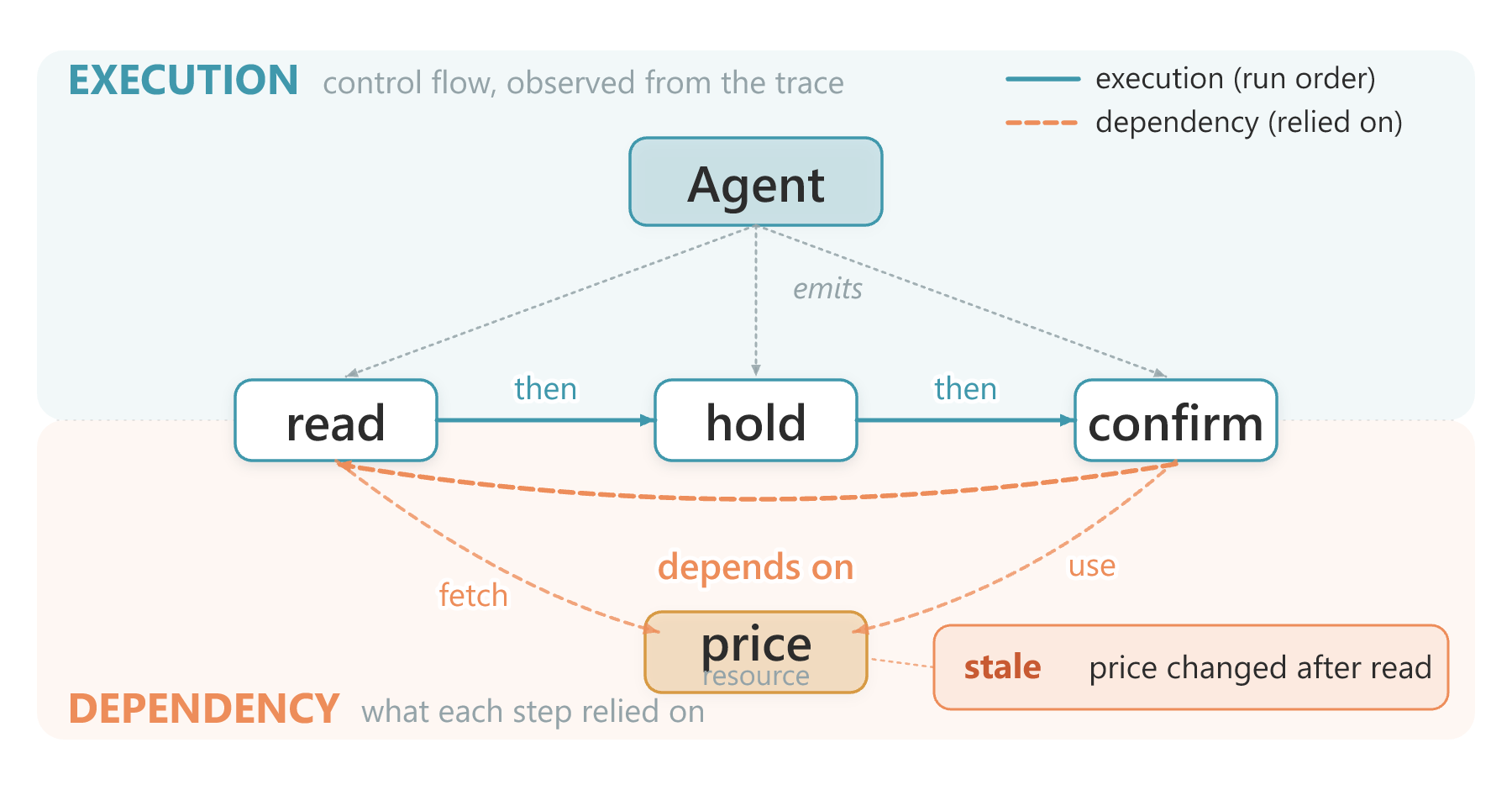
auditable links a run into one graph with two edge layers: execution (control flow, observed from the trace) over dependency (what each step relied on). When a step rested on a value that has since gone stale, like price, replay catches it. The record itself binds three spans per decision (data, model, harness).
The graph kernel has two edge layers, and the distinction is load-bearing. Execution edges (emits, handoff_to) are observed from the trace. Dependency edges (depends_on) are declared or inferred, never read off the trace. PRE and POST both run over this same typed graph; audit() is the ergonomic capture entry, so you are never asked to build the graph by hand.
One agent decision crosses three spans, and auditable binds all three in a single signed, hash-chained record:
| Span | What the Record Binds | Signal in v0.1 |
|---|---|---|
| Data | What the agent read and the dependency snapshot it relied on | Snapshot freshness |
| Model | Which model produced the output, and its stated basis | Decision-basis trust flag |
| Harness | The action executed and its cost | A static cost-cap rule, plus the replay verdict |
replay() re-derives whether the action still holds under the live dependency state versus the snapshot the agent used, and returns one of four routed verdicts: ALLOW, ROLLBACK (justified on the snapshot but not on live state, the stale-state case), BLOCK (justified on neither), or HUMAN_REVIEW (the policy raised ReplayUndecidable). A Policy is any callable (state, action) -> (justified, reason). The ActionGate then executes that verdict through a Rail: a post-commit ROLLBACK or BLOCK calls rail.compensate(receipt) to reverse a committed action, rather than printing a recommendation. The shipped ReferenceLedger is an in-process reference rail for demos and tests; it is not a production payment rail.
Records are signed and hash-chained: each record carries a prev_digest and a content-addressed record_id. Two sinks ship today, MemorySink (in-process) and FileSink (append-only JSONL, durable across process exit, fails closed on a corrupt tail).
Ingestion is source-agnostic through the public Adapter protocol. Three adapters ship: tau_bench_prior_db_reads_v1 (public-corpus trajectory, POST), own_record_v1 (auditable's own signed records, POST), and declared_plan_v1 (a framework-agnostic declared plan dict, PRE). The declared-plan adapter is the neutral seam a LangGraph, CrewAI, or AutoGen front-end would lower into; it is not a parser for any framework.
See the architecture reference for the full kernel, adapters, and sinks.
Using a single layer (standalone auditors as inputs to the record)
Each span's check is a standalone Auditor that runs on its own, with no agent and no chain, and returns a signed Report. DataAuditor scores snapshot freshness, ModelAuditor produces a decision-basis trust flag, and HarnessAuditor applies one static cost-cap rule.
import time
from auditable import DataAuditor, DependencySnapshot
snapshot = DependencySnapshot(state={"budget_remaining": 1000}, captured_at=time.time() - 7 * 86400)
report = DataAuditor(max_age_seconds=86400).assess(snapshot)
print(report.flag, report.score) # stale 1.0
These standalone auditors are inputs to the record, not the headline. The composition (capture, replay, recovery, and the lifecycle pillars) is the main line; the modules feed it. See examples/standalone_report.py.
Scope, stated honestly (what ships today vs. what is planned)
What ships today. The full signed chain, replay under live state, executed recovery through a rail-neutral gate, two sinks (in-memory and append-only JSONL), the POST analyze_run ranking, and the PRE analyze_plan lints plus preflight coverage report.
The release does not yet claim a learned data-anomaly method, a calibrated model-trust score, calibrated cross-layer risk, or live incremental scoring. The POST structural score is an uncalibrated ranking; the compound report is a transparent, explicitly uncalibrated debug bundle. Everything beyond this list is on the roadmap.
Roadmap
Every item below is planned, not shipping.
- v0.2 Data a fitted anomaly score on the dependency state (PyOD backend), with snapshot freshness as a fallback
- v0.3 Model and compound a calibrated cross-layer compound, and model as a first-class graph node attribute with grounding beyond the current deterministic basis check
- v0.3b Live live and incremental scoring, plus the runtime resource-touch contract that fills observed dependency edges
- v0.4 Control data refresh or quarantine, and model fallback or sign-off control faces
- PRE rule floor a table-stakes OWASP-Agentic and CWE rule floor for CI legibility, consumed rather than forked
- v1.0 pluggable sinks (OpenTelemetry, LangSmith), exportable evidence bundles, and a stable public API
- Framework integrations (LangChain, LangGraph, CrewAI) and an MCP server
Citation
If you use auditable in your work, please cite the GRADE paper (the typed two-layer graph model the library is built on) and, optionally, the software:
@article{zhao2026grade,
title = {GRADE: Graph Representation of LLM Agent Dependency and Execution},
author = {Zhao, Yue},
journal = {arXiv preprint arXiv:2606.22741},
year = {2026}
}
@software{auditable,
title = {auditable: Capture, Replay, and Recover AI Agent Decisions},
author = {Zhao, Yue},
year = {2026},
url = {https://github.com/yzhao062/auditable}
}
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file auditable-0.1.0.tar.gz.
File metadata
- Download URL: auditable-0.1.0.tar.gz
- Upload date:
- Size: 138.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
502660156e7618772d48844ac921f979c50f08b3642f48fc0de519935dacab0a
|
|
| MD5 |
7d3c36d7029ce57ba18b63ed2675f1a0
|
|
| BLAKE2b-256 |
a507a9fbe3cd1e95a3504ca0f9a7b892ba088e833be66da74fdba4152009739d
|
File details
Details for the file auditable-0.1.0-py3-none-any.whl.
File metadata
- Download URL: auditable-0.1.0-py3-none-any.whl
- Upload date:
- Size: 101.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5200e7f1eff4437865dbd391c72dbe87edb585e5d952bc7cd5c245a435616cc4
|
|
| MD5 |
b8a7005d940613518d2c52d790c0e89a
|
|
| BLAKE2b-256 |
1249df717bdc2650e0c2fb8d717f822cc82576ad0cf0e4669890d051fe370432
|







