GPU-accelerated Batched Orthogonal Matching Pursuit — up to 310x faster than scikit-learn
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Batched OMP: Fast Orthogonal Matching Pursuit for CPU and GPU
Paper: Efficient Batched CPU/GPU Implementation of Orthogonal Matching Pursuit for Python
Batched implementation of Orthogonal Matching Pursuit (OMP) using BLAS (CPU) and PyTorch (GPU). The fastest GPU implementation of OMP — up to 26x faster than SPAMS (C++) while being pure Python/PyTorch. Up to 310x faster than scikit-learn on GPU.
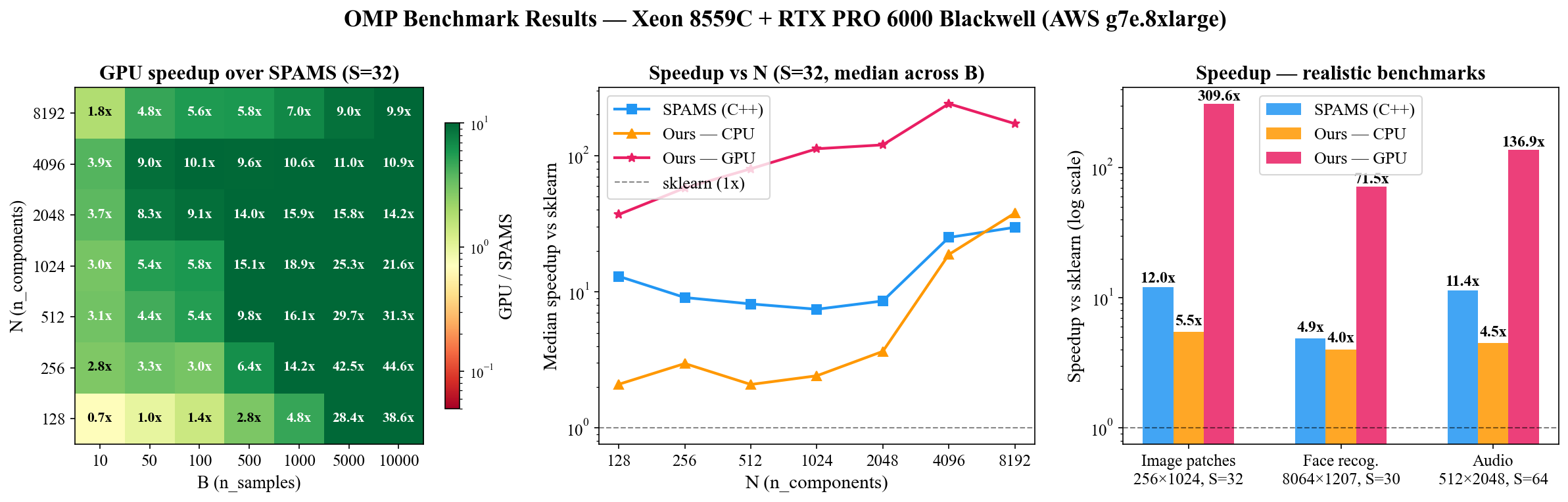
Speedup vs scikit-learn
| Config | Best CPU | GPU | SPAMS (C++) | GPU vs SPAMS |
|---|---|---|---|---|
| Image patches (256×1024, S=32, B=5K) | 5.5x | 310x | 12.0x | 25.8x faster |
| Face recognition (8064×1207, S=30, B=1.2K) | 4.9x† | 71x | 4.9x | 14.6x faster |
| Audio (512×2048, S=64, B=5K) | 4.5x | 137x | 11.4x | 12.0x faster |
† v0_blas (inverse Cholesky + Cython BLAS) wins on CPU for face recognition due to large n_features (8064).
Hardware: Intel Xeon 8559C, NVIDIA RTX PRO 6000 Blackwell 102 GB (AWS g7e.8xlarge)
There is no other production-ready GPU implementation of OMP. Existing alternatives either crash on overcomplete dictionaries (cr-sparse) or are CPU-only (sklearn, SPAMS). Batched OMP is the fastest OMP implementation available when you have a GPU.
When to use batched-omp
- Have a GPU? Use batched-omp — there is nothing faster. 12-26x faster than SPAMS (C++) across all realistic configs
- CPU only, want a sklearn drop-in? 4-5x faster, same API, no C dependencies
- CPU only, maximum speed? SPAMS is faster (C++ with OpenMP) but harder to install and requires Python ≤3.11 (depends on deprecated
numpy.distutils) - Few signals or small problems? sklearn is fine — batching helps most with hundreds+ of signals
Installation
pip install batched-omp
Requires Python 3.10+ and a C compiler (for Cython BLAS extensions). Installs PyTorch automatically.
For GPU support, install PyTorch with CUDA before installing batched-omp, or it will default to CPU-only PyTorch.
