Multi-backend, multi-modal micro-framework for AI agent development, orchestration, and deployment

Project description
avalan
The multi-backend, multi-modal micro-framework for AI agent development, orchestration, and deployment







Avalan is a Python framework and CLI for building AI agents with local and hosted models. It unifies model execution, tools, memory, workflows, and serving so you can move from experiments to deployed systems without rewriting around a single provider or runtime.
✨ Highlights
- 🔀 One runtime for local and hosted models across Hugging Face model ids and
vendor
ai://URIs. - 🎞️ Multi-modal support for text, vision, and audio workloads.
- 🔌 Multiple backends including
transformers,vLLM, andmlx-lm. - 🧰 Built-in tools and memory for browser automation, code execution, databases, MCP, search, YouTube, and vector-backed retrieval.
- 🧠 Composable orchestration with flows, branching, reasoning strategies, and observability.
- 🌐 Open serving surfaces for OpenAI-compatible APIs, MCP, and A2A.
🚀 Start Here
- 📦 Use Install to pick the extras you actually need.
- ⚡ Use Quickstart to run a hosted model from the CLI or Python.
- 🧪 Use Models to search, install, and run open models locally.
- 🤖 Use Agents to expose an agent over HTTP, MCP, or A2A.
- 📚 Use docs/examples for runnable scripts and sample agent configurations.
- 🛠️ Use docs/CLI.md for the complete command reference.
- 🔗 Use docs/ai_uri.md for engine URI syntax and backend routing.
🗂️ Table of Contents
- ❓ Why Avalan
- 📦 Install
- ⚡ Quickstart
- 🧪 Models
- 🎛️ Modalities
- 🎧 Audio
- 📝 Text
- 👁️ Vision
- 🧰 Tools
- 🧠 Reasoning strategies
- 🗃️ Memories
- 🤖 Agents
- 📚 Documentation & Resources
- 🤝 Community & Support
- 🧑💻 Contributing
❓ Why Avalan
- 🔄 Model portability: use the same CLI and SDK for open models, vendor APIs, and local services.
- 🏠 Deployment flexibility: run on a laptop, Apple Silicon workstation, Linux GPU box, your own cloud, or on-prem.
- 🧩 Agent building blocks: combine tools, memories, workflows, and reasoning strategies instead of wiring them yourself.
- 🔗 Open interfaces: expose agents through OpenAI-compatible HTTP, MCP, A2A, or embed them into FastAPI.
- 📈 Incremental adoption: start with a single
model runcommand, then grow into orchestrated agents and deployments.
📦 Install
Avalan supports Python 3.11 and 3.12. Install the smallest profile that fits your workflow; the examples later in this README may require additional extras.
🐍 Pip (recommended)
Hosted APIs plus tool-enabled or served agents:
python3 -m pip install -U "avalan[agent,server,tool,vendors]"
Broader local development setup with the capabilities used throughout this README:
python3 -m pip install -U "avalan[agent,audio,memory,server,tool,translation,vendors,vision]"
Add hardware-specific extras when needed:
mlxorapple– Apple Silicon acceleration via MLX / MLX-LM.nvidia– Linux + NVIDIA bundle for vLLM and quantization support.vllm– the vLLM runtime without the full NVIDIA bundle.quantization– 4-bit and 8-bit model loading.
For the leanest install, omit the extras list entirely.
🍺 Homebrew (macOS)
brew tap avalan-ai/avalan
brew install avalan
🛠️ From Source with Poetry
poetry install --all-extras --with test
[!TIP] On macOS ensure the Xcode command line tools are present and install the build dependencies before compiling extras that rely on
sentencepiece:xcode-select --install brew install cmake pkg-config protobuf sentencepiece
When you need bleeding-edge transformers features, install the latest nightly:
poetry run pip install --no-cache-dir "git+https://github.com/huggingface/transformers"
⚡ Quickstart
💬 Call a hosted model from the CLI
Export a vendor key, then run:
export OPENAI_API_KEY=...
echo "Who are you, and who is Leo Messi?" \
| avalan model run "ai://env:OPENAI_API_KEY@openai/gpt-4o" \
--system "You are Aurora, a helpful assistant" \
--max-new-tokens 100
🐍 Use the Python SDK
import asyncio
from avalan.model.nlp.generation import TextGenerationModel
async def main() -> None:
with TextGenerationModel("ai://env:OPENAI_API_KEY@openai/gpt-4o") as model:
response = await model("Give me two facts about Leo Messi.")
print(response)
asyncio.run(main())
🧭 Next steps
- 📚 Browse docs/examples for runnable scripts across text, audio, vision, tools, and agent serving.
- 🧪 Jump to Models to search and install open models locally.
- 🤖 Jump to Agents to expose an agent over OpenAI-compatible HTTP, MCP, or A2A.
🧪 Models
Avalan exposes text, audio, and vision models from the CLI and Python. Use bare
model ids for open models and ai:// engine URIs for vendor-hosted models or
custom endpoints.
Vendor models
Avalan supports popular vendor models through engine URIs. The example below uses OpenAI's GPT-4o:
echo "Who are you, and who is Leo Messi?" \
| avalan model run "ai://env:OPENAI_API_KEY@openai/gpt-4o" \
--system "You are Aurora, a helpful assistant" \
--max-new-tokens 100 \
--temperature .1 \
--top-p .9 \
--top-k 20
Open models
Open models run across engines such as transformers, vllm, and mlx.
Search through millions of them with avalan model search using different
filters. The following command looks for up to three text-generation models that
run with the mlx backend, match the term DeepSeek-R1, and were published by
the MLX community:
avalan model search --name DeepSeek-R1 \
--library mlx \
--task text-generation \
--author "mlx-community" \
--limit 3
The command returns three matching models:
┌───── 📛 mlx-community/DeepSeek-R1-Distill-Qwen-14B 🧮 N/A params ─────┐
│ ✅ access granted 💼 mlx-community · 📆 updated: 4 months ago │
│ 📚 transformers · ⚙ text-generation │
└───────────────────────────────────────────────────────────────────────┘
┌───── 📛 mlx-community/DeepSeek-R1-Distill-Qwen-7B 🧮 N/A params ──────┐
│ ✅ access granted 💼 mlx-community · 📆 updated: 4 months ago │
│ 📚 transformers · ⚙ text-generation │
└───────────────────────────────────────────────────────────────────────┘
┌─ 📛 mlx-community/Unsloth-DeepSeek-R1-Distill-Qwen-14B-4bit 🧮 N/A pa─┐
│ ✅ access granted 💼 mlx-community · 📆 updated: 4 months ago │
│ 📚 transformers · ⚙ text-generation │
└───────────────────────────────────────────────────────────────────────┘
Install the first model:
avalan model install mlx-community/DeepSeek-R1-Distill-Qwen-14B
The model is now ready to use:
┌──── 📛 mlx-community/DeepSeek-R1-Distill-Qwen-14B 🧮 14.8B params ────┐
│ ✅ access granted 💼 mlx-community · 📆 updated: 4 months ago │
│ 🤖 qwen2 · 📚 transformers · ⚙ text-generation │
└───────────────────────────────────────────────────────────────────────┘
💾 Downloading model mlx-community/DeepSeek-R1-Distill-Qwen-14B:
Fetching 13 files 100% ━━━━━━━━━━━━━━━━━━━━━━━━━━━━ [ 13/13 - 0:04:15 ]
✔ Downloaded model mlx-community/DeepSeek-R1-Distill-Qwen-14B to
/Users/leo/.cache/huggingface/hub/models--mlx-community--DeepSeek-R1-
Distill-Qwen-14B/snapshots/68570f64bcc30966595926e3b7d200a9d77fb1e8
Test the model we just installed, specifying mlx as the backend:
[!TIP] You can choose your preferred backend using the
--backendoption. For example, on Apple Silicon Macs, themlxbackend typically offers a 3x speedup compared to the defaulttransformersbackend. On devices with access to Nvidia GPUs, models that run on the backendvllmare also orders of magnitude faster.
echo 'What is (4 + 6) and then that result times 5, divided by 2?' | \
avalan model run 'mlx-community/DeepSeek-R1-Distill-Qwen-14B' \
--temperature 0.6 \
--max-new-tokens 1024 \
--start-thinking \
--backend mlx
The output shows the reasoning and the correct final answer:
┌───────────────────────────────────────────────────────────────────────┐
│ ✅ access granted 💼 mlx-community │
└───────────────────────────────────────────────────────────────────────┘
🗣 What is (4 + 6) and then that result times 5, divided by 2?
┌─ mlx-community/DeepSeek-R1-Distill-Qwen-14B reasoning ────────────────┐
│ │
│ First, I will add 4 and 6 to get the result. │
│ Next, I will multiply that sum by 5. │
│ Then, I will divide the product by 2 to find the final answer. │
│ </think> │
│ │
└───────────────────────────────────────────────────────────────────────┘
┌───────────────────────────────────────────────────────────────────────┐
│ │
│ \] │
│ │
│ 3. **Divide the product by 2:** │
│ [ │
│ 50 \div 2 = 25 │
│ \] │
│ │
│ **Final Answer:** │
│ [ │
│ \boxed{25} │
│ │
└─ 💻 26 tokens in · 🧮 158 token out · 🌱 ttft: 1.14 s · ⚡ 14.90 t/s ─┘
Modalities
The following examples show each modality in action. Use the table of contents below to jump to the task you need:
- 🎧 Audio: Turn audio into text or produce speech for accessibility and media.
- 🦻 Audio classification: Label an audio based on sentiment.
- 🗣️ Speech recognition: Convert spoken audio to text.
- 🔊 Text to speech: Synthesize natural speech from text.
- 🎵 Audio generation: Generate or continue audio from prompts.
- 📝 Text: Understand, transform, and generate text across core NLP tasks.
- ❓ Question answering: Extract precise answers from context.
- 🏷️ Sequence classification: Classify text into labels.
- 🔁 Sequence to sequence: Rewrite or transform text-to-text.
- ✍️ Text generation: Produce completions and long-form responses.
- 🧩 Token classification: Label entities and token-level tags.
- 🌍 Translation: Translate text between languages.
- 👁️ Vision: Analyze images and create visual outputs from prompts.
- 🖼️ Encoder decoder: Caption images with encoder-decoder models.
- 🧪 Image classification: Predict image classes and scores.
- 📝 Image to text: Describe image content in natural language.
- 💬 Image text to text: Answer questions grounded in images.
- 🎯 Object detection: Detect and localize objects.
- 🧱 Semantic segmentation: Label each pixel by class.
- 🕺 Text to animation: Create animated clips from prompts.
- 🎨 Text to image: Generate images from text prompts.
- 🎬 Text to video: Generate short videos from prompts.
Audio
Audio classification
Determine the sentiment (neutral, happy, angry, sad) of a given audio file:
avalan model run "superb/hubert-base-superb-er" \
--modality audio_classification \
--path docs/examples/playground/oprah.wav \
--audio-sampling-rate 16000
And you'll get the likeliness of each sentiment:
┏━━━━━━━┳━━━━━━━┓
┃ Label ┃ Score ┃
┡━━━━━━━╇━━━━━━━┩
│ ang │ 0.49 │
├───────┼───────┤
│ hap │ 0.45 │
├───────┼───────┤
│ neu │ 0.04 │
├───────┼───────┤
│ sad │ 0.02 │
└───────┴───────┘
You can achieve the same result directly from Python:
from avalan.model.audio.classification import AudioClassificationModel
with AudioClassificationModel("superb/hubert-base-superb-er") as model:
labels = await model("oprah.wav", sampling_rate=16000)
print(labels)
For a runnable script, see docs/examples/audio_classification.py.
Speech recognition
Transcribe speech from an audio file:
avalan model run "facebook/wav2vec2-base-960h" \
--modality audio_speech_recognition \
--path docs/examples/playground/oprah.wav \
--audio-sampling-rate 16000
The output is the transcript of the provided audio:
AND THEN I GREW UP AND HAD THE ESTEEMED HONOUR OF MEETING HER AND WASN'T
THAT A SURPRISE HERE WAS THIS PETITE ALMOST DELICATE LADY WHO WAS THE
PERSONIFICATION OF GRACE AND GOODNESS
The SDK lets you do the same programmatically:
from avalan.model.audio.speech_recognition import SpeechRecognitionModel
with SpeechRecognitionModel("facebook/wav2vec2-base-960h") as model:
output = await model("oprah.wav", sampling_rate=16000)
print(output)
For a runnable script, see docs/examples/audio_speech_recognition.py.
Text to speech
Generate speech in Oprah's voice from a text prompt. The example uses an 18-second clip from her eulogy for Rosa Parks as a reference:
echo "[S1] Leo Messi is the greatest football player of all times." | \
avalan model run "nari-labs/Dia-1.6B-0626" \
--modality audio_text_to_speech \
--path example.wav \
--audio-reference-path docs/examples/playground/oprah.wav \
--audio-reference-text "[S1] And then I grew up and had the esteemed honor of meeting her. And wasn't that a surprise. Here was this petite, almost delicate lady who was the personification of grace and goodness."
In code you can generate speech in the same way:
from avalan.model.audio.speech import TextToSpeechModel
with TextToSpeechModel("nari-labs/Dia-1.6B-0626") as model:
await model(
"[S1] Leo Messi is the greatest football player of all times.",
"example.wav",
reference_path="docs/examples/playground/oprah.wav",
reference_text=(
"[S1] And then I grew up and had the esteemed honor of meeting her. "
"And wasn't that a surprise. Here was this petite, almost delicate "
"lady who was the personification of grace and goodness."
),
)
For a runnable script, see docs/examples/audio_text_to_speech.py.
Audio generation
Create a short melody from a text prompt:
echo "A funky riff about Leo Messi." |
avalan model run "facebook/musicgen-small" \
--modality audio_generation \
--max-new-tokens 1024 \
--path melody.wav
Using the library instead of the CLI:
from avalan.model.audio.generation import AudioGenerationModel
with AudioGenerationModel("facebook/musicgen-small") as model:
await model("A funky riff about Leo Messi.", "melody.wav", max_new_tokens=1024)
For a runnable script, see docs/examples/audio_generation.py.
Text
Question answering
Answer a question based on context using a question answering model:
echo "What sport does Leo play?" \
| avalan model run "deepset/roberta-base-squad2" \
--modality "text_question_answering" \
--text-context "Lionel Messi, known as Leo Messi, is an Argentine professional footballer widely regarded as one of the greatest football players of all time."
The answer comes as no surprise:
football
Or run it from your own script:
from avalan.model.nlp.question import QuestionAnsweringModel
with QuestionAnsweringModel("deepset/roberta-base-squad2") as model:
answer = await model(
"What sport does Leo play?",
context="Lionel Messi, known as Leo Messi, is an Argentine professional footballer widely regarded as one of the greatest football players of all time."
)
print(answer)
For a runnable script, see docs/examples/question_answering.py.
Sequence classification
Classify the sentiment of short text:
echo "We love Leo Messi." \
| avalan model run "distilbert-base-uncased-finetuned-sst-2-english" \
--modality "text_sequence_classification"
The result is positive as expected:
POSITIVE
The SDK version looks like this:
from avalan.model.nlp.sequence import SequenceClassificationModel
with SequenceClassificationModel("distilbert-base-uncased-finetuned-sst-2-english") as model:
output = await model("We love Leo Messi.")
print(output)
For a runnable script, see docs/examples/sequence_classification.py.
Sequence to sequence
Summarize text using a sequence-to-sequence model:
echo "
Andres Cuccittini, commonly known as Andy Cucci, is an Argentine
professional footballer who plays as a forward for the Argentina
national team. Regarded by many as the greatest footballer of all
time, Cucci has achieved unparalleled success throughout his career.
Born on July 25, 1988, in Ushuaia, Argentina, Cucci began playing
football at a young age and joined the Boca Juniors youth
academy.
" | avalan model run "facebook/bart-large-cnn" \
--modality "text_sequence_to_sequence"
The summary:
Andres Cuccittini, commonly known as Andy Cucci, is an Argentine professional
footballer. He plays as a forward for the Argentina national team. Cucci began
playing football at the age of 19 in his native Ushuaia.
Calling from Python is just as easy:
from avalan.model.nlp.sequence import SequenceToSequenceModel
with SequenceToSequenceModel("facebook/bart-large-cnn") as model:
output = await model("""
Andres Cuccittini, commonly known as Andy Cucci, is an Argentine
professional footballer who plays as a forward for the Argentina
national team. Regarded by many as the greatest footballer of all
time, Cucci has achieved unparalleled success throughout his career.
Born on July 25, 1988, in Ushuaia, Argentina, Cucci began playing
football at a young age and joined the Boca Juniors youth
academy.
""")
print(output)
For a runnable script, see docs/examples/seq2seq_summarization.py.
Text generation
Run a local model and control sampling with --temperature, --top-p, and --top-k. The example instructs the assistant to act as "Aurora" and limits the output to 100 tokens:
echo "Who are you, and who is Leo Messi?" \
| avalan model run "meta-llama/Meta-Llama-3-8B-Instruct" \
--system "You are Aurora, a helpful assistant" \
--max-new-tokens 100 \
--temperature .1 \
--top-p .9 \
--top-k 20 \
--backend mlx
Here's the equivalent Python snippet:
from avalan.entities import GenerationSettings
from avalan.model.nlp.text.generation import TextGenerationModel
with TextGenerationModel("meta-llama/Meta-Llama-3-8B-Instruct") as model:
async for token in await model(
"Who are you, and who is Leo Messi?",
system_prompt="You are Aurora, a helpful assistant",
settings=GenerationSettings(
max_new_tokens=100,
temperature=0.1,
top_p=0.9,
top_k=20
)
):
print(token, end="", flush=True)
Vendor APIs use the same interface. Swap in a vendor engine URI to call an external service. The example below uses OpenAI's GPT-4o with the same parameters:
echo "Who are you, and who is Leo Messi?" \
| avalan model run "ai://env:OPENAI_API_KEY@openai/gpt-4o" \
--system "You are Aurora, a helpful assistant" \
--max-new-tokens 100 \
--temperature .1 \
--top-p .9 \
--top-k 20
Swap in the vendor URI in code too:
from avalan.entities import GenerationSettings
from avalan.model.nlp.text.generation import TextGenerationModel
with TextGenerationModel("ai://env:OPENAI_API_KEY@openai/gpt-4o") as model:
async for token in await model(
"Who are you, and who is Leo Messi?",
system_prompt="You are Aurora, a helpful assistant",
settings=GenerationSettings(
max_new_tokens=100,
temperature=0.1,
top_p=0.9,
top_k=20
)
):
print(token, end="", flush=True)
For a runnable script, see docs/examples/text_generation.py.
Amazon Bedrock models use the same workflow. With your AWS credentials
configured (for example with AWS_PROFILE or environment variables),
you can target any Bedrock region via --base-url:
echo "Summarize the latest AWS re:Invent keynote in three bullet points." \
| avalan model run "ai://bedrock/us.amazon.nova-lite-v1:0" \
--base-url "us-east-1" \
--max-new-tokens 256 \
--temperature .7
Example output:
- **Hybrid and Multicloud**: AWS expanded its hybrid and multicloud capabilities with new services to help customers seamlessly connect their on-premises environments with AWS, and manage workloads across multiple clouds.
- **Security and Compliance**: AWS announced new security and compliance features to help customers meet their regulatory requirements and protect their data, including new services for data encryption, identity management, and threat detection.
These highlights capture some of the major themes and announcements from the keynote, but there were many more details and product updates as well. Hopefully this summary gives you a good overview! Let me know if you have any other
[!TIP] Some Bedrock models are only available through geo-prefixed IDs in a given source region, such as
us.anthropic.claude-sonnet-4-6for US Anthropic routing. Those profile IDs change over time, so you can inspect currently active options withaws bedrock list-inference-profiles --region us-east-1. Anthropic models can also require submitting the Bedrock use-case details form for your account before inference is allowed.
Token classification
Classify tokens with labels for Named Entity Recognition (NER) or Part-of-Speech (POS):
echo "
Lionel Messi, commonly known as Leo Messi, is an Argentine
professional footballer widely regarded as one of the
greatest football players of all time.
" | avalan model run "dslim/bert-base-NER" \
--modality text_token_classification \
--text-labeled-only
And you get the following labeled entities:
┏━━━━━━━━━━━┳━━━━━━━━┓
┃ Token ┃ Label ┃
┡━━━━━━━━━━━╇━━━━━━━━┩
│ Lionel │ B-PER │
├───────────┼────────┤
│ Me │ I-PER │
├───────────┼────────┤
│ ##ssi │ I-PER │
├───────────┼────────┤
│ Leo │ B-PER │
├───────────┼────────┤
│ Argentine │ B-MISC │
└───────────┴────────┘
Use the Python API if you prefer:
from avalan.model.nlp.token import TokenClassificationModel
with TokenClassificationModel("dslim/bert-base-NER") as model:
labels = await model(
"Lionel Messi, commonly known as Leo Messi, is an Argentine professional footballer widely regarded as one of the greatest football players of all time.",
labeled_only=True
)
print(labels)
For a runnable script, see docs/examples/token_classification.py.
Translation
Translate text between languages with a sequence-to-sequence model:
echo "
Lionel Messi, commonly known as Leo Messi, is an Argentine
professional footballer who plays as a forward for the Argentina
national team. Regarded by many as the greatest footballer of all
time, Messi has achieved unparalleled success throughout his career.
" | avalan model run "facebook/mbart-large-50-many-to-many-mmt" \
--modality "text_translation" \
--text-from-lang "en_US" \
--text-to-lang "es_XX" \
--text-num-beams 4 \
--text-max-length 512
Here is the Spanish version:
Lionel Messi, conocido también como Leo Messi, es un futbolista argentino
profesional que representa a la Argentina en el equipo nacional de Argentina.
Considerado por muchos como el futbolista más grande de todos los tiempos,
Messi ha conseguido un éxito sin precedentes durante su carrera.
The SDK call mirrors the CLI parameters:
from avalan.entities import GenerationSettings
from avalan.model.nlp.sequence import TranslationModel
with TranslationModel("facebook/mbart-large-50-many-to-many-mmt") as model:
output = await model(
"Lionel Messi, commonly known as Leo Messi, is an Argentine professional footballer who plays as a forward for the Argentina national team. Regarded by many as the greatest footballer of all time, Messi has achieved unparalleled success throughout his career.",
source_language="en_US",
destination_language="es_XX",
settings=GenerationSettings(
num_beams=4,
max_length=512
)
)
print(output)
For a runnable script, see docs/examples/seq2seq_translation.py.
Vision
Encoder decoder
Answer questions to extract information from an image, without using OCR.
echo "<s_docvqa><s_question>
What is the FACTURA Number?
</s_question><s_answer>" | \
avalan model run "naver-clova-ix/donut-base-finetuned-docvqa" \
--modality vision_encoder_decoder \
--path docs/examples/playground/invoice-factura.png
And you get the answer:
<s_docvqa>
<s_question> What is the FACTURA Number?</s_question>
<s_answer> 0012-00187506</s_answer>
</s>
Here's how you'd call it in a script:
from avalan.model.vision.decoder import VisionEncoderDecoderModel
with VisionEncoderDecoderModel("naver-clova-ix/donut-base-finetuned-docvqa") as model:
answer = await model(
"docs/examples/playground/invoice-factura.png",
prompt="<s_docvqa><s_question>What is the FACTURA Number?</s_question><s_answer>"
)
print(answer)
For a runnable script, see docs/examples/vision_encoder_decoder.py.
Image classification
Classify an image, such as determining whether it is a hot dog, or not a hot dog 🤓:
avalan model run "microsoft/resnet-50" \
--modality vision_image_classification \
--path docs/examples/playground/cat.jpg
The model identifies the image:
┏━━━━━━━━━━━━━━━━━━┓
┃ Label ┃
┡━━━━━━━━━━━━━━━━━━┩
│ tabby, tabby cat │
└──────────────────┘
Programmatic usage:
from avalan.model.vision.image import ImageClassificationModel
with ImageClassificationModel("microsoft/resnet-50") as model:
output = await model("docs/examples/playground/cat.jpg")
print(output)
For a runnable script, see docs/examples/vision_image_classification.py.
Image to text
Generate a caption for an image:
avalan model run "salesforce/blip-image-captioning-base" \
--modality vision_image_to_text \
--path docs/examples/playground/Example_Image_1.jpg
Example output:
a sign for a gas station on the side of a building [SEP]
Python snippet:
from avalan.model.vision.image import ImageToTextModel
with ImageToTextModel("salesforce/blip-image-captioning-base") as model:
caption = await model("docs/examples/playground/Example_Image_1.jpg")
print(caption)
For a runnable script, see docs/examples/vision_image_to_text.py.
Image text to text
Provide an image and an instruction to an image-text-to-text model:
echo "Transcribe the text on this image, keeping format" | \
avalan model run "ai://local/google/gemma-3-12b-it" \
--modality vision_image_text_to_text \
--path docs/examples/playground/typewritten_partial_sheet.jpg \
--vision-width 512 \
--max-new-tokens 1024
The transcription (truncated for brevity):
**INTRODUCCIÓN**
Guillermo de Ockham (según se utiliza la grafía latina o la inglesa) es tan
célebre como mal conocido. Su doctrina suele merecer las más diversas
interpretaciones, y su biografía adolece tremendas oscuridades.
Aún más, y como dice un renombrado autor, el estudio de su pensamiento "parece,
por la falta de buenas ediciones de sus obras, una consecuencia del ‘anatema’
que, durante siglos, ha pesado sobre el incipor del nominalismo" (1).
Invoke the model with the SDK like so:
from avalan.entities import GenerationSettings
from avalan.model.vision.image import ImageTextToTextModel
with ImageTextToTextModel("google/gemma-3-12b-it") as model:
output = await model(
"docs/examples/playground/typewritten_partial_sheet.jpg",
"Transcribe the text on this image, keeping format",
settings=GenerationSettings(max_new_tokens=1024),
width=512
)
print(output)
For a runnable script, see docs/examples/vision_ocr.py.
Object detection
Detect objects in an image and list them with accuracy scores:
avalan model run "facebook/detr-resnet-50" \
--modality vision_object_detection \
--path docs/examples/playground/kitchen.jpg \
--vision-threshold 0.3
Results are sorted by accuracy and include bounding boxes:
┏━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Label ┃ Score ┃ Box ┃
┡━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ refrigerator │ 1.00 │ 855.28, 377.27, 1035.67, 679.42 │
├──────────────┼───────┼──────────────────────────────────┤
│ oven │ 1.00 │ 411.62, 570.92, 651.66, 872.05 │
├──────────────┼───────┼──────────────────────────────────┤
│ potted plant │ 0.99 │ 1345.95, 498.15, 1430.21, 603.84 │
├──────────────┼───────┼──────────────────────────────────┤
│ sink │ 0.96 │ 1077.43, 631.51, 1367.12, 703.23 │
├──────────────┼───────┼──────────────────────────────────┤
│ potted plant │ 0.94 │ 179.69, 557.44, 317.14, 629.77 │
├──────────────┼───────┼──────────────────────────────────┤
│ vase │ 0.83 │ 1357.88, 562.67, 1399.38, 616.44 │
├──────────────┼───────┼──────────────────────────────────┤
│ handbag │ 0.72 │ 287.08, 544.47, 332.73, 602.24 │
├──────────────┼───────┼──────────────────────────────────┤
│ sink │ 0.68 │ 1079.68, 627.04, 1495.40, 714.07 │
├──────────────┼───────┼──────────────────────────────────┤
│ bird │ 0.38 │ 628.57, 536.31, 666.62, 574.39 │
├──────────────┼───────┼──────────────────────────────────┤
│ sink │ 0.35 │ 1077.98, 629.29, 1497.90, 723.95 │
├──────────────┼───────┼──────────────────────────────────┤
│ spoon │ 0.31 │ 646.69, 505.31, 673.04, 543.10 │
└──────────────┴───────┴──────────────────────────────────┘
Example SDK call:
from avalan.model.vision.detection import ObjectDetectionModel
with ObjectDetectionModel("facebook/detr-resnet-50") as model:
labels = await model("docs/examples/playground/kitchen.jpg", threshold=0.3)
print(labels)
For a runnable script, see docs/examples/vision_object_detection.py.
Semantic segmentation
Classify each pixel using a semantic segmentation model:
avalan model run "nvidia/segformer-b0-finetuned-ade-512-512" \
--modality vision_semantic_segmentation \
--path docs/examples/playground/kitchen.jpg
The output lists each annotation:
┏━━━━━━━━━━━━━━━━━━┓
┃ Label ┃
┡━━━━━━━━━━━━━━━━━━┩
│ wall │
├──────────────────┤
│ floor │
├──────────────────┤
│ ceiling │
├──────────────────┤
│ windowpane │
├──────────────────┤
│ cabinet │
├──────────────────┤
│ door │
├──────────────────┤
│ plant │
├──────────────────┤
│ rug │
├──────────────────┤
│ lamp │
├──────────────────┤
│ chest of drawers │
├──────────────────┤
│ sink │
├──────────────────┤
│ refrigerator │
├──────────────────┤
│ flower │
├──────────────────┤
│ stove │
├──────────────────┤
│ kitchen island │
├──────────────────┤
│ light │
├──────────────────┤
│ chandelier │
├──────────────────┤
│ oven │
├──────────────────┤
│ microwave │
├──────────────────┤
│ dishwasher │
├──────────────────┤
│ hood │
├──────────────────┤
│ vase │
├──────────────────┤
│ fan │
└──────────────────┘
This is how you'd do it in code:
from avalan.model.vision.segmentation import SemanticSegmentationModel
with SemanticSegmentationModel("nvidia/segformer-b0-finetuned-ade-512-512") as model:
labels = await model("docs/examples/playground/kitchen.jpg")
print(labels)
For a runnable script, see docs/examples/vision_semantic_segmentation.py.
Text to animation
Create an animation from a prompt using a base model for styling:
echo 'A tabby cat slowly walking' | \
avalan model run "ByteDance/AnimateDiff-Lightning" \
--modality vision_text_to_animation \
--base-model "stablediffusionapi/mistoonanime-v30" \
--checkpoint "animatediff_lightning_4step_diffusers.safetensors" \
--weight "fp16" \
--path example_cat_walking.gif \
--vision-beta-schedule "linear" \
--vision-guidance-scale 1.0 \
--vision-steps 4 \
--vision-timestep-spacing "trailing"
And here's the generated anime inspired animation of a walking cat:

SDK usage:
from avalan.entities import EngineSettings
from avalan.model.vision.diffusion import TextToAnimationModel
with TextToAnimationModel("ByteDance/AnimateDiff-Lightning", settings=EngineSettings(base_model_id="stablediffusionapi/mistoonanime-v30", checkpoint="animatediff_lightning_4step_diffusers.safetensors", weight_type="fp16")) as model:
await model(
"A tabby cat slowly walking",
"example_cat_walking.gif",
beta_schedule="linear",
guidance_scale=1.0,
steps=4,
timestep_spacing="trailing"
)
For a runnable script, see docs/examples/vision_text_to_animation.py.
Text to image
Create an image from a text prompt:
echo 'Leo Messi petting a purring tubby cat' | \
avalan model run "stabilityai/stable-diffusion-xl-base-1.0" \
--modality vision_text_to_image \
--refiner-model "stabilityai/stable-diffusion-xl-refiner-1.0" \
--weight "fp16" \
--path example_messi_petting_cat.jpg \
--vision-color-model RGB \
--vision-image-format JPEG \
--vision-high-noise-frac 0.8 \
--vision-steps 150
Here is the generated image of Leo Messi petting a cute cat:

You can also create images from Python:
from avalan.entities import TransformerEngineSettings
from avalan.model.vision.diffusion import TextToImageModel
with TextToImageModel("stabilityai/stable-diffusion-xl-base-1.0", settings=TransformerEngineSettings(refiner_model_id="stabilityai/stable-diffusion-xl-refiner-1.0", weight_type="fp16")) as model:
await model(
"Leo Messi petting a purring tubby cat",
"example_messi_petting_cat.jpg",
color_model="RGB",
image_format="JPEG",
high_noise_frac=0.8,
n_steps=150
)
For a runnable script, see docs/examples/vision_text_to_image.py.
Text to video
Create an MP4 video from a prompt, using a negative prompt for guardrails and an image as reference:
echo 'A cute little penguin takes out a book and starts reading it' | \
avalan model run "Lightricks/LTX-Video-0.9.7-dev" \
--modality vision_text_to_video \
--upsampler-model "Lightricks/ltxv-spatial-upscaler-0.9.7" \
--weight "fp16" \
--vision-steps 30 \
--vision-negative-prompt "worst quality, inconsistent motion, blurry, jittery, distorted" \
--vision-inference-steps 10 \
--vision-reference-path docs/examples/playground/penguin.png \
--vision-width 832 \
--vision-height 480 \
--vision-frames 96 \
--vision-fps 24 \
--vision-decode-timestep 0.05 \
--vision-denoise-strength 0.4 \
--path example_text_to_video.mp4
And here's the generated video:

Python example:
from avalan.entities import EngineSettings
from avalan.model.vision.diffusion import TextToVideoModel
with TextToVideoModel("Lightricks/LTX-Video-0.9.7-dev", settings=EngineSettings(upsampler_model_id="Lightricks/ltxv-spatial-upscaler-0.9.7", weight_type="fp16")) as model:
await model(
"A cute little penguin takes out a book and starts reading it",
"worst quality, inconsistent motion, blurry, jittery, distorted",
"docs/examples/playground/penguin.png",
"example_text_to_video.mp4",
steps=30,
inference_steps=10,
width=832,
height=480,
frames=96,
fps=24,
decode_timestep=0.05,
denoise_strength=0.4
)
For a runnable script, see docs/examples/vision_text_to_video.py.
Tools
Avalan makes it simple to launch a chat-based agent that can call external tools while streaming tokens. Avalan ships native helpers for math.calculator, code.run, browser.open, database.*, memory, and MCP integrations so agents can reason with numbers, execute code, browse the web, and interact with SQL databases from a single prompt.
[!NOTE] Keep a human in the loop by adding
--tools-confirmwhen you run an agent. Avalan will ask you to confirm each tool call before it executes, so you retain control over side effects.
Math toolset (math.*)
Use the math toolset whenever your agent needs deterministic arithmetic or algebraic answers. The calculator tool delegates evaluation to SymPy, making it ideal for verifying multi-step computations instead of relying on approximate language model reasoning.
Available tools
math.calculator(expression: str) -> str: Evaluate an arithmetic expression (including parentheses and operator precedence) and return the numeric result as a string.
Example: math.calculator
The example below uses a local 8B LLM, enables recent memory, and loads a calculator tool. The agent begins with a math question and stays open for follow-ups:
echo "What is (4 + 6) and then that result times 5, divided by 2?" \
| avalan agent run \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--tool "math.calculator" \
--memory-recent \
--run-max-new-tokens 8192 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--display-events \
--display-tools \
--conversation
Notice the GPU utilization at the bottom:

You can give your GPU some breathing type by running the same on a vendor model, like Anthropic:
echo "What is (4 + 6) and then that result times 5, divided by 2?" \
| avalan agent run \
--engine-uri "ai://$ANTHROPIC_API_KEY@anthropic/claude-sonnet-4-6" \
--tool "math.calculator" \
--memory-recent \
--run-max-new-tokens 8192 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--display-events \
--display-tools \
--conversation
Code toolset (code.*)
Reach for the code toolset when the agent should write, execute, or refactor source code in a controlled environment. Execution happens inside a RestrictedPython sandbox and pattern searches are backed by the ast-grep CLI, enabling agents to safely prototype logic, manipulate files, or build refactoring plans.
Available tools
code.run(code: str, *args, **kwargs) -> str: Execute a snippet that defines arunfunction and return the function result as text, which is useful for testing generated utilities or validating calculations programmatically.code.search.ast.grep(pattern: str, lang: str, rewrite: str | None = None, paths: list[str] | None = None) -> str: Search or rewrite codebases using structural patterns, helping agents answer "where is this API used?" or propose targeted edits.
Example: code.run
Below is an agent that leverages the code.run tool to execute Python code generated by the model and display the result:
echo "Create a python function to uppercase a string, split it spaces, and then return the words joined by a dash, and execute the function with the string 'Leo Messi is the greatest footballer of all times'" \
| avalan agent run \
--engine-uri 'ai://local/openai/gpt-oss-20b' \
--backend mlx \
--tool-format harmony \
--tool "code.run" \
--memory-recent \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--display-events \
--display-tools \
--backend mlx
Database toolset (database.*)
Connect the database toolset when an agent must inspect schemas, understand query plans, or run SQL against an external data source. Tools share a pooled SQLAlchemy engine, enforce optional read-only policies, and normalize identifier casing so that agents can explore data safely.
When your agent needs live access to data, configure the database toolset. In the example below we point the agent to a Supabase database, and after prompting for sales data we'll see the agent executing database.tables and database.inspect to understand the schema, before running SQL with database.run:
[!IMPORTANT] Database sessions are read-only by default (
read_only = true) and only permitSELECTstatements unless you relax the policy. Adjust these safeguards with the database tool settings—for example, setallowed_commands = ["select", "insert"](or pass--tool-database-allowed-commands select,inserton the CLI) and toggleread_onlyin your agent specification when you need to allow writes.
echo "Get me revenue per product, sorting by highest selling" | \
avalan agent run \
--engine-uri "ai://local/openai/gpt-oss-20b" \
--backend mlx \
--tool-format harmony \
--tool "database" \
--tool-database-dsn "postgresql+asyncpg://postgres.project_id:password@aws-1-us-east-1.pooler.supabase.com:5432/postgres" \
--system "Reasoning: high" \
--developer "You are a helpful assistant that can resolve user data requests using database tools." \
--stats \
--display-tools
Available tools
database.count(table_name: str) -> int: Return the number of rows in a table—handy for quick health checks or progress reporting.database.inspect(table_names: list[str], schema: str | None = None) -> list[Table]: Describe table columns and foreign keys so the agent can reason about relationships before writing SQL.database.keys(table_name: str, schema: str | None = None) -> list[TableKey]: Enumerate primary and unique key definitions so the agent understands table-level uniqueness guarantees.database.relationships(table_name: str, schema: str | None = None) -> list[TableRelationship]: Surface incoming and outgoing foreign key links for a table so the agent can understand join paths and cardinality constraints.database.plan(sql: str) -> QueryPlan: Request anEXPLAINplan to validate or optimize a generated query.database.run(sql: str) -> list[dict[str, Any]]: Execute read or write statements (subject to policy) and return result rows for downstream reasoning.database.sample(table_name: str, columns: list[str] | None = None, conditions: str | None = None, order: dict[str, str] | None = None, count: int | None = None) -> list[dict[str, Any]]: Fetch up tocountrows (default 10) from a table so agents can preview data, optionally narrowing by columns, SQL conditions, or ordering before crafting more complex queries.database.locks() -> list[DatabaseLock]: Inspect PostgreSQL, MySQL, and MariaDB lock metadata—including blocking session IDs, lock targets, and whether the lock is granted—to debug contention before running or terminating queries.database.tables() -> dict[str | None, list[str]]: List tables grouped by schema—useful for schema discovery in unknown databases.database.tasks(running_for: int | None = None) -> list[DatabaseTask]: Surface long-running queries on PostgreSQL or MySQL so humans can monitor or intervene.database.kill(task_id: str) -> bool: Cancel a runaway query when safeguards permit it.database.size(table_name: str) -> TableSize: Summarize how much space a table occupies, including data and index bytes where the backend provides them, so agents can gauge storage usage before recommending optimizations.
Browser toolset (browser.*)
Use the browser toolset to capture live information from the web or intranet sites. The Playwright-backed browser renders pages, converts them to Markdown, and can optionally search the captured content to keep only the most relevant snippets for the agent.
Available tools
browser.open(url: str) -> str: Navigate to a URL and return the rendered page in Markdown, optionally narrowed to search results derived from the user prompt.
Tools give agents real-time knowledge. This example uses an 8B model and a browser tool to find avalan's latest release:
echo "What's avalan's latest release on https://github.com/avalan-ai/avalan/releases" | \
avalan agent run \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--tool "browser.open" \
--memory-recent \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--display-events \
--display-tools \
--backend mlx
You may need to update playwright browser images with poetry run playwright install
When using the browser tool to extract knowledge, be mindful of your context window. With OpenAI's gpt-oss-20b, the model processes 7261 input tokens before producing a final response. When browser context search is enabled (using --tool-browser-search and --tool-browser-search-context), that number decreases to 1443 input tokens, and the response time improves proportionally:
echo "What's avalan's latest release on https://github.com/avalan-ai/avalan/releases" | \
avalan agent run \
--engine-uri 'ai://local/openai/gpt-oss-20b' \
--tool-format harmony \
--tool "browser.open" \
--tool-browser-search \
--tool-browser-search-context 10 \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--display-tools \
--backend mlx
Memory toolset (memory.*)
Add the memory toolset when agents should consult past conversations or long-lived knowledge bases. The tools can retrieve prior user messages, search permanent vector memories, list stored entries, or enumerate available stores so the agent knows where to look.
Available tools
memory.message.read(search: str) -> str: Retrieve user-specific context from prior sessions, returningNOT_FOUNDwhen no match exists.memory.read(namespace: str, search: str) -> list[PermanentMemoryPartition]: Fetch chunks of long-term knowledge inside a namespace for grounding responses.memory.list(namespace: str) -> list[Memory]: Enumerate stored memories in a namespace so the agent can decide which entries to reuse.memory.stores() -> list[PermanentMemoryStore]: List permanent memory stores available to the agent for broader exploration.
See Memories for sample usage.
YouTube toolset (youtube.*)
Use the YouTube toolset to ground responses in video transcripts—great for summarizing talks or extracting key quotes without manual downloads. Proxy support keeps the integration flexible for restricted networks.
Available tools
youtube.transcript(video_id: str, languages: Iterable[str] | None = None) -> list[str]: Fetch ordered transcript snippets for a given video, optionally prioritizing specific languages.
MCP toolset (mcp.*)
Integrate Model Context Protocol (MCP) servers to orchestrate specialized remote tools. The MCP toolset lets avalan agents proxy any MCP-compatible capability via a single tool call.
Available tools
mcp.call(uri: str, name: str, arguments: dict[str, object] | None) -> list[object]: Connect to an MCP server and invoke one of its tools with structured arguments, returning the raw MCP responses.
Search tool (search_engine.search)
For quick demos or testing, Avalan also provides a stubbed search tool that illustrates how to wire internet lookups into an agent. Replace its implementation with a real provider to give agents access to live search APIs.
Reasoning strategies
Avalan supports several reasoning approaches for guiding agents through complex problems.
Reasoning models
Reasoning models that emit thinking tags are natively supported. Here's OpenAI's gpt-oss 20B solving a simple calculation:
echo 'What is (4 + 6) and then that result times 5, divided by 2?' | \
avalan model run 'ai://local/openai/gpt-oss-20b' \
--max-new-tokens 1024 \
--backend mlx
The response includes the model reasoning, and its final answer:
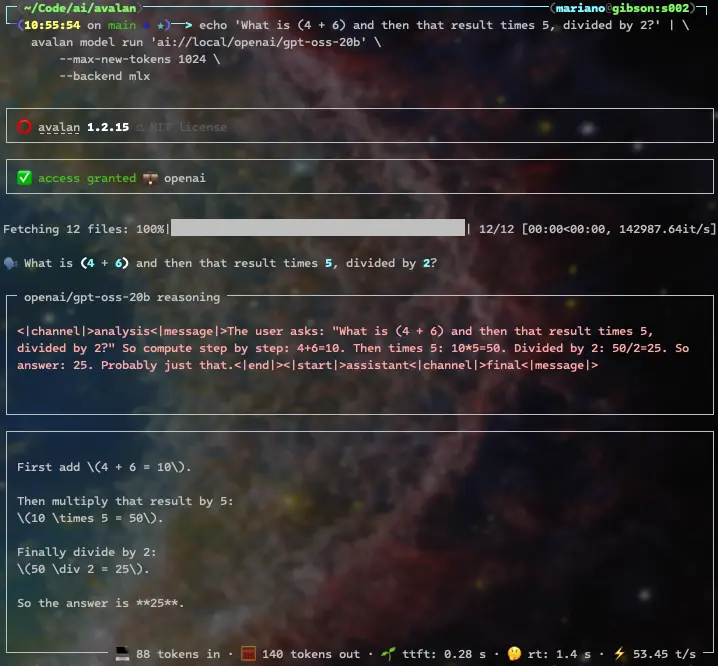
Some of them, like DeepSeek-R1-Distill-Qwen-14B, assume the model starts thinking without a thinking tag, so we'll use --start-thinking:
echo 'What is (4 + 6) and then that result times 5, divided by 2?' | \
avalan model run 'deepseek-ai/DeepSeek-R1-Distill-Qwen-14B' \
--temperature 0.6 \
--max-new-tokens 1024 \
--start-thinking \
--backend mlx
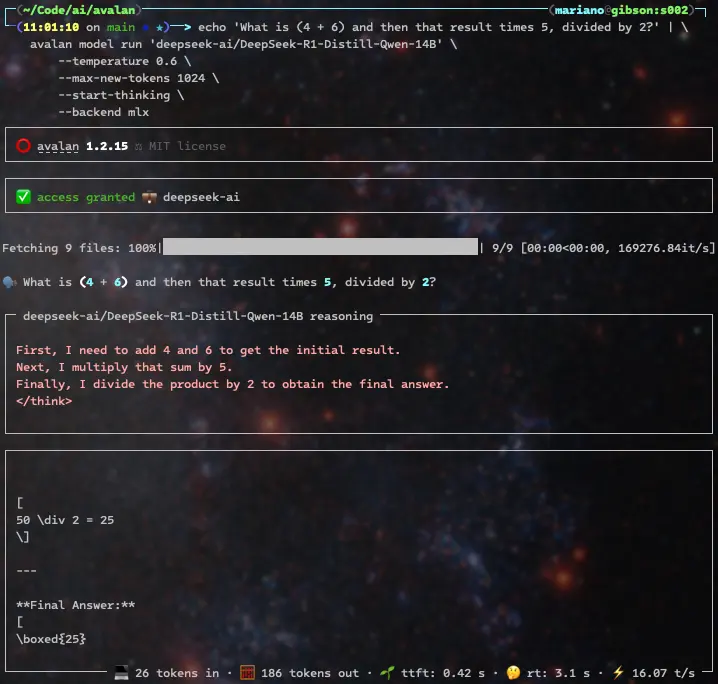
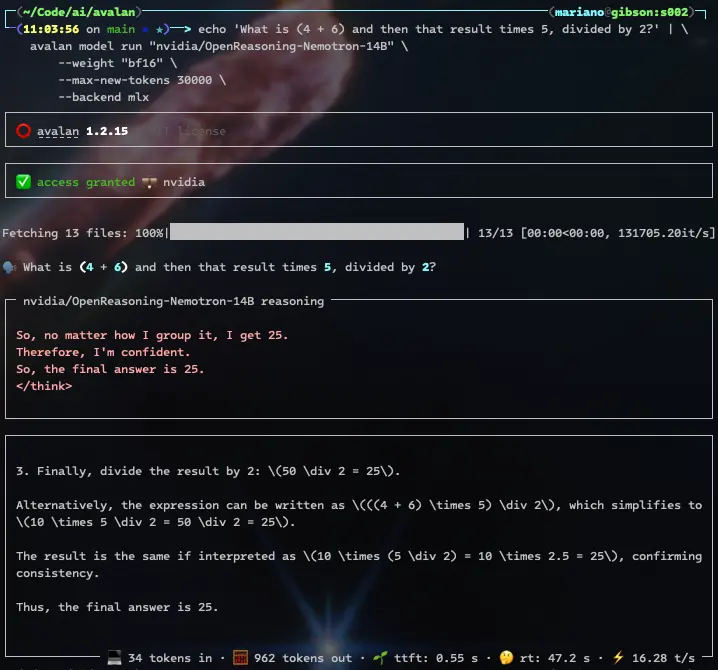
Nvidia's Nemotron reasoning model solves the same problem easily and doesn't require the --start-thinking flag, since it automatically produces think tags. It does so more verbosely, though (962 output tokens versus DeepSeek's 186 output tokens or OpenAI's more concise 140 tokens), since it detects ambiguity in the and then that result part of the prompt and ends up revisiting the essential principles of mathematics, to the point of realizing it's overthinking 🤓
[!TIP] Endless reasoning rants can be stopped by setting
--reasoning-max-new-tokensto the maximum number of reasoning tokens allowed, and adding--reasoning-stop-on-max-new-tokensto finish generation when that limit is reached.
echo 'What is (4 + 6) and then that result times 5, divided by 2?' | \
avalan model run "nvidia/OpenReasoning-Nemotron-14B" \
--weight "bf16" \
--max-new-tokens 30000 \
--backend mlx
When using reasoning models, be mindful of your total token limit. Some reasoning models include limit recommendations on their model cards, like the following model from Z.ai:
echo 'What is (4 + 6) and then that result times 5, divided by 2?' | \
avalan model run 'zai-org/GLM-Z1-32B-0414' \
--temperature 0.6 \
--top-p .95 \
--top-k 40 \
--max-new-tokens 30000 \
--start-thinking \
--backend mlx
ReACT
ReACT interleaves reasoning with tool use so an agent can think through steps and take actions in turn.
You can direct an agent to read specific locations for knowledge:
echo "Tell me what avalan does based on the web page https://raw.githubusercontent.com/avalan-ai/avalan/refs/heads/main/README.md" | \
avalan agent run \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--tool "browser.open" \
--memory-recent \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--display-events \
--display-tools \
--backend mlx
and you'll get the model's interpretation of what Avalan does based on its README.md file on github:
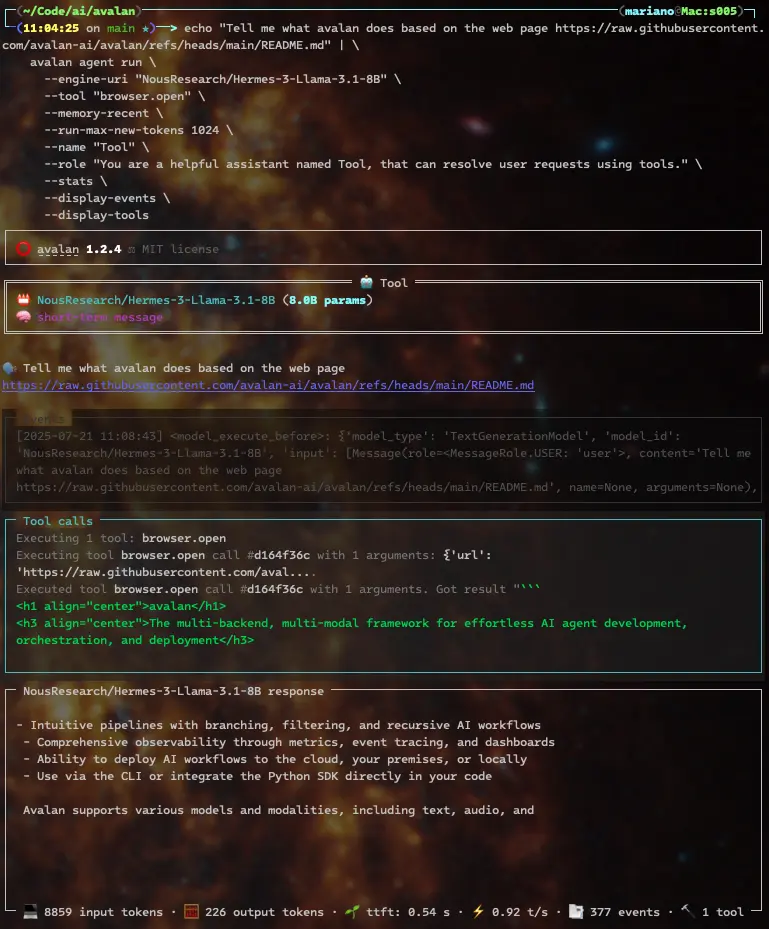
Chain-of-Thought
Chain-of-Thought builds sequential reasoning traces to reach an answer for tasks that require intermediate logic.
Tree-of-Thought
Tree-of-Thought explores multiple branches of reasoning in parallel to select the best path for difficult decisions.
Plan-and-Reflect
Plan-and-Reflect has the agent outline a plan, act, and then review the results, promoting methodical problem solving.
Self-Consistency
Self-Consistency samples several reasoning paths and aggregates them to produce more reliable answers.
Scratchpad-Toolformer
Scratchpad-Toolformer combines an internal scratchpad with learned tool usage to manipulate intermediate results.
Cascaded Prompting
Cascaded Prompting chains prompts so each step refines the next, ideal for multi-stage instructions.
Critic-Guided Direction-Following Experts
Critic-Guided Direction-Following Experts use a critic model to guide expert models when strict quality is required.
Product-of-Experts
Product-of-Experts merges the outputs of several experts to generate answers that benefit from multiple viewpoints.
Memories
Avalan offers a unified memory API with native implementations for PostgreSQL (using pgvector), Elasticsearch, AWS Opensearch, and AWS S3 Vectors.
Start a chat session and tell the agent your name. The --memory-permanent-message option specifies where messages are stored, --id uniquely identifies the agent, and --participant sets the user ID:
echo "Hi Tool, my name is Leo. Nice to meet you." \
| avalan agent run \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--memory-recent \
--memory-permanent-message "postgresql://root:password@localhost/avalan" \
--id "f4fd12f4-25ea-4c81-9514-d31fb4c48128" \
--participant "c67d6ec7-b6ea-40db-bf1a-6de6f9e0bb58" \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--backend mlx
Enable persistent memory and the memory.message.read tool so the agent can recall earlier messages. It should discover that your name is Leo from the previous conversation:
echo "Hi Tool, based on our previous conversations, what's my name?" \
| avalan agent run \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--tool "memory.message.read" \
--memory-recent \
--memory-permanent-message "postgresql://root:password@localhost/avalan" \
--id "f4fd12f4-25ea-4c81-9514-d31fb4c48128" \
--participant "c67d6ec7-b6ea-40db-bf1a-6de6f9e0bb58" \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--backend mlx
Agents can use knowledge stores to solve problems. Index the rules of the "Truco" card game directly from a website. The --dsn parameter sets the store location and --namespace chooses the knowledge namespace:
avalan memory document index \
--participant "c67d6ec7-b6ea-40db-bf1a-6de6f9e0bb58" \
--dsn "postgresql://root:password@localhost/avalan" \
--namespace "games.cards.truco" \
"sentence-transformers/all-MiniLM-L6-v2" \
"https://trucogame.com/pages/reglamento-de-truco-argentino"
Create an agent, give it access to the indexed memory store and the memory tool, and your question:
[!TIP] If you rather create a permanent agent, see the equivalent agent_memory.toml agent definition.
echo "What does the memory stored in namespace games.cards.truco say about retrucar?" | \
avalan agent run \
--engine-uri "ai://local/openai/gpt-oss-20b" \
--tool-format harmony \
--tool memory \
--system "Reasoning: high" \
--developer "You are an expert assistant that can use the memory tool to answer questions about card games." \
--memory-recent \
--memory-engine-model-id "sentence-transformers/all-MiniLM-L6-v2" \
--memory-engine-max-tokens 500 \
--memory-engine-overlap 125 \
--memory-engine-window 250 \
--memory-permanent "games.cards.truco@postgresql://root:password@localhost/avalan" \
--run-max-new-tokens 8192 \
--run-temperature 0.1 \
--run-top-p 0.9 \
--run-top-k 40 \
--participant "c67d6ec7-b6ea-40db-bf1a-6de6f9e0bb58" \
--backend mlx
And you should get your answer:
<|channel|>analysis<|message|>The user asks: "What does the memory stored in namespace games.cards.truco say about retrucar?" They want to retrieve memory from namespace games.cards.truco about retrucar. We need to use memory.read function. Search for "retrucar".<|end|><|start|>assistant<|channel|>commentary to=functions.memory.read <|constrain|>json<|message|>{"namespace":"games.cards.truco","search":"retrucar"}<|call|><|channel|>analysis<|message|>The memory returned a list of strings. We need to extract the relevant part about retrucar. The relevant parts are:
- "Siempre tiene la potestad de retrucar únicamente **el que ha querido la última apuesta**."
- "El equipo que ha retrucado ya no puede subir la apuesta, solo podrá hacerlo el equipo contrario, a esto se lo denomina 'tener el quiero'."
- "El equipo que ha querido el Truco tendrá ahora la posibilidad de retrucar en cualquier momento."
We need to summarize. The user asked: "What does the memory stored in namespace games.cards.truco say about retrucar?" So we should provide the content. Let's produce a concise answer summarizing the memory.<|end|><|start|>assistant<|channel|>final<|message|>In the **games.cards.truco** memory, the rules for **retrucar** are summarized as follows:
| What it is | How it works | Who can do it | What happens after |
|------------|--------------|---------------|--------------------|
| **Retrucar** | The act of raising the stakes after a *Truco* has been called. | Only the team that has **accepted** the last bet (i.e., said “Quiero”) can retrucar. | The team that retrucado **cannot raise the bet again**; only the opposing team can do so. This state is sometimes called “tener el quiero.” |
| | | | The team that has just retrucado can no longer raise the stakes until the other side does. |
| | | | The opposing team, if they want to raise again, must say “Quiero Retruco.” |
| | | | The team that has already retrucado is then “locked” into the current stake level until the other side raises. |
In short, **retrucar** is a counter‑raise that can only be made by the team that accepted the previous bet, and once it’s done, that team cannot raise the stakes again until the opponent does.%
PDF files are natively supported by memories. Let's index an arxiv paper (in its PDF format) from September 2025, considerably after the training date of the model we'll later use to query it:
avalan memory document index \
--participant "c67d6ec7-b6ea-40db-bf1a-6de6f9e0bb58" \
--dsn "postgresql://root:password@localhost/avalan" \
--namespace "papers.arxiv" \
"sentence-transformers/all-MiniLM-L6-v2" \
"https://arxiv.org/pdf/2509.17325"
Now let's ask the memory agent about that paper (notice the description added when defining the memory store with --memory-permanent):
echo "What papers do you have in memory?" | \
avalan agent run \
--engine-uri "ai://local/openai/gpt-oss-20b" \
--tool-format harmony \
--tool memory \
--system "Reasoning: high" \
--developer "You are an expert assistant that can use the memory tool to answer questions about card games." \
--memory-recent \
--memory-engine-model-id "sentence-transformers/all-MiniLM-L6-v2" \
--memory-engine-max-tokens 500 \
--memory-engine-overlap 125 \
--memory-engine-window 250 \
--memory-permanent "papers.arxiv@postgresql://root:password@localhost/avalan,Papers from ARXIV" \
--run-max-new-tokens 8192 \
--run-temperature 0.1 \
--run-top-p 0.9 \
--run-top-k 40 \
--participant "c67d6ec7-b6ea-40db-bf1a-6de6f9e0bb58" \
--backend mlx
And the stored paper is found:
<|channel|>analysis<|message|>The user asks: "What papers do you have in memory?" They want to know what papers are stored in memory. We need to list the papers. We have memory stores. We can call memory.stores to see available memory stores . Then memory.list for each store. Then memory.read for each paper. But we need to list the papers. The user likely wants a list of paper titles. We can use memory.list to get the list of keys. Then memory.read to get the content. But we just need to list the papers. So we can call memory.stores to get store names. Then for each store, call memory.list. Then compile a list of paper titles. Let's do that.<|end|><|start|>assistant<|channel|>commentary to=functions.memory.stores <|constrain|>json<|message|>{}<|call|><|channel|>analysis<|message|>We have one memory store: "papers.arxiv". Let's list it.<|end|><|start|>assistant<|channel|>commentary to=functions.memory.list<|channel|>commentary <|constrain|>json<|message|>{"namespace":"papers.arxiv"}<|call|><|channel|>analysis<|message|>The list shows two Memory objects, both with the same identifier 'https://arxiv.org/pdf/2509.17325', but with different partitions and created_at times. They both have the title 'Generalizable End-to-End Tool-Use RL with Synthetic CodeGym'. So the only paper in memory is that one. The user asked: "What papers do you have in memory?" So we should answer: "I have one paper: Generalizable End-to-End Tool-Use RL with Synthetic CodeGym (arXiv:2509.17325)". We can mention that it's stored twice with different partitions. Let's respond.<|end|><|start|>assistant<|channel|>final<|message|>I have one paper stored in memory:
- **Generalizable End‑to‑End Tool‑Use RL with Synthetic CodeGym**
- **Source:** arXiv (https://arxiv.org/pdf/2509.17325)
- **Details:** The paper discusses a scalable framework called CodeGym for training large language model agents to use tools in diverse, verifiable, multi‑turn environments. It highlights the generalizability of these agents across out‑of‑distribution benchmarks.%
Agents
You can easily create AI agents from configuration files. Let's create one to handle gettext translations. Create a file named agent_gettext_translator.toml with the following contents:
[agent]
role = """
You are an expert translator that specializes in translating gettext
translation files.
"""
task = """
Your task is to translate the given gettext template file,
from the original {{source_language}} to {{destination_language}}.
"""
instructions = """
The text to translate is marked with `msgid`, and it's quoted.
Your translation should be defined in `msgstr`.
"""
rules = [
"""
Ensure you keep the gettext format intact, only altering
the `msgstr` section.
""",
"""
Respond only with the translated file.
"""
]
[template]
source_language = "English"
destination_language = "Spanish"
[engine]
uri = "meta-llama/Meta-Llama-3-8B-Instruct"
[run]
use_cache = true
max_new_tokens = 1024
skip_special_tokens = true
You can now run your agent. Let's give it a gettext translation template file, have our agent translate it for us, and show a visual difference of what the agent changed:
icdiff locale/avalan.pot <(
cat locale/avalan.pot |
avalan agent run docs/examples/agent_gettext_translator.toml --quiet
)
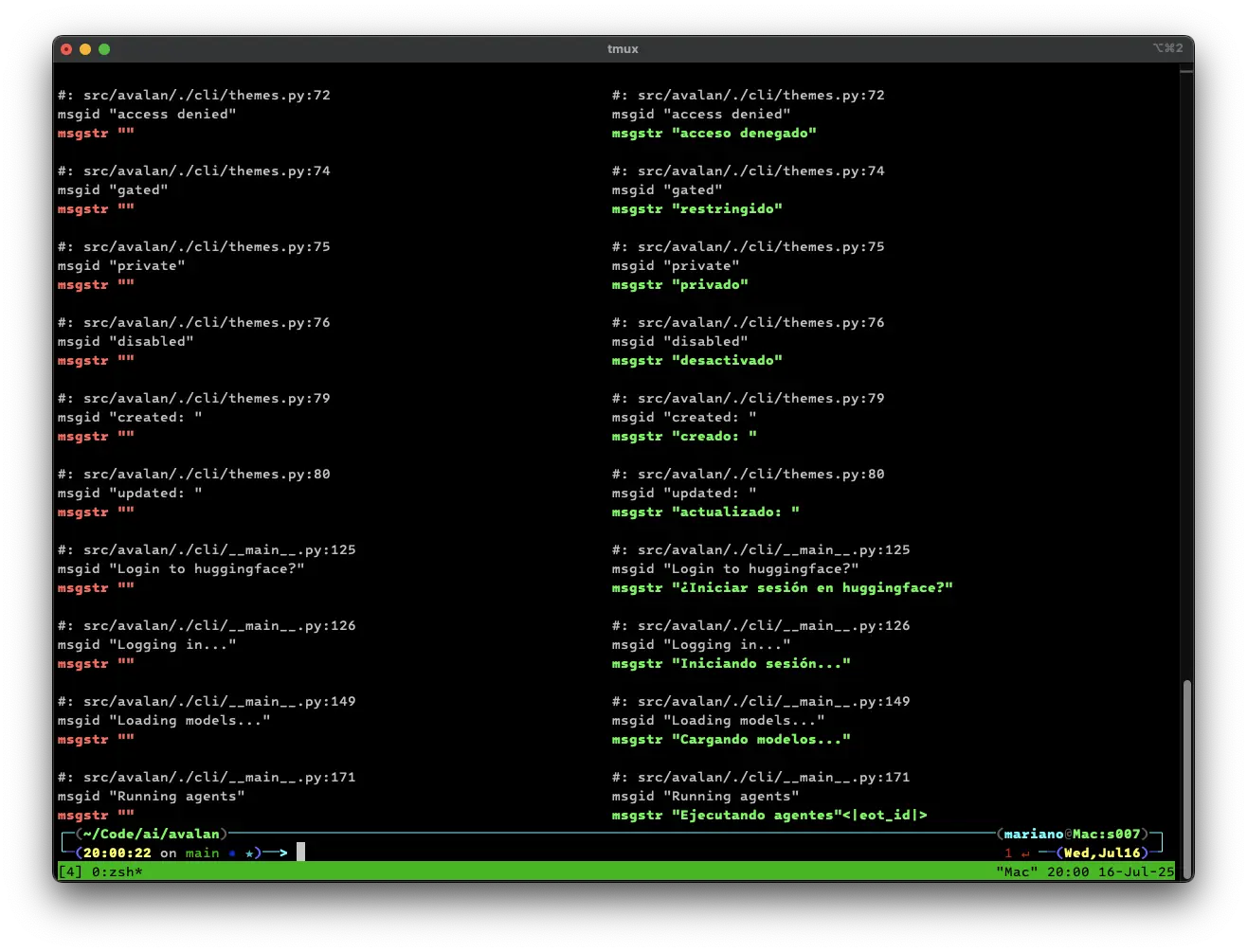
There are more agent, NLP, multimodal, audio, and vision examples in the docs/examples folder.
Serving agents
Avalan agents can be exposed over three open protocols: OpenAI-compatible REST endpoints (supporting completions and streaming responses), Model Context Protocol (MCP), and Agent to Agent (A2A) as first-class tools. They are provided by the same avalan agent serve process so you can pick what fits your stack today and evolve without lock-in.
[!TIP] Add one or more
--protocolflags (for example--protocol openai) when runningavalan agent serveto restrict the interfaces you expose without changing your configuration.
All three interfaces support real-time reasoning plus token and tool streaming, letting you observe thoughts, tokens, tool calls, and intermediate results as they happen.
OpenAI completion and responses API
Serve your agents on an OpenAI API–compatible endpoint:
avalan agent serve docs/examples/agent_tool.toml -vvv
[!NOTE] Avalan's OpenAI-compatible endpoint supports both the legacy completions API and the newer Responses API.
Agents listen on port 9001 by default.
[!TIP] Use
--portto serve the agent on a different port.
Or build an agent from inline settings and expose its OpenAI API endpoints:
avalan agent serve \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--tool "math.calculator" \
--memory-recent \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--backend mlx \
-vvv
You can call your tool streaming agent's OpenAI-compatible endpoint just like
the real API; simply change --base-url:
echo "What is (4 + 6) and then that result times 5, divided by 2?" | \
avalan model run "ai://openai" --base-url "http://localhost:9001/v1"
[!TIP] Use
--protocol openai:responses,completionto enable both OpenAI Responses and Completions endpoints, or narrow the surface by specifying justresponsesorcompletionafter the colon.
Example: Match a PDF invoice to database records
You can also serve a database-enabled agent and send it a PDF attachment through the same OpenAI-compatible endpoint. This is useful when the agent needs to inspect the document, understand your schema, and look up the matching record in PostgreSQL.
avalan agent serve \
--engine-uri "ai://env:OPENAI_API_KEY@openai/gpt-5.4" \
--reasoning-effort xhigh \
--tool "database" \
--tool-database-dsn "postgresql+asyncpg://root:password@localhost:5432/invoices_demo" \
--developer 'You are a helpful assistant that answers questions using the PostgreSQL database tools. Inspect the schema first, then query precisely. Stay read-only. Imported invoices are in table `invoice_import_items` and the customer account reference is stored in field `account_reference`.' \
--run-max-new-tokens 25000 \
--protocol openai:responses,completion \
--host 127.0.0.1 \
--port 9001 \
-vvv
Now query your agent with a PDF document:
echo "The attached invoice may match a customer record in the database. Find the matching account and return its account reference ID." \
| avalan model run "ai://openai" \
--base-url "http://127.0.0.1:9001/v1" \
--input-file docs/examples/playground/invoice.pdf
Or call the OpenAI Responses endpoint directly with streaming SSE events:
pdf=docs/examples/playground/invoice.pdf
jq -n \
--arg filename "${pdf##*/}" \
--arg data "data:application/pdf;base64,$(base64 < "$pdf" | tr -d '\n')" '
{
input: [{
role: "user",
content: [
{
type: "input_text",
text: "The attached invoice may match a customer record in the database. Find the matching account and return its account reference ID."
},
{
type: "input_file",
filename: $filename,
file_data: $data
}
]
}],
stream: true
}' | curl -N "http://127.0.0.1:9001/v1/responses" \
-H "Content-Type: application/json" \
-d @-
MCP server
Avalan also embeds an HTTP MCP server alongside the OpenAI-compatible
endpoints whenever you run avalan agent serve. It is mounted at /mcp by
default and can be changed with --mcp-prefix.
[!TIP] Use the MCP Inspector and enter your MCP endpoint URL, the value you configured with
--mcp-prefixwhen runningavalan agent serve(default:http://localhost:9001/mcp). ClickConnect, thenList Tools, run the tool that appears (it will match your--mcp-nameand--mcp-description), and observe the streaming notifications and the final response, which includes reasoning and any tool calls with their arguments and results.
You can customize the MCP tool identity with --mcp-name (defaults to run) and --mcp-description when running avalan agent serve.
[!TIP] Use
--protocol mcp(optionally along with other--protocolflags) to expose only the MCP interface when serving your agent.
A2A server
Avalan also embeds an A2A-compatible server alongside the OpenAI-compatible
endpoints whenever you run avalan agent serve. It is mounted at /a2a by
default and can be configured with --a2a-prefix. The A2A surface supports
streaming, including incremental tool calling and intermediate outputs.
[!TIP] Use the a2a inspector and enter your agent card URL, the value you configured with
--a2a-prefixwhen runningavalan agent serve(default:http://localhost:9001/a2a/agent). You can customize the agent identity with--a2a-nameand--a2a-description, then observe the streaming notifications, tool calls, and final responses.
You can customize the A2A agent identity with --a2a-name (defaults to run)
and --a2a-description when running avalan agent serve.
[!TIP] Use
--protocol a2a(optionally combined with other--protocolflags) to expose just the A2A interface for your served agent.
Embedding in existing FastAPI apps
If you already run a FastAPI service, reuse the same OpenAI, MCP, or A2A endpoints without spawning a standalone server. Call avalan.server.register_agent_endpoints during startup to attach the routers and lifecycle management to your application:
from fastapi import FastAPI
from logging import getLogger
from avalan.model.hubs.huggingface import HuggingfaceHub
from avalan.server import register_agent_endpoints
app = FastAPI()
logger = getLogger("my-app")
hub = HuggingfaceHub()
register_agent_endpoints(
app,
hub=hub,
logger=logger,
specs_path="docs/examples/agent_tool.toml",
settings=None,
tool_settings=None,
mcp_prefix="/mcp",
openai_prefix="/v1",
mcp_name="run",
protocols={"openai": {"responses"}},
)
The helper composes with any existing FastAPI lifespan logic, setting up the orchestrator loader only once and wiring the same streaming endpoints that avalan agent serve exposes.
Proxy agents
The command agent proxy serves as a quick way to serve an agent that:
- Wraps a given
--engine-uri. - Enables recent message memory.
- Enables persistent message memory (defaulting to pgsql with pgvector.)
For example, to proxy OpenAI's gpt-4o, do:
avalan agent proxy \
--engine-uri "ai://env:OPENAI_API_KEY@openai/gpt-4o" \
--run-max-new-tokens 1024 \
-v
Like agent serve, the proxy listens on port 9001 by default.
And you can connect to it from another terminal using --base-url:
echo "What is (4 + 6) and then that result times 5, divided by 2?" | \
avalan model run "ai://openai" --base-url "http://localhost:9001/v1"
Documentation & Resources
- docs/examples – runnable scripts and sample agent configurations.
- docs/CLI.md – exhaustive documentation for commands and flags.
- docs/INSTALL.md – platform-specific installation notes.
- docs/ai_uri.md – the guide to engine URIs and backend selection.
- docs/tutorials – longer walkthroughs for advanced workflows.
Community & Support
- Join the Avalan Discord to ask questions, share workflows, and follow release announcements.
- Browse community answers or ask DeepWiki follow-up questions from the README badge at the top of this page.
- For commercial support, email avalan@avalan.ai.
Contributing
We welcome pull requests, issue reports, docs improvements, and new examples.
- Read the Code of Conduct before you start.
- Install the development environment with
poetry install --all-extras --with test. - Run
make lint. - Run
poetry run pytest --verbose -s.
Open a GitHub issue if you discover bugs or want to propose larger changes.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file avalan-1.4.1.tar.gz.
File metadata
- Download URL: avalan-1.4.1.tar.gz
- Upload date:
- Size: 259.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.3.4 CPython/3.14.4 Darwin/25.3.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d8c8756bb9dbaba9aa3b26620fb11de08bf9d71de2740914fea3d9bbe3856615
|
|
| MD5 |
0c75db0f03c90b36ef912b7b125bf4ad
|
|
| BLAKE2b-256 |
14b2075d312935a8cddf364db31f48e97f37bf141d9126a90cbf408fa492e51c
|
File details
Details for the file avalan-1.4.1-py3-none-any.whl.
File metadata
- Download URL: avalan-1.4.1-py3-none-any.whl
- Upload date:
- Size: 317.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.3.4 CPython/3.14.4 Darwin/25.3.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d1b1b884cb03accba9eb5b5a7af51e26482440a958c75369c033cde423400c6b
|
|
| MD5 |
20c29d631b23993d3bd1ac6c718983a0
|
|
| BLAKE2b-256 |
1e2aa21ce9f3681222dbcabc14b09d5bb2dd25bc8c220d35e21fd7afb466248a
|