For development:
pip install -e ".[dev]"
Quick Start
from batched_omp import run_omp
import torch
# Dictionary X: (n_features, n_components), signals y: (n_samples, n_features)
X = torch.randn(256, 1024, dtype=torch.float64)
X /= X.norm(dim=0) # normalize columns
y = torch.randn(5000, 256, dtype=torch.float64)
# Solve: find 32-sparse representations of y in dictionary X
coefs = run_omp(X, y, n_nonzero_coefs=32, normalize=False, fit_intercept=False)
# coefs: (5000, 1024) — sparse coefficient matrix
GPU — just move tensors to CUDA:
coefs_gpu = run_omp(X.cuda(), y.cuda(), n_nonzero_coefs=32,
normalize=False, fit_intercept=False)
NumPy arrays work too — they're converted to tensors internally:
coefs = run_omp(X_numpy, y_numpy, n_nonzero_coefs=32)
Drop-in sklearn Replacement
Swap one import and get automatic GPU acceleration — works with Pipeline, GridSearchCV, cross_val_score:
# Before (sklearn, CPU only):
from sklearn.linear_model import OrthogonalMatchingPursuit
omp = OrthogonalMatchingPursuit(n_nonzero_coefs=10)
# After (batched-omp, automatic GPU):
from batched_omp import BatchedOrthogonalMatchingPursuit
omp = BatchedOrthogonalMatchingPursuit(n_nonzero_coefs=10)
# Same API
omp.fit(X_train, y_train)
predictions = omp.predict(X_test)
coef = omp.coef_ # (n_features,) or (n_targets, n_features)
intercept = omp.intercept_ # float or (n_targets,)
Extra parameters beyond sklearn's API: device ("auto", "cpu", "cuda"), algorithm ("v0", "v0_blas"), normalize (default True).
API
run_omp(X, y, n_nonzero_coefs, precompute=True, tol=0.0,
normalize=True, fit_intercept=True, alg='v0')
| Parameter | Description |
|---|---|
X |
Dictionary matrix (n_features, n_components). Tensor or ndarray. |
y |
Signal matrix (n_samples, n_features). Tensor or ndarray. |
n_nonzero_coefs |
Maximum number of non-zero coefficients per sample. |
tol |
Residual norm threshold for early stopping. 0 disables. |
normalize |
Column-normalize X before solving (undo on output). |
fit_intercept |
Center X and y before solving. |
alg |
'v0' (default, inverse Cholesky — fastest) or 'v0_blas' (CPU-only, Cython BLAS). |
Returns a (n_samples, n_components) tensor of sparse coefficients.
Algorithms
All algorithms are batched — they solve B sparse coding problems in parallel using matrix operations instead of looping over samples.
| Algorithm | Description | Best for |
|---|---|---|
| v0 (inverse Cholesky) | Updates the Cholesky inverse iteratively, avoiding a linear solve each iteration. Based on Zhu et al. 2020. | GPU (any size), CPU (small-medium n_features) |
| v0_blas | Cython BLAS variant of v0. Calls dgemv/daxpy/idamax directly via scipy. |
CPU with large n_features (e.g. 8064) |
Project Structure
src/batched_omp/ — the library (torch + numpy + scipy, no sklearn)
omp.py — run_omp, omp_naive, omp_v0, omp_v0_blas
utils.py — batch_mm, innerp, cholesky_solve, elapsed_timer
blas_kernels/ — Cython BLAS wrappers (daxpy, dgemv, dppsv, idamax)
benchmarks/
benchmarks.py — benchmarking harness with sklearn baseline
plot_results.py — generates the 3-panel figure above
results/ — benchmark outputs and plots
Running Benchmarks
# Realistic configs (image patches, face recognition, audio)
python benchmarks/benchmarks.py all
# Parameter sweep: N x B x S heatmaps (takes ~20 min)
python benchmarks/benchmarks.py sweep
python benchmarks/plot_sweep.py
# Ablation study: isolates contribution of batching, Gram precomputation, inverse Cholesky
python benchmarks/benchmarks.py ablation
python benchmarks/plot_ablation.py
# CPU only
python benchmarks/benchmarks.py image_patches --no-gpu
Ablation results show that batching is the dominant optimization — processing all signals simultaneously provides 4-750x speedup over single-sample loops. Gram precomputation and inverse Cholesky contribute 1-2x each.
Citation
@article{lubonja2024efficient,
title={Efficient batched CPU/GPU implementation of orthogonal matching pursuit for Python},
author={Lubonja, Ariel and Pr{\"a}sius, Sebastian Kazmarek and Tran, Trac Duy},
journal={arXiv preprint arXiv:2407.06434},
year={2024}
}
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file batched_omp-0.1.2.tar.gz.
File metadata
- Download URL: batched_omp-0.1.2.tar.gz
- Upload date:
- Size: 199.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3fa6aa77c5e7997593ae1a9451218768c6fa8442d2503dd7b187f77d76480666
|
|
| MD5 |
4bfc79a09a4539988743109848049263
|
|
| BLAKE2b-256 |
82fd341732e2e576a4937546e0985610d67c482cc4b6822d222db29a4ae5b53c
|
Provenance
The following attestation bundles were made for batched_omp-0.1.2.tar.gz:
Publisher:
publish.yml on ariellubonja/orthogonal-matching-pursuit-gpu
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
batched_omp-0.1.2.tar.gz -
Subject digest:
3fa6aa77c5e7997593ae1a9451218768c6fa8442d2503dd7b187f77d76480666 - Sigstore transparency entry: 1195198533
- Sigstore integration time:
-
Permalink:
ariellubonja/orthogonal-matching-pursuit-gpu@e28895f01da6236e596e9fbf1928c18c5a259c26 -
Branch / Tag:
refs/tags/v0.1.2 - Owner: https://github.com/ariellubonja
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@e28895f01da6236e596e9fbf1928c18c5a259c26 -
Trigger Event:
release
-
Statement type:







